A General One-Shot Multimodal Active Perception Framework for Robotic Manipulation: Learning to Predict Optimal Viewpoint
作者: Deyun Qin, Zezhi Liu, Hanqian Luo, Xiao Liang, Yongchun Fang
分类: cs.RO
发布日期: 2026-01-20
💡 一句话要点
提出一种通用单次多模态主动感知框架,用于机器人操作中的最优视角预测
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 主动感知 机器人操作 多模态融合 最优视角预测 领域随机化
📋 核心要点
- 现有主动感知方法依赖迭代优化,耗时且运动成本高,并与特定任务目标紧密耦合,限制了其泛化能力。
- 本文提出一种单次多模态主动感知框架,通过解耦视角质量评估和利用多模态信息融合,直接预测最优视角。
- 实验表明,该框架显著提高了机器人抓取成功率,并在真实环境中实现了近两倍的提升,且无需额外微调即可实现sim-to-real迁移。
📝 摘要(中文)
本文提出了一种通用的单次多模态主动感知框架,用于机器人操作。该框架旨在直接推断最优观察视角,包含数据收集流程和最优视角预测网络。该框架将视角质量评估与整体架构解耦,支持异构任务需求。通过系统采样和评估候选视角来定义最优视角,并通过领域随机化构建大规模训练数据集。此外,开发了一个多模态最优视角预测网络,利用交叉注意力对齐和融合多模态特征,并直接预测相机姿态调整。该框架在视角受限环境下的机器人抓取中进行了实例化。实验结果表明,由该框架指导的主动感知显著提高了抓取成功率。值得注意的是,真实世界的评估实现了近乎两倍的抓取成功率,并实现了无缝的sim-to-real迁移,无需额外的微调,证明了该框架的有效性。
🔬 方法详解
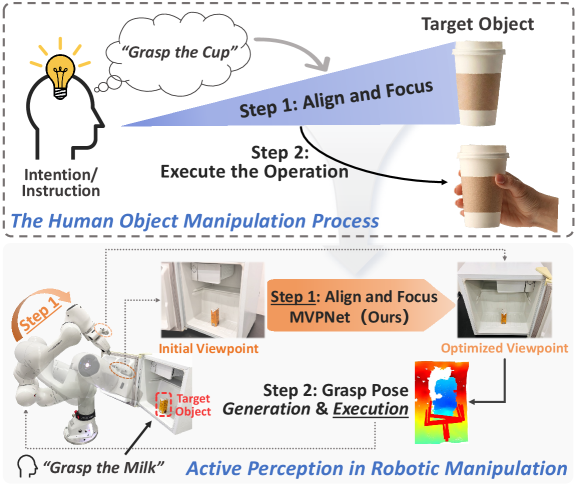
问题定义:论文旨在解决在机器人操作中,如何高效、通用地选择最佳相机视角的问题。现有方法通常依赖于迭代优化,计算成本高昂,并且针对特定任务设计,难以迁移到其他任务中。这些方法没有充分利用多模态信息,例如视觉和深度信息,来指导视角选择。
核心思路:论文的核心思路是将视角选择问题转化为一个单次预测问题,通过训练一个多模态神经网络,直接从场景信息预测最优的相机姿态调整。这种方法避免了迭代优化,提高了效率,并且通过解耦视角质量评估,实现了框架的通用性。利用领域随机化生成大规模数据集,保证了模型在真实环境中的泛化能力。
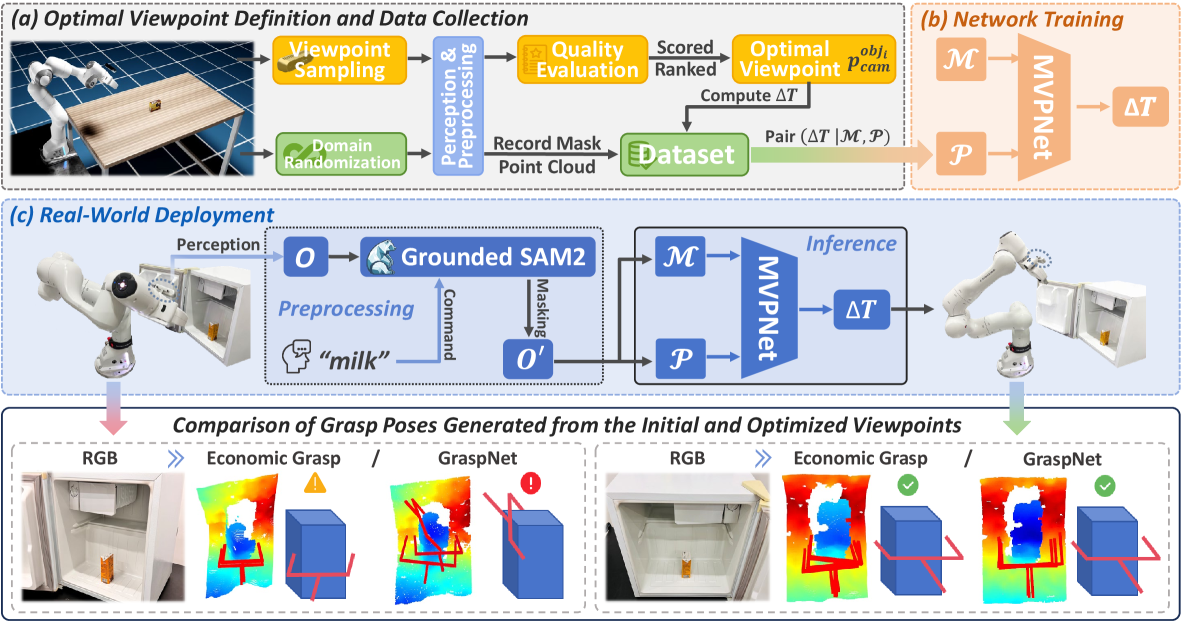
技术框架:该框架包含两个主要部分:数据收集流程和最优视角预测网络。数据收集流程通过系统采样和评估候选视角来定义最优视角,并利用领域随机化生成大规模训练数据集。最优视角预测网络是一个多模态网络,它接收来自不同传感器的输入(例如RGB图像和深度图像),并预测相机姿态的调整量。整个流程是端到端的,可以直接从场景信息预测最优视角。
关键创新:该论文的关键创新在于提出了一种通用的单次多模态主动感知框架。与现有方法相比,该框架具有以下优势:1) 单次预测,避免了迭代优化,提高了效率;2) 多模态融合,利用了多种传感器信息,提高了视角选择的准确性;3) 解耦视角质量评估,实现了框架的通用性;4) 领域随机化,保证了模型在真实环境中的泛化能力。
关键设计:最优视角预测网络使用了交叉注意力机制来对齐和融合多模态特征。具体来说,网络首先提取RGB图像和深度图像的特征,然后使用交叉注意力模块来计算不同模态特征之间的相关性,并将这些特征融合在一起。最终,网络预测相机姿态的调整量,例如平移和旋转。损失函数的设计旨在最小化预测姿态与最优姿态之间的差异。领域随机化策略包括随机改变场景的光照、纹理、物体位置等,以增加训练数据的多样性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该框架在机器人抓取任务中取得了显著的性能提升。在真实世界的评估中,该框架实现了近乎两倍的抓取成功率,并且无需额外的微调即可实现sim-to-real迁移。这表明该框架具有很强的泛化能力和实用价值。与现有的基于迭代优化的方法相比,该框架的效率更高,并且更易于部署。
🎯 应用场景
该研究成果可广泛应用于机器人操作领域,例如机器人抓取、装配、检测等。通过主动选择最佳视角,机器人可以获得更清晰、更全面的场景信息,从而提高操作的成功率和效率。该框架还可应用于自动驾驶、增强现实等领域,为这些应用提供更好的感知能力。未来,该研究可以扩展到更复杂的任务和环境,例如在拥挤的场景中进行操作,或者在光照条件恶劣的环境中进行感知。
📄 摘要(原文)
Active perception in vision-based robotic manipulation aims to move the camera toward more informative observation viewpoints, thereby providing high-quality perceptual inputs for downstream tasks. Most existing active perception methods rely on iterative optimization, leading to high time and motion costs, and are tightly coupled with task-specific objectives, which limits their transferability. In this paper, we propose a general one-shot multimodal active perception framework for robotic manipulation. The framework enables direct inference of optimal viewpoints and comprises a data collection pipeline and an optimal viewpoint prediction network. Specifically, the framework decouples viewpoint quality evaluation from the overall architecture, supporting heterogeneous task requirements. Optimal viewpoints are defined through systematic sampling and evaluation of candidate viewpoints, after which large-scale training datasets are constructed via domain randomization. Moreover, a multimodal optimal viewpoint prediction network is developed, leveraging cross-attention to align and fuse multimodal features and directly predict camera pose adjustments. The proposed framework is instantiated in robotic grasping under viewpoint-constrained environments. Experimental results demonstrate that active perception guided by the framework significantly improves grasp success rates. Notably, real-world evaluations achieve nearly double the grasp success rate and enable seamless sim-to-real transfer without additional fine-tuning, demonstrating the effectiveness of the proposed framework.