Communication-Free Collective Navigation for a Swarm of UAVs via LiDAR-Based Deep Reinforcement Learning
作者: Myong-Yol Choi, Hankyoul Ko, Hanse Cho, Changseung Kim, Seunghwan Kim, Jaemin Seo, Hyondong Oh
分类: cs.RO, cs.AI, cs.LG, cs.MA
发布日期: 2026-01-20
💡 一句话要点
提出基于激光雷达和深度强化学习的无人机集群无通信自主导航方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无人机集群 深度强化学习 激光雷达 无通信导航 自主导航
📋 核心要点
- 现有无人机集群导航依赖通信,在通信受限或易受干扰的环境中表现不佳,限制了其应用。
- 提出一种基于激光雷达和深度强化学习的隐式领导者-跟随者框架,无需通信即可实现集群导航。
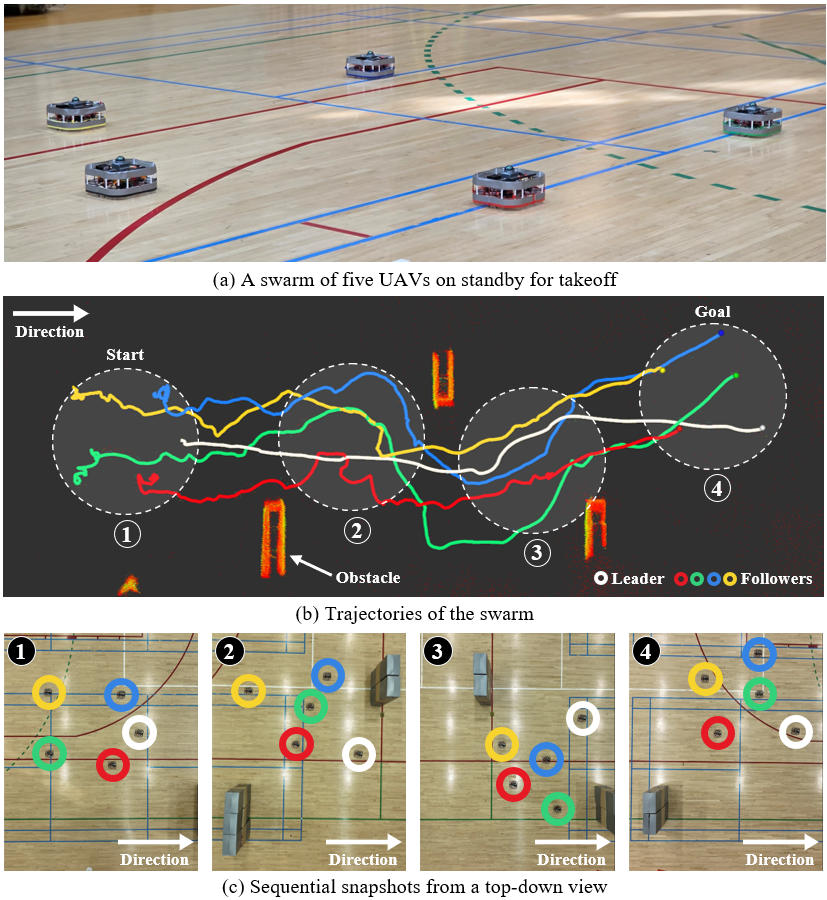
- 通过仿真和真实实验验证了该方法在复杂环境中的鲁棒性和sim-to-real迁移能力,实现了无通信的集群导航。
📝 摘要(中文)
本文提出了一种基于深度强化学习(DRL)的无人机(UAV)集群控制方法,用于在通信受限环境中实现集体导航,从而能够在复杂、障碍物丰富的环境中稳健运行。受生物集群的启发,其中知情的个体引导群体而无需显式通信,我们采用了一种隐式领导者-跟随者框架。在该框架中,只有领导者拥有目标信息,而跟随者无人机仅使用机载激光雷达传感学习鲁棒策略,无需任何智能体间通信或领导者识别。我们的系统利用激光雷达点云聚类和扩展卡尔曼滤波器来实现稳定的邻居跟踪,从而提供独立于外部定位系统的可靠感知。该方法的核心是一个DRL控制器,在GPU加速的Nvidia Isaac Sim中训练,使跟随者能够仅使用局部感知来学习复杂的涌现行为——平衡集群和避障。这使得集群能够隐式地跟随领导者,同时稳健地解决诸如遮挡和有限视场等感知挑战。通过广泛的仿真和具有挑战性的真实世界实验(使用五个无人机的集群),证实了我们方法的鲁棒性和从仿真到现实的迁移能力,成功演示了在没有任何通信或外部定位的情况下,跨越各种室内和室外环境的集体导航。
🔬 方法详解
问题定义:现有无人机集群导航方法通常依赖于智能体之间的通信,这在通信受限或易受干扰的环境中会遇到挑战。此外,依赖外部定位系统也会限制其在未知或GPS信号弱的环境中的应用。因此,如何在没有通信和外部定位的情况下,实现无人机集群在复杂环境中的自主导航是一个关键问题。
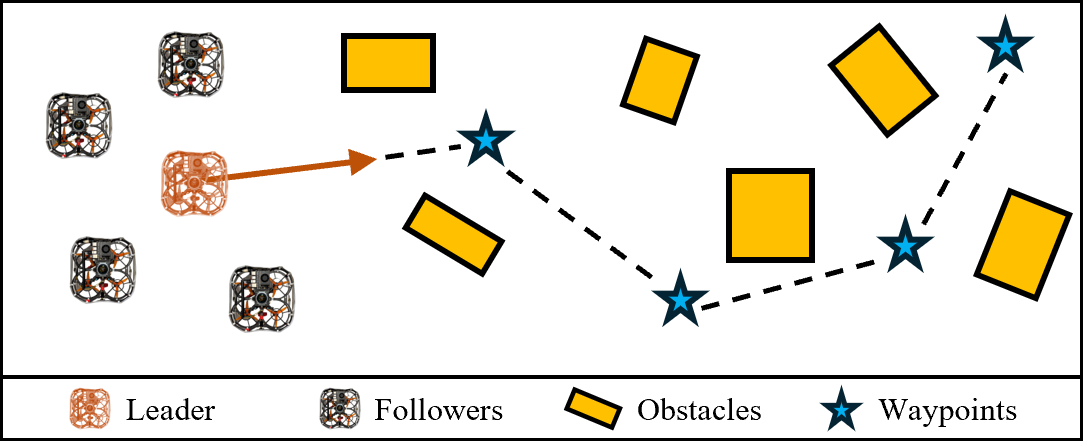
核心思路:本文的核心思路是模仿生物集群行为,采用隐式领导者-跟随者框架。领导者拥有全局目标信息,而跟随者仅依赖于本地激光雷达感知来学习导航策略。通过深度强化学习,跟随者可以学习到复杂的涌现行为,例如集群和避障之间的平衡,从而实现整个集群的协同导航。这种方法避免了显式通信的需求,提高了系统的鲁棒性和适应性。
技术框架:整体框架包括三个主要模块:激光雷达感知、邻居跟踪和深度强化学习控制器。首先,使用激光雷达获取周围环境的点云数据,并通过点云聚类提取邻居无人机的信息。然后,使用扩展卡尔曼滤波器(EKF)对邻居无人机的位置进行跟踪,提供稳定的感知信息。最后,深度强化学习控制器根据本地感知信息生成控制指令,驱动无人机进行导航。整个过程无需智能体之间的通信。
关键创新:该方法最重要的创新点在于将深度强化学习与激光雷达感知相结合,实现了无人机集群在无通信环境下的自主导航。通过隐式领导者-跟随者框架,避免了对显式通信的依赖,提高了系统的鲁棒性。此外,使用扩展卡尔曼滤波器进行邻居跟踪,提高了感知信息的稳定性。
关键设计:在深度强化学习控制器方面,使用了Actor-Critic架构,Actor网络负责生成控制指令,Critic网络负责评估Actor网络的性能。奖励函数的设计至关重要,需要平衡集群、避障和速度等多个目标。具体来说,奖励函数包括与邻居保持适当距离的奖励、避免碰撞的惩罚、以及朝向目标方向移动的奖励。网络结构和超参数的选择也需要仔细调整,以获得最佳的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在仿真和真实环境中均能实现有效的集群导航。在真实实验中,一个由五架无人机组成的集群成功地在室内和室外环境中完成了导航任务,而无需任何通信或外部定位。该方法在复杂环境中的鲁棒性和sim-to-real迁移能力得到了验证。虽然论文中没有给出具体的性能指标提升数据,但实验结果表明该方法是可行的。
🎯 应用场景
该研究成果可应用于多种场景,例如灾难救援、环境监测、农业巡检和物流运输等。在这些场景中,通信基础设施可能受损或不可靠,无人机集群的自主导航能力至关重要。此外,该方法还可以扩展到其他类型的机器人集群,例如地面机器人或水下机器人,具有广泛的应用前景。
📄 摘要(原文)
This paper presents a deep reinforcement learning (DRL) based controller for collective navigation of unmanned aerial vehicle (UAV) swarms in communication-denied environments, enabling robust operation in complex, obstacle-rich environments. Inspired by biological swarms where informed individuals guide groups without explicit communication, we employ an implicit leader-follower framework. In this paradigm, only the leader possesses goal information, while follower UAVs learn robust policies using only onboard LiDAR sensing, without requiring any inter-agent communication or leader identification. Our system utilizes LiDAR point clustering and an extended Kalman filter for stable neighbor tracking, providing reliable perception independent of external positioning systems. The core of our approach is a DRL controller, trained in GPU-accelerated Nvidia Isaac Sim, that enables followers to learn complex emergent behaviors - balancing flocking and obstacle avoidance - using only local perception. This allows the swarm to implicitly follow the leader while robustly addressing perceptual challenges such as occlusion and limited field-of-view. The robustness and sim-to-real transfer of our approach are confirmed through extensive simulations and challenging real-world experiments with a swarm of five UAVs, which successfully demonstrated collective navigation across diverse indoor and outdoor environments without any communication or external localization.