DroneVLA: VLA based Aerial Manipulation
作者: Fawad Mehboob, Monijesu James, Amir Habel, Jeffrin Sam, Miguel Altamirano Cabrera, Dzmitry Tsetserukou
分类: cs.RO, cs.AI
发布日期: 2026-01-20 (更新: 2026-01-21)
备注: This paper has been accepted for publication at LBR of HRI 2026 conference
💡 一句话要点
提出基于VLA的无人机空中操作系统,实现自然语言指令控制下的物体抓取与递送。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无人机 空中操作 自然语言控制 视觉语言动作模型 物体抓取 人机交互 运动规划 Grounding DINO
📋 核心要点
- 现有空中操作平台缺乏直观的交互界面,非专业用户难以自然地控制系统完成复杂任务。
- 该论文提出一种基于视觉-语言-动作(VLA)模型的无人机系统,通过自然语言指令驱动物体抓取和递送。
- 实验结果表明,该系统在定位和导航方面表现良好,验证了VLA在空中操作中的可行性。
📝 摘要(中文)
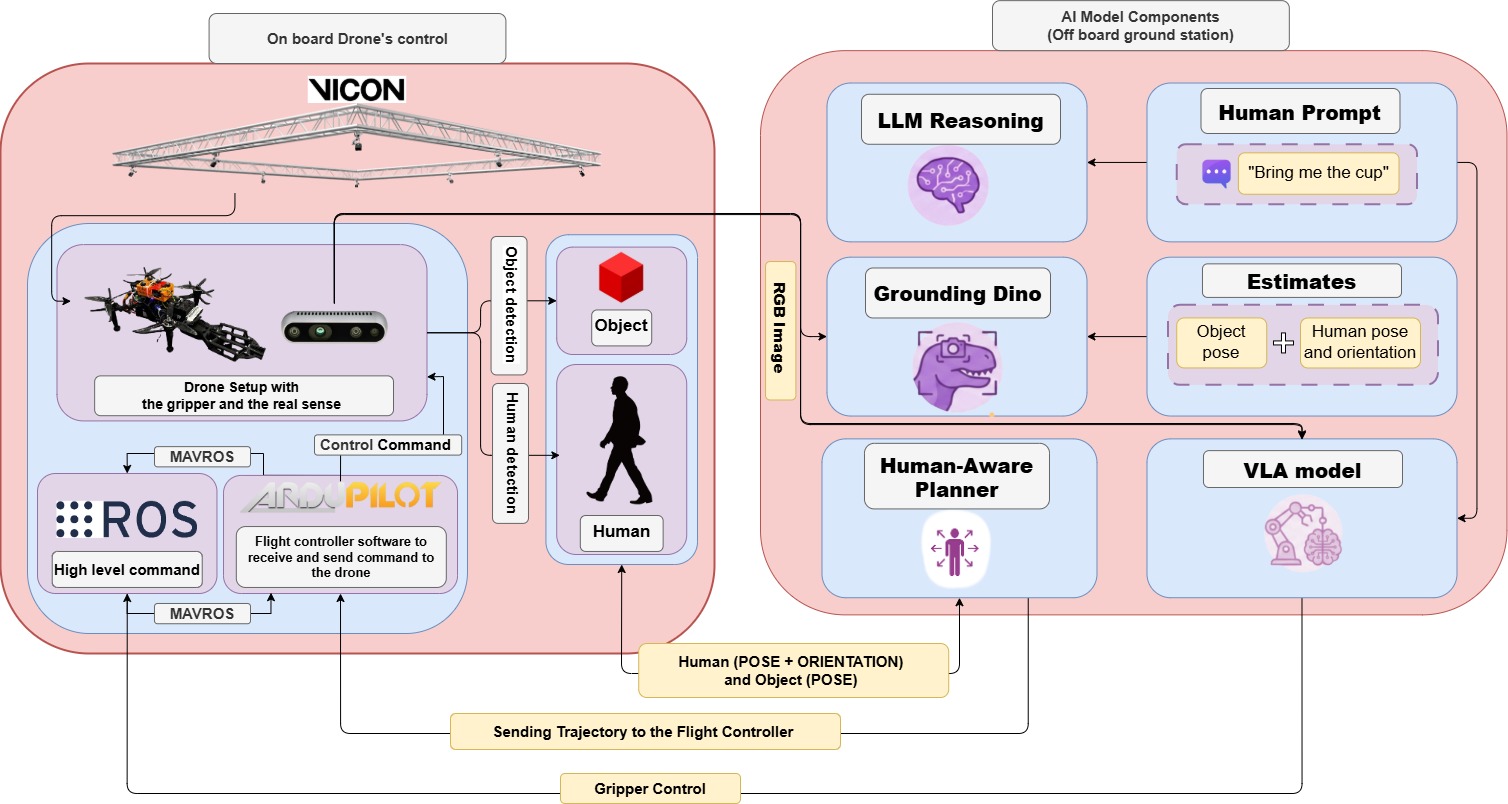
本文提出了一种新颖的自主空中操作系统的概念,该系统能够解释高级自然语言命令,以检索物体并将其递送给人类用户。该系统集成了基于Grounding DINO的MediaPipe和一个视觉-语言-动作(VLA)模型,以及一个配备1自由度夹爪和Intel RealSense RGB-D相机的定制无人机。VLA执行语义推理以解释用户提示的意图,并生成一个优先级的任务队列,用于抓取场景中的相关对象。Grounding DINO和动态A*规划算法用于导航并安全地重新定位物体。为了确保在交接阶段的安全和自然交互,该系统采用了一个以人为中心的控制器,该控制器由MediaPipe驱动。该模块提供实时人体姿态估计,允许无人机采用视觉伺服来保持一个稳定、清晰的位置,直接在用户面前,从而方便舒适的交接。我们通过真实世界的定位和导航实验证明了该系统的有效性,其最大误差、平均欧几里得误差和均方根误差分别为0.164m、0.070m和0.084m,突出了VLA在空中操作中的可行性。
🔬 方法详解
问题定义:现有空中操作平台通常依赖于复杂的遥控或预编程指令,对于非专业用户而言,操作难度大,交互不自然。因此,需要一种更直观、更易于使用的交互方式,使得用户可以通过自然语言指令来控制无人机完成复杂的空中操作任务,例如物体抓取和递送。
核心思路:该论文的核心思路是将自然语言理解、视觉感知和运动规划相结合,构建一个基于视觉-语言-动作(VLA)模型的无人机系统。通过VLA模型,系统能够理解用户输入的自然语言指令,并将其转化为具体的任务队列,指导无人机完成相应的操作。这种方法旨在实现更自然、更直观的人机交互,降低用户的使用门槛。
技术框架:该系统的整体架构包括以下几个主要模块:1) 自然语言理解模块 (VLA):负责解析用户输入的自然语言指令,提取关键信息,并生成一个优先级的任务队列。2) 视觉感知模块 (Grounding DINO & RealSense):利用Grounding DINO进行物体检测和定位,并使用Intel RealSense RGB-D相机获取场景的深度信息。3) 运动规划模块 (Dynamic A*):基于场景信息和任务队列,规划无人机的运动轨迹,确保安全高效地到达目标位置。4) 控制模块 (Human-Centric Controller & MediaPipe):在交接阶段,利用MediaPipe进行人体姿态估计,并使用以人为中心的控制器,使无人机能够保持在用户面前的合适位置,方便交接。
关键创新:该论文的关键创新在于将VLA模型应用于空中操作领域,实现了基于自然语言指令的无人机控制。与传统的遥控或预编程方法相比,这种方法更加直观、灵活,降低了用户的使用门槛。此外,该系统还结合了Grounding DINO和动态A*规划算法,提高了物体检测和运动规划的效率和安全性。
关键设计:VLA模型的具体结构和训练方式未知,论文中未详细描述。Grounding DINO被用作零样本物体检测器,无需针对特定场景进行额外训练。动态A*算法的具体参数设置也未在论文中详细说明。人体姿态估计模块使用MediaPipe,并基于估计结果设计了以人为中心的控制器,以确保交接过程的安全和舒适性。具体控制策略未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该系统在定位和导航方面表现良好,最大误差为0.164m,平均欧几里得误差为0.070m,均方根误差为0.084m。这些数据验证了VLA模型在空中操作中的可行性,并表明该系统具有较高的定位精度和导航能力。虽然论文中没有明确与其他基线方法进行对比,但这些结果为后续研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于物流配送、灾害救援、农业巡检等领域。例如,在物流配送中,用户可以通过自然语言指令控制无人机抓取包裹并送至指定地点;在灾害救援中,救援人员可以通过指令控制无人机搜寻幸存者并运送救援物资。该技术有望提升空中操作的智能化水平,拓展无人机的应用范围。
📄 摘要(原文)
As aerial platforms evolve from passive observers to active manipulators, the challenge shifts toward designing intuitive interfaces that allow non-expert users to command these systems naturally. This work introduces a novel concept of autonomous aerial manipulation system capable of interpreting high-level natural language commands to retrieve objects and deliver them to a human user. The system is intended to integrate a MediaPipe based on Grounding DINO and a Vision-Language-Action (VLA) model with a custom-built drone equipped with a 1-DOF gripper and an Intel RealSense RGB-D camera. VLA performs semantic reasoning to interpret the intent of a user prompt and generates a prioritized task queue for grasping of relevant objects in the scene. Grounding DINO and dynamic A* planning algorithm are used to navigate and safely relocate the object. To ensure safe and natural interaction during the handover phase, the system employs a human-centric controller driven by MediaPipe. This module provides real-time human pose estimation, allowing the drone to employ visual servoing to maintain a stable, distinct position directly in front of the user, facilitating a comfortable handover. We demonstrate the system's efficacy through real-world experiments for localization and navigation, which resulted in a 0.164m, 0.070m, and 0.084m of max, mean euclidean, and root-mean squared errors, respectively, highlighting the feasibility of VLA for aerial manipulation operations.