FastStair: Learning to Run Up Stairs with Humanoid Robots
作者: Yan Liu, Tao Yu, Haolin Song, Hongbo Zhu, Nianzong Hu, Yuzhi Hao, Xiuyong Yao, Xizhe Zang, Hua Chen, Jie Zhao
分类: cs.RO
发布日期: 2026-01-15
💡 一句话要点
FastStair:一种基于规划引导的多阶段学习框架,用于人形机器人快速稳定地攀爬楼梯
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 强化学习 运动规划 楼梯攀爬 多阶段学习 低秩自适应 模型预测控制 机器人控制
📋 核心要点
- 人形机器人攀爬楼梯需要在高敏捷性和稳定性之间取得平衡,现有无模型强化学习方法安全性不足,而基于模型的方法则过于保守。
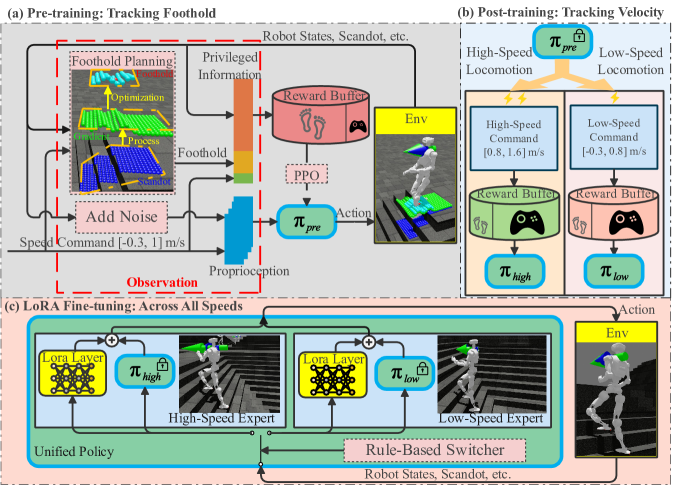
- FastStair框架融合了基于模型的落脚点规划器和强化学习,利用规划器引导探索,并预训练安全策略,再通过LoRA进行速度专家集成。
- 在Oli人形机器人上,FastStair实现了1.65米/秒的稳定爬楼梯速度,并在12秒内完成了33步螺旋楼梯的攀爬,并在比赛中获得冠军。
📝 摘要(中文)
人形机器人攀爬楼梯对敏捷性和稳定性有极高要求,对机器人来说极具挑战。无模型的强化学习(RL)可以生成动态运动,但隐式的稳定性奖励和对特定任务奖励函数的过度依赖容易导致不安全的行为,尤其是在楼梯上;而基于模型的落脚点规划器可以编码接触可行性和稳定性结构,但强制执行其硬约束通常会导致保守的运动,限制速度。我们提出了FastStair,一个规划器引导的多阶段学习框架,它协调了这些互补的优势,以实现快速和稳定的楼梯攀爬。FastStair将一个并行的基于模型的落脚点规划器集成到RL训练循环中,以引导探索动态可行的接触点,并预训练一个以安全为中心的基策略。为了减轻规划器引起的保守性和低速和高速动作分布之间的差异,基策略被微调为速度专业化的专家,然后通过低秩自适应(LoRA)集成,以实现整个指令速度范围内的平稳运行。我们将最终的控制器部署在Oli人形机器人上,实现了高达1.65米/秒的指令速度下的稳定楼梯攀爬,并在12秒内穿越了一个33步的螺旋楼梯(每步17厘米高),展示了在长楼梯上的鲁棒高速性能。值得注意的是,所提出的方法是广州塔机器人登高比赛的冠军解决方案。
🔬 方法详解
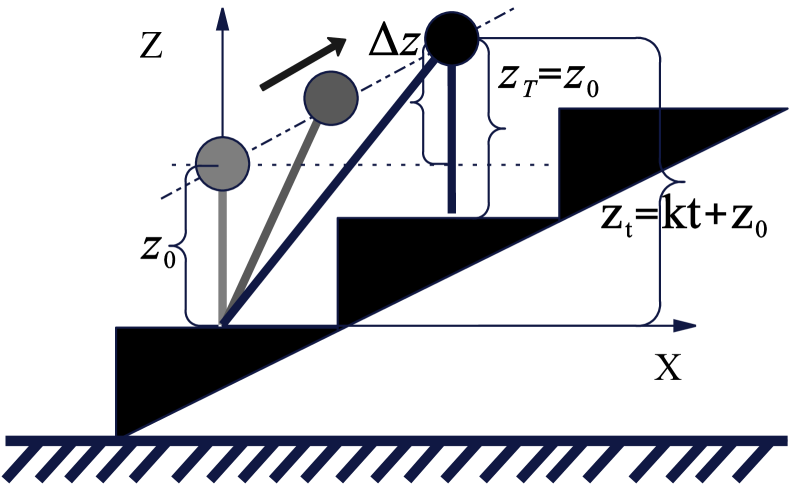
问题定义:人形机器人快速稳定攀爬楼梯是一个复杂的问题,需要同时保证运动的敏捷性和稳定性。现有的无模型强化学习方法虽然可以生成动态运动,但往往依赖于隐式的稳定性奖励和任务相关的奖励函数,导致在楼梯等复杂环境中容易出现不安全的行为。而基于模型的落脚点规划器虽然可以保证接触可行性和稳定性,但其硬约束往往会限制运动速度,导致过于保守的运动策略。
核心思路:FastStair的核心思路是将基于模型的落脚点规划器和强化学习相结合,利用规划器引导强化学习的探索过程,从而提高学习效率和安全性。同时,为了克服规划器带来的保守性,FastStair采用多阶段学习策略,首先预训练一个以安全为中心的基策略,然后通过微调和集成,得到能够适应不同速度的专家策略。
技术框架:FastStair框架包含以下几个主要模块:1) 并行的基于模型的落脚点规划器:用于生成动态可行的落脚点,并为强化学习提供指导。2) 强化学习训练循环:利用规划器生成的落脚点信息,训练一个以安全为中心的基策略。3) 速度专家微调:将基策略微调为多个速度专业化的专家策略,以适应不同的速度需求。4) 低秩自适应(LoRA)集成:利用LoRA技术将多个专家策略集成在一起,从而实现整个指令速度范围内的平稳运行。
关键创新:FastStair的关键创新在于将基于模型的规划器和强化学习相结合,并采用多阶段学习策略。这种方法既可以利用规划器的先验知识来提高学习效率和安全性,又可以通过强化学习来克服规划器的保守性。此外,LoRA集成方法可以有效地将多个专家策略集成在一起,从而实现整个速度范围内的平稳运行。
关键设计:在强化学习训练过程中,使用了稳定性相关的奖励函数,以鼓励机器人学习安全的运动策略。在速度专家微调过程中,针对不同的速度范围,分别训练了不同的专家策略。在LoRA集成过程中,通过调整LoRA的秩,可以控制集成策略的复杂度和泛化能力。具体的参数设置和网络结构在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
FastStair在Oli人形机器人上实现了高达1.65米/秒的稳定爬楼梯速度,并在12秒内完成了33步螺旋楼梯的攀爬。该方法在广州塔机器人登高比赛中获得了冠军,证明了其在实际应用中的有效性和优越性。相较于其他方法,FastStair在速度和稳定性方面都取得了显著的提升。
🎯 应用场景
该研究成果可应用于人形机器人在复杂环境中的运动控制,例如灾难救援、工业巡检、家庭服务等。通过提高人形机器人在楼梯、斜坡等复杂地形上的运动能力,可以使其更好地完成各种任务,具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
Running up stairs is effortless for humans but remains extremely challenging for humanoid robots due to the simultaneous requirements of high agility and strict stability. Model-free reinforcement learning (RL) can generate dynamic locomotion, yet implicit stability rewards and heavy reliance on task-specific reward shaping tend to result in unsafe behaviors, especially on stairs; conversely, model-based foothold planners encode contact feasibility and stability structure, but enforcing their hard constraints often induces conservative motion that limits speed. We present FastStair, a planner-guided, multi-stage learning framework that reconciles these complementary strengths to achieve fast and stable stair ascent. FastStair integrates a parallel model-based foothold planner into the RL training loop to bias exploration toward dynamically feasible contacts and to pretrain a safety-focused base policy. To mitigate planner-induced conservatism and the discrepancy between low- and high-speed action distributions, the base policy was fine-tuned into speed-specialized experts and then integrated via Low-Rank Adaptation (LoRA) to enable smooth operation across the full commanded-speed range. We deploy the resulting controller on the Oli humanoid robot, achieving stable stair ascent at commanded speeds up to 1.65 m/s and traversing a 33-step spiral staircase (17 cm rise per step) in 12 s, demonstrating robust high-speed performance on long staircases. Notably, the proposed approach served as the champion solution in the Canton Tower Robot Run Up Competition.