LogicEnvGen: Task-Logic Driven Generation of Diverse Simulated Environments for Embodied AI
作者: Jianan Wang, Siyang Zhang, Bin Li, Juan Chen, Jingtao Qi, Zhuo Zhang, Chen Qian
分类: cs.RO
发布日期: 2026-01-20
备注: 19 pages, 15 figures, 6 tables
💡 一句话要点
LogicEnvGen:提出任务逻辑驱动的环境生成方法,提升具身智能体测试多样性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 环境生成 逻辑多样性 大型语言模型 任务规划
📋 核心要点
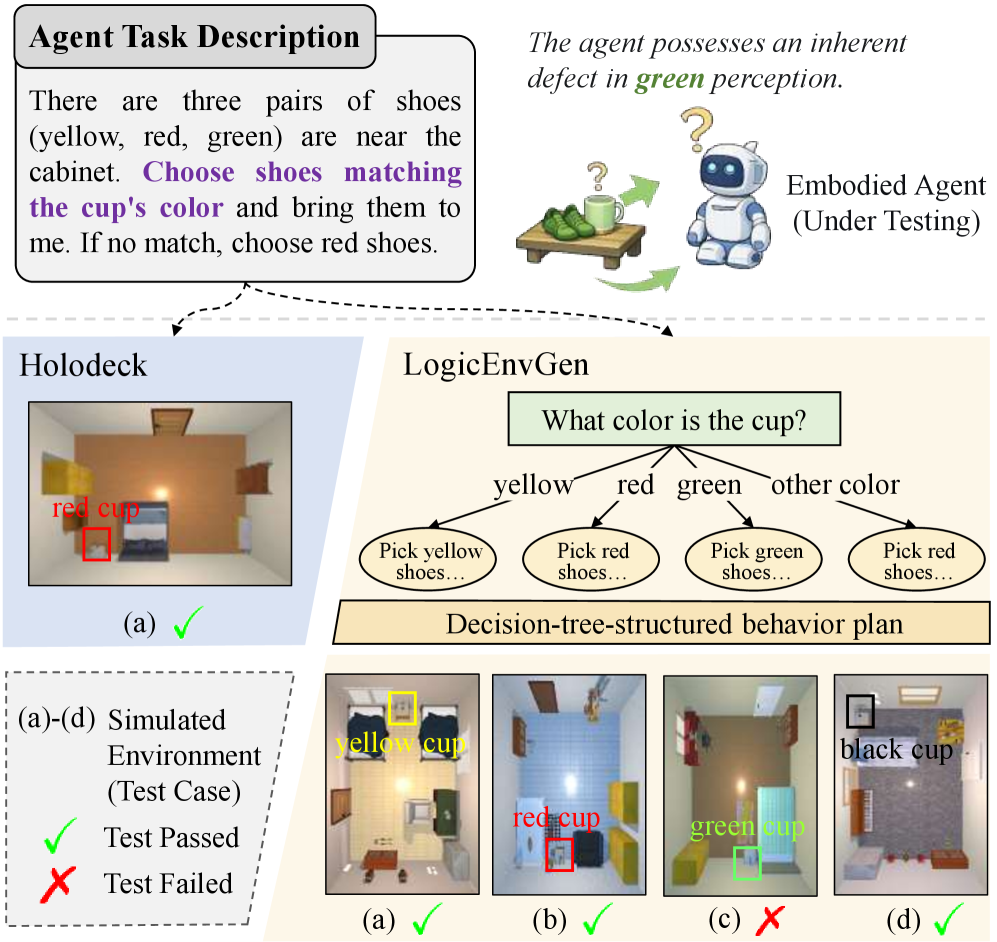
- 现有环境生成方法侧重视觉真实性,忽略了逻辑多样性,限制了智能体适应性和规划能力的全面评估。
- LogicEnvGen利用大型语言模型,自顶向下生成逻辑多样化的模拟环境,作为智能体的测试用例。
- 实验表明,LogicEnvGen显著提高了环境的逻辑多样性,并提升了智能体故障检测能力。
📝 摘要(中文)
模拟环境在具身智能中扮演着至关重要的角色,类似于软件工程中的测试用例。然而,现有的环境生成方法通常侧重于视觉真实性(例如,对象多样性和布局连贯性),而忽略了一个关键方面:从测试角度来看的逻辑多样性。这限制了在不同模拟环境中对智能体适应性和规划鲁棒性的全面评估。为了弥补这一差距,我们提出了一种由大型语言模型(LLM)驱动的新方法LogicEnvGen,该方法采用自顶向下的范例来生成逻辑上多样化的模拟环境,作为智能体的测试用例。给定一个智能体任务,LogicEnvGen首先分析其执行逻辑以构建决策树结构的行动计划,然后合成一组逻辑轨迹。随后,它采用一种启发式算法来细化轨迹集,减少冗余模拟。对于每个逻辑轨迹(代表潜在的任务情境),LogicEnvGen相应地实例化一个具体的环境。值得注意的是,它采用约束求解来实现物理合理性。此外,我们引入了LogicEnvEval,这是一个包含四个定量指标的新型环境评估基准。实验结果验证了基线方法缺乏逻辑多样性,并表明LogicEnvGen实现了1.04-2.61倍的更高多样性,显著提高了4.00%-68.00%的智能体故障揭示性能。
🔬 方法详解
问题定义:现有具身智能模拟环境生成方法主要关注视觉真实性,例如物体种类和布局合理性,忽略了环境在逻辑上的多样性。这意味着智能体在这些环境中训练和测试时,可能无法充分暴露其在复杂逻辑推理和规划方面的缺陷。因此,需要一种能够生成逻辑多样化环境的方法,以更全面地评估智能体的能力。
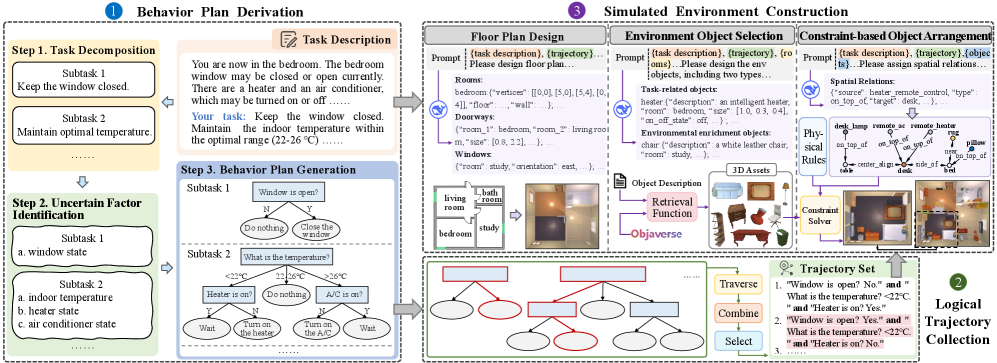
核心思路:LogicEnvGen的核心思路是利用大型语言模型(LLM)理解任务逻辑,并将其转化为一系列逻辑轨迹。每个逻辑轨迹代表一种可能的任务执行路径,然后基于这些轨迹生成相应的模拟环境。通过确保轨迹的多样性,可以生成逻辑上多样化的环境,从而更有效地测试智能体的能力。
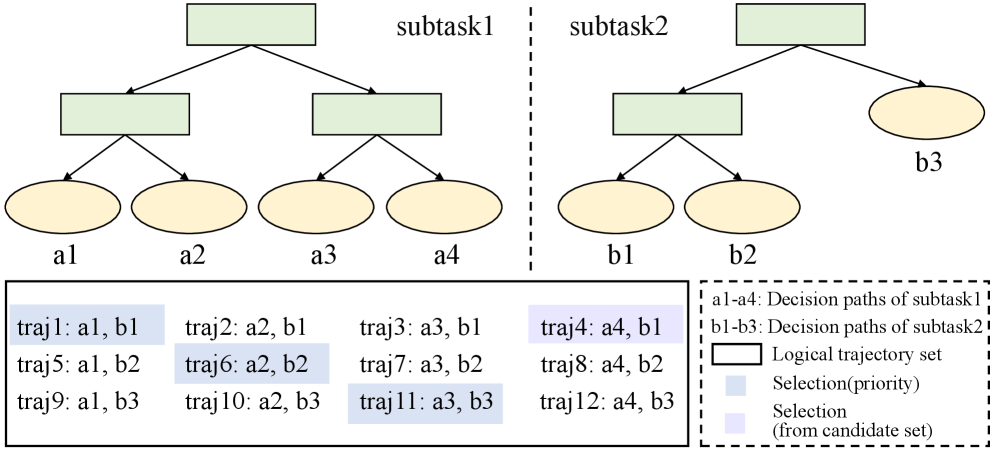
技术框架:LogicEnvGen包含以下主要模块:1) 行为计划生成:使用LLM分析任务,生成决策树结构的行动计划。2) 逻辑轨迹合成:基于行动计划,合成一组逻辑轨迹,每条轨迹代表一种可能的任务执行路径。3) 轨迹优化:使用启发式算法减少轨迹集合中的冗余,提高效率。4) 环境实例化:根据每条逻辑轨迹,实例化一个具体的模拟环境,并使用约束求解保证物理合理性。5) 环境评估:使用LogicEnvEval基准评估生成环境的质量。
关键创新:LogicEnvGen的关键创新在于其任务逻辑驱动的环境生成方法。与以往侧重视觉真实性的方法不同,LogicEnvGen直接从任务逻辑出发,生成逻辑多样化的环境。此外,利用LLM进行行为计划生成和逻辑轨迹合成,可以有效地捕捉任务的复杂逻辑。
关键设计:LogicEnvGen使用LLM(具体型号未知)进行行为计划生成,并采用决策树结构表示行动计划。轨迹优化采用启发式算法,具体算法细节未知。环境实例化过程中,使用约束求解器(具体类型未知)保证物理合理性。LogicEnvEval基准包含四个定量指标,具体指标内容未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LogicEnvGen生成的环境在逻辑多样性方面比基线方法高出1.04-2.61倍。此外,使用LogicEnvGen生成的环境进行测试,能够显著提高智能体故障的揭示率,提升幅度达到4.00%-68.00%。这些结果验证了LogicEnvGen在生成高质量测试环境方面的有效性。
🎯 应用场景
LogicEnvGen可应用于各种具身智能任务的模拟环境生成,例如机器人导航、操作和交互。通过生成逻辑多样化的环境,可以更全面地测试和评估智能体的能力,提高其在真实世界中的鲁棒性和可靠性。该方法还有助于开发更安全、更可靠的机器人系统。
📄 摘要(原文)
Simulated environments play an essential role in embodied AI, functionally analogous to test cases in software engineering. However, existing environment generation methods often emphasize visual realism (e.g., object diversity and layout coherence), overlooking a crucial aspect: logical diversity from the testing perspective. This limits the comprehensive evaluation of agent adaptability and planning robustness in distinct simulated environments. To bridge this gap, we propose LogicEnvGen, a novel method driven by Large Language Models (LLMs) that adopts a top-down paradigm to generate logically diverse simulated environments as test cases for agents. Given an agent task, LogicEnvGen first analyzes its execution logic to construct decision-tree-structured behavior plans and then synthesizes a set of logical trajectories. Subsequently, it adopts a heuristic algorithm to refine the trajectory set, reducing redundant simulation. For each logical trajectory, which represents a potential task situation, LogicEnvGen correspondingly instantiates a concrete environment. Notably, it employs constraint solving for physical plausibility. Furthermore, we introduce LogicEnvEval, a novel benchmark comprising four quantitative metrics for environment evaluation. Experimental results verify the lack of logical diversity in baselines and demonstrate that LogicEnvGen achieves 1.04-2.61x greater diversity, significantly improving the performance in revealing agent faults by 4.00%-68.00%.