The Great March 100: 100 Detail-oriented Tasks for Evaluating Embodied AI Agents
作者: Ziyu Wang, Chenyuan Liu, Yushun Xiang, Runhao Zhang, Qingbo Hao, Hongliang Lu, Houyu Chen, Zhizhong Feng, Kaiyue Zheng, Dehao Ye, Xianchao Zeng, Xinyu Zhou, Boran Wen, Jiaxin Li, Mingyu Zhang, Kecheng Zheng, Qian Zhu, Ran Cheng, Yong-Lu Li
分类: cs.RO, cs.AI
发布日期: 2026-01-16
💡 一句话要点
提出Great March 100 (GM-100),用于全面评估具身智能体的100项细粒度任务
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 机器人学习 任务设计 数据集 长尾行为 人-物交互 物体可供性
📋 核心要点
- 现有机器人学习数据集和任务设计缺乏系统性,难以全面评估机器人代理的能力。
- 提出GM-100,包含100个精心设计的任务,覆盖广泛的交互和长尾行为。
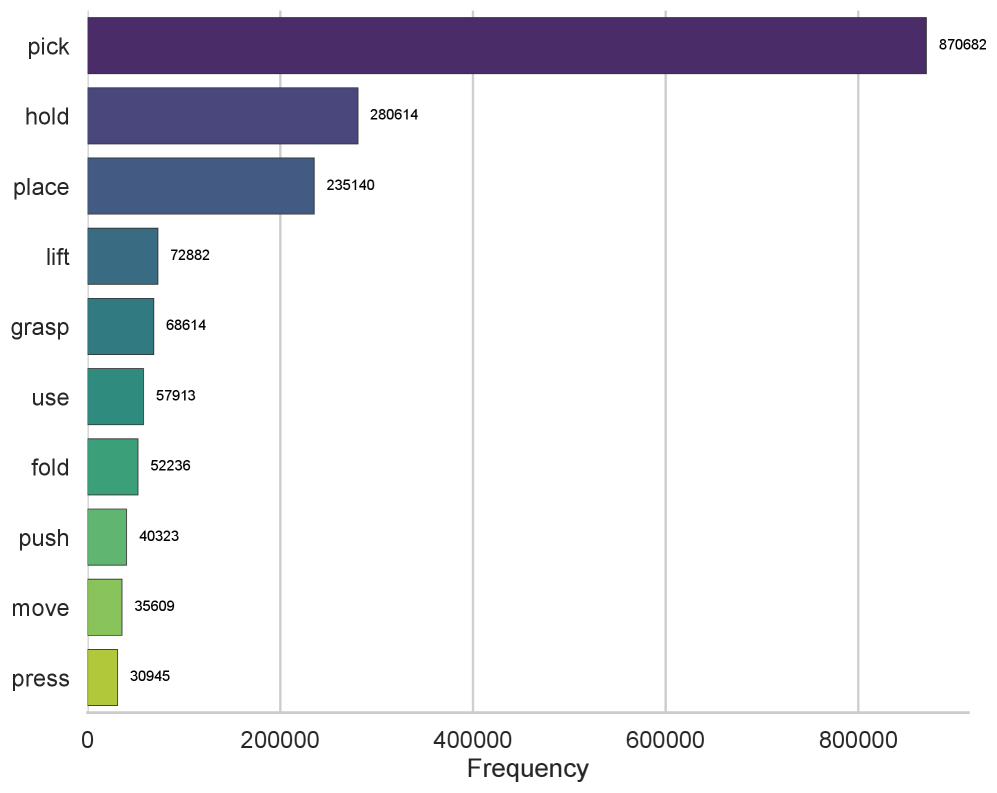
- 实验表明GM-100任务可执行且具有挑战性,能够有效区分现有VLA模型的性能。
📝 摘要(中文)
随着机器人学习和模仿学习的快速发展,涌现了大量数据集和方法。然而,这些数据集及其任务设计常常缺乏系统性的考虑和原则。这引发了重要的问题:当前的数据集和任务设计是否真正提升了机器人代理的能力?在少数常见任务上的评估是否能准确反映不同团队提出的各种方法在不同任务上的差异化表现?为了解决这些问题,我们引入了Great March 100(GM-100),作为迈向机器人学习奥林匹克的第一步。GM-100包含100个精心设计的任务,涵盖了广泛的交互和长尾行为,旨在提供一个多样化和具有挑战性的任务集,以全面评估机器人代理的能力,并促进机器人数据集任务设计的多样性和复杂性。这些任务是通过对现有任务设计的系统分析和扩展,结合人-物交互原语和物体可供性的见解而开发的。我们在不同的机器人平台上收集了大量的轨迹数据,并评估了几个基线模型。实验结果表明,GM-100任务是1)可执行的,并且2)具有足够的挑战性,可以有效地区分当前VLA模型的性能。我们的数据和代码可在https://rhos.ai/research/gm-100获得。
🔬 方法详解
问题定义:现有机器人学习数据集和任务设计缺乏系统性,导致无法全面评估机器人代理的能力,也难以区分不同方法的性能差异。现有任务设计往往集中在少数常见任务上,忽略了长尾行为和复杂交互,限制了机器人学习的进步。
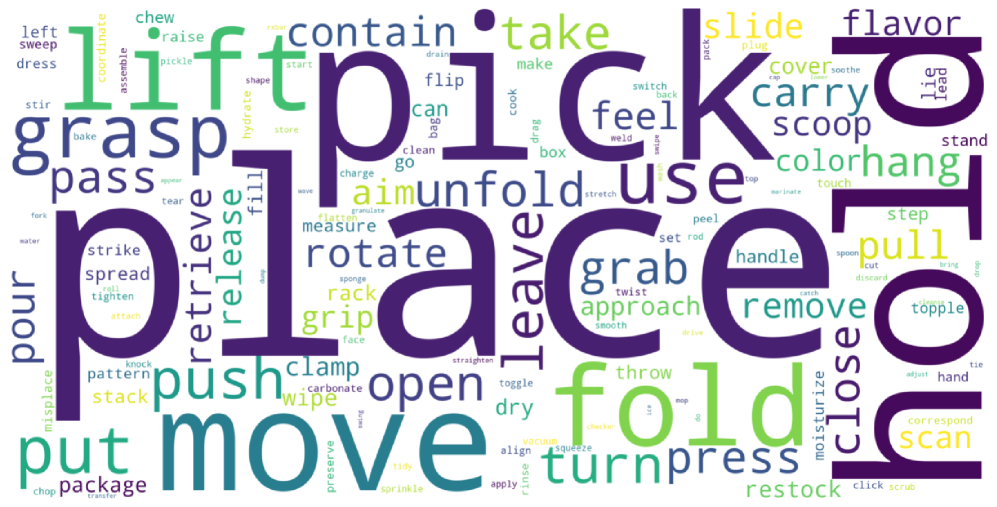
核心思路:GM-100的核心思路是通过构建一个包含100个细粒度、多样化任务的benchmark,来全面评估机器人代理的能力。这些任务的设计基于对现有任务的系统分析和扩展,并结合了人-物交互原语和物体可供性的概念,旨在覆盖更广泛的交互类型和长尾行为。
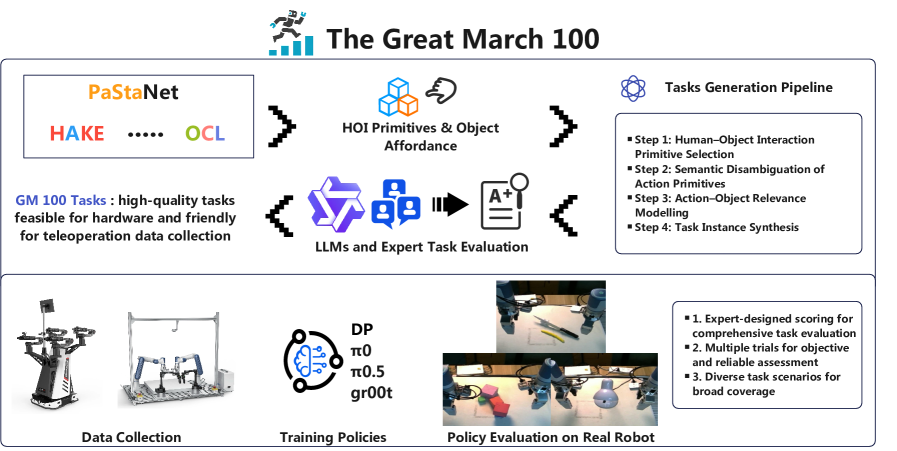
技术框架:GM-100的技术框架主要包括以下几个阶段:1) 任务设计:系统分析现有任务,结合人-物交互原语和物体可供性,设计100个细粒度任务。2) 数据收集:在不同的机器人平台上收集大量轨迹数据,用于训练和评估模型。3) 基线评估:评估多个基线模型在GM-100上的性能,作为后续研究的参考。4) 公开数据集和代码:提供GM-100数据集和代码,方便研究人员使用和扩展。
关键创新:GM-100的关键创新在于其任务设计的全面性和细粒度。与现有数据集相比,GM-100覆盖了更广泛的交互类型和长尾行为,能够更全面地评估机器人代理的能力。此外,GM-100的任务设计基于人-物交互原语和物体可供性,使得任务更具挑战性和实用性。
关键设计:GM-100的任务设计考虑了多种因素,包括任务的难度、多样性、可执行性和可区分性。任务的难度通过调整任务的复杂度和精度要求来控制。任务的多样性通过覆盖不同的交互类型和长尾行为来实现。任务的可执行性通过在不同的机器人平台上进行验证来保证。任务的可区分性通过评估多个基线模型在GM-100上的性能来验证。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GM-100任务是可执行的,并且具有足够的挑战性,可以有效地区分当前VLA模型的性能。通过在不同机器人平台上收集大量轨迹数据,并评估多个基线模型,验证了GM-100的有效性和实用性。该数据集和代码的公开,将促进机器人学习领域的研究和发展。
🎯 应用场景
GM-100可用于评估和比较不同的机器人学习算法,促进机器人学习领域的发展。它还可以用于训练更鲁棒和通用的机器人代理,使其能够适应更广泛的应用场景,例如家庭服务、工业自动化和医疗保健等。GM-100的细粒度任务设计也有助于研究人员深入理解机器人学习的瓶颈和挑战。
📄 摘要(原文)
Recently, with the rapid development of robot learning and imitation learning, numerous datasets and methods have emerged. However, these datasets and their task designs often lack systematic consideration and principles. This raises important questions: Do the current datasets and task designs truly advance the capabilities of robotic agents? Do evaluations on a few common tasks accurately reflect the differentiated performance of various methods proposed by different teams and evaluated on different tasks? To address these issues, we introduce the Great March 100 (\textbf{GM-100}) as the first step towards a robot learning Olympics. GM-100 consists of 100 carefully designed tasks that cover a wide range of interactions and long-tail behaviors, aiming to provide a diverse and challenging set of tasks to comprehensively evaluate the capabilities of robotic agents and promote diversity and complexity in robot dataset task designs. These tasks are developed through systematic analysis and expansion of existing task designs, combined with insights from human-object interaction primitives and object affordances. We collect a large amount of trajectory data on different robotic platforms and evaluate several baseline models. Experimental results demonstrate that the GM-100 tasks are 1) feasible to execute and 2) sufficiently challenging to effectively differentiate the performance of current VLA models. Our data and code are available at https://rhos.ai/research/gm-100.