Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization
作者: Hao Luo, Ye Wang, Wanpeng Zhang, Sipeng Zheng, Ziheng Xi, Chaoyi Xu, Haiweng Xu, Haoqi Yuan, Chi Zhang, Yiqing Wang, Yicheng Feng, Zongqing Lu
分类: cs.RO
发布日期: 2026-01-19
备注: 44 pages
💡 一句话要点
Being-H0.5:通过人类中心机器人学习实现跨具身泛化
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 跨具身泛化 视觉-语言-动作模型 人类中心学习 多模态预训练
📋 核心要点
- 现有VLA模型在机器人形态各异和数据稀缺的情况下,难以实现有效的跨具身泛化。
- 论文提出以人为中心的学习范式,将人类交互数据作为通用“母语”,促进机器人技能学习和迁移。
- Being-H0.5在模拟和真实机器人实验中均表现出色,在LIBERO和RoboCasa等基准上取得SOTA结果。
📝 摘要(中文)
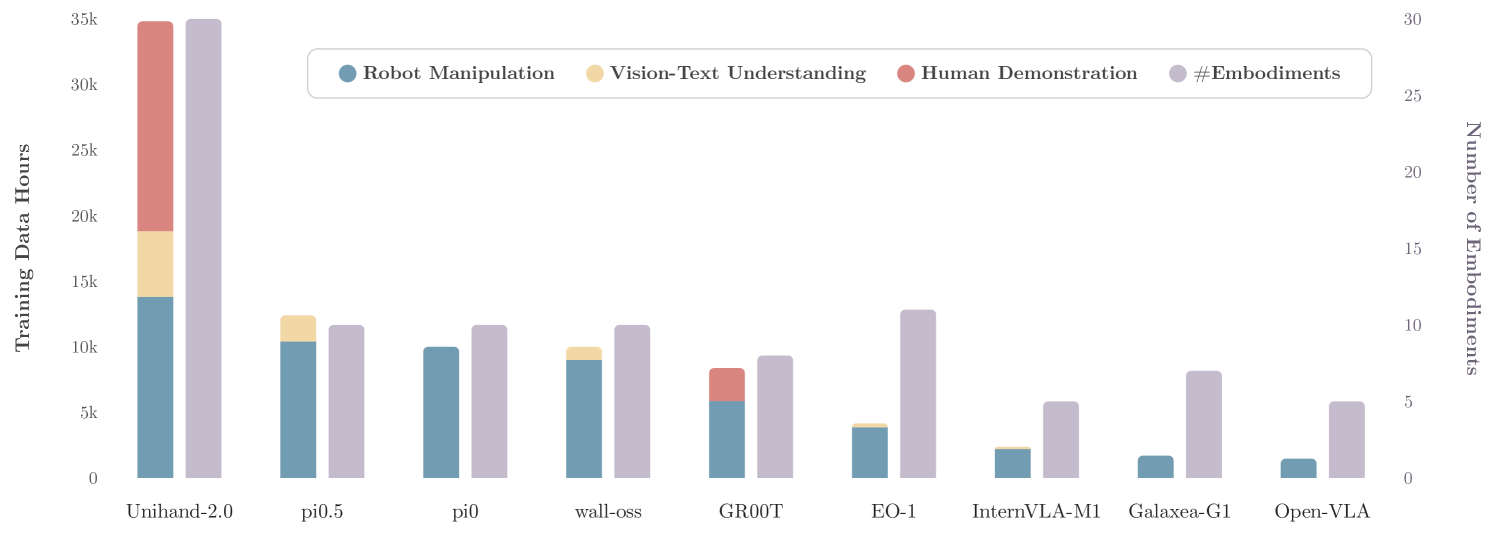
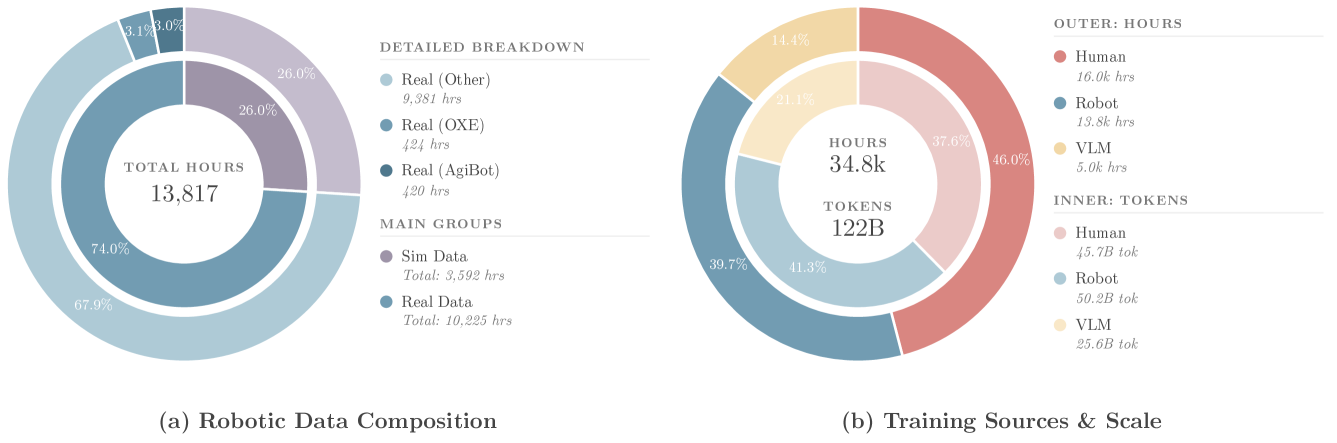
本文提出了Being-H0.5,一个基础的视觉-语言-动作(VLA)模型,旨在实现跨不同机器人平台的鲁棒跨具身泛化。现有VLA模型通常在形态异构性和数据稀缺性方面表现不佳,因此我们提出了一种以人为中心的学习范式,将人类交互轨迹视为物理交互的通用“母语”。为此,我们提出了UniHand-2.0,迄今为止最大的具身预训练方案,包含超过35,000小时的跨30种不同机器人具身的多模态数据。我们的方法引入了一个统一动作空间,将异构机器人控制映射到语义对齐的槽位,使低资源机器人能够从人类数据和高资源平台引导技能。基于这种以人为中心的foundation,我们设计了一个统一的序列建模和多任务预训练范式,以桥接人类演示和机器人执行。在架构上,Being-H0.5采用了一种混合Transformer设计,其特点是新颖的混合流(MoF)框架,用于将共享运动原语与专门的具身特定专家分离。最后,为了使跨具身策略在现实世界中保持稳定,我们引入了流形保持门控,以提高在感觉变化下的鲁棒性,以及通用异步分块,以在具有不同延迟和控制配置文件的具身之间通用化分块控制。我们通过实验证明,Being-H0.5在模拟基准测试(如LIBERO(98.9%)和RoboCasa(53.9%))上取得了最先进的结果,同时在五个机器人平台上也表现出强大的跨具身能力。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在面对形态各异的机器人平台时,难以实现有效的跨具身泛化。主要痛点在于不同机器人控制方式的异构性以及训练数据的稀缺性,导致模型难以学习通用的物理交互技能。
核心思路:论文的核心思路是将人类交互数据作为机器人学习的桥梁,视其为一种通用的“母语”。通过学习人类的交互方式,机器人可以更好地理解物理世界的规律,从而更容易地将学到的技能迁移到不同的机器人平台上。这种以人为中心的学习范式旨在克服数据稀缺性和形态异构性带来的挑战。
技术框架:Being-H0.5的整体框架包括数据收集与预处理、统一动作空间设计、序列建模与多任务预训练以及模型架构设计四个主要部分。首先,通过UniHand-2.0收集大规模的人类交互数据。然后,设计统一动作空间,将不同机器人的控制信号映射到语义对齐的槽位。接着,采用序列建模和多任务预训练方法,将人类演示和机器人执行联系起来。最后,采用混合Transformer架构,并引入混合流(MoF)框架,以解耦共享运动原语和具身特定专家。
关键创新:论文的关键创新点在于以下几个方面:1) 提出以人为中心的机器人学习范式,将人类交互数据作为通用“母语”;2) 设计了统一动作空间,实现了异构机器人控制信号的语义对齐;3) 引入混合流(MoF)框架,解耦了共享运动原语和具身特定专家;4) 提出了流形保持门控和通用异步分块,提高了模型在真实世界中的鲁棒性和泛化能力。与现有方法相比,Being-H0.5更注重利用人类知识来指导机器人学习,从而更好地解决跨具身泛化问题。
关键设计:UniHand-2.0包含超过35,000小时的多模态数据。统一动作空间通过语义对齐的槽位进行映射。混合Transformer架构采用MoF框架,将共享运动原语和具身特定专家分离。流形保持门控用于提高模型在感觉变化下的鲁棒性。通用异步分块用于在具有不同延迟和控制配置文件的具身之间通用化分块控制。
🖼️ 关键图片

📊 实验亮点
Being-H0.5在模拟基准测试中取得了显著的性能提升。在LIBERO数据集上,Being-H0.5的成功率达到了98.9%,在RoboCasa数据集上,成功率达到了53.9%。此外,Being-H0.5还在五个不同的机器人平台上展示了强大的跨具身能力,验证了其在真实世界中的泛化性能。这些实验结果表明,Being-H0.5在跨具身机器人学习方面具有显著优势。
🎯 应用场景
Being-H0.5具有广泛的应用前景,可用于开发更智能、更灵活的机器人系统。例如,它可以应用于家庭服务机器人,使其能够完成各种家务任务;也可以应用于工业机器人,使其能够适应不同的生产环境和任务需求;还可以应用于医疗机器人,使其能够辅助医生进行手术和康复治疗。该研究的实际价值在于降低了机器人开发的成本和难度,促进了机器人技术的普及和应用。未来,Being-H0.5有望成为机器人领域的基础模型,推动机器人技术的进一步发展。
📄 摘要(原文)
We introduce Being-H0.5, a foundational Vision-Language-Action (VLA) model designed for robust cross-embodiment generalization across diverse robotic platforms. While existing VLAs often struggle with morphological heterogeneity and data scarcity, we propose a human-centric learning paradigm that treats human interaction traces as a universal "mother tongue" for physical interaction. To support this, we present UniHand-2.0, the largest embodied pre-training recipe to date, comprising over 35,000 hours of multimodal data across 30 distinct robotic embodiments. Our approach introduces a Unified Action Space that maps heterogeneous robot controls into semantically aligned slots, enabling low-resource robots to bootstrap skills from human data and high-resource platforms. Built upon this human-centric foundation, we design a unified sequential modeling and multi-task pre-training paradigm to bridge human demonstrations and robotic execution. Architecturally, Being-H0.5 utilizes a Mixture-of-Transformers design featuring a novel Mixture-of-Flow (MoF) framework to decouple shared motor primitives from specialized embodiment-specific experts. Finally, to make cross-embodiment policies stable in the real world, we introduce Manifold-Preserving Gating for robustness under sensory shift and Universal Async Chunking to universalize chunked control across embodiments with different latency and control profiles. We empirically demonstrate that Being-H0.5 achieves state-of-the-art results on simulated benchmarks, such as LIBERO (98.9%) and RoboCasa (53.9%), while also exhibiting strong cross-embodiment capabilities on five robotic platforms.