VLingNav: Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic Memory
作者: Shaoan Wang, Yuanfei Luo, Xingyu Chen, Aocheng Luo, Dongyue Li, Chang Liu, Sheng Chen, Yangang Zhang, Junzhi Yu
分类: cs.RO, cs.CV
发布日期: 2026-01-13
备注: Project page: https://wsakobe.github.io/VLingNav-web/
💡 一句话要点
提出VLingNav,通过自适应推理和视觉辅助语言记忆实现具身导航。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身导航 视觉语言模型 自适应推理 思维链 语言记忆
📋 核心要点
- 现有VLA模型缺乏显式推理能力和持久记忆,难以应对复杂、长程导航任务。
- VLingNav通过自适应思维链和视觉辅助语言记忆,提升推理能力和记忆能力。
- 实验表明,VLingNav在多个基准测试中达到SOTA,并成功零样本迁移到真实机器人。
📝 摘要(中文)
本文提出VLingNav,一个基于语言驱动认知的具身导航VLA模型。该模型引入自适应思维链机制,根据需要动态触发显式推理,从而在快速直观执行和缓慢审慎规划之间流畅切换。同时,开发了视觉辅助语言记忆模块,构建持久的跨模态语义记忆,使智能体能够回忆过去的观察结果,防止重复探索,并推断动态环境中的运动趋势。此外,构建了Nav-AdaCoT-2.9M数据集,这是迄今为止最大的具身导航数据集,包含推理标注,并融入在线专家引导的强化学习阶段。实验表明,VLingNav在多个具身导航基准测试中取得了最先进的性能,并以零样本方式迁移到真实机器人平台,展示了强大的跨领域和跨任务泛化能力。
🔬 方法详解
问题定义:现有基于视觉-语言模型的具身导航方法主要依赖于从观察到动作的直接映射,缺乏显式的推理能力和持久的记忆机制。这导致智能体在复杂和长程导航任务中表现不佳,容易迷失方向,重复探索,无法有效利用历史信息进行规划。
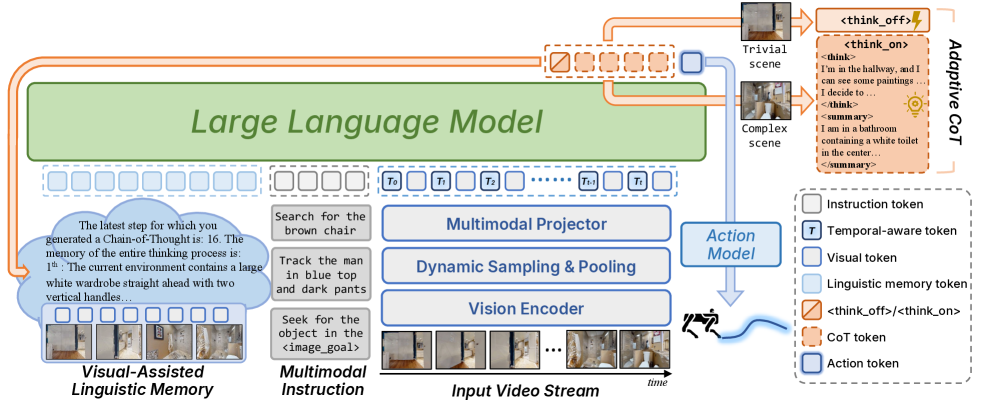
核心思路:VLingNav的核心思路是模拟人类的认知过程,结合快速直观的执行和缓慢审慎的规划。通过引入自适应思维链机制,智能体可以根据环境的复杂程度动态地选择是否进行显式推理。同时,利用视觉辅助的语言记忆模块,构建一个持久的跨模态语义记忆,帮助智能体回忆过去的观察结果,防止重复探索,并推断动态环境中的运动趋势。
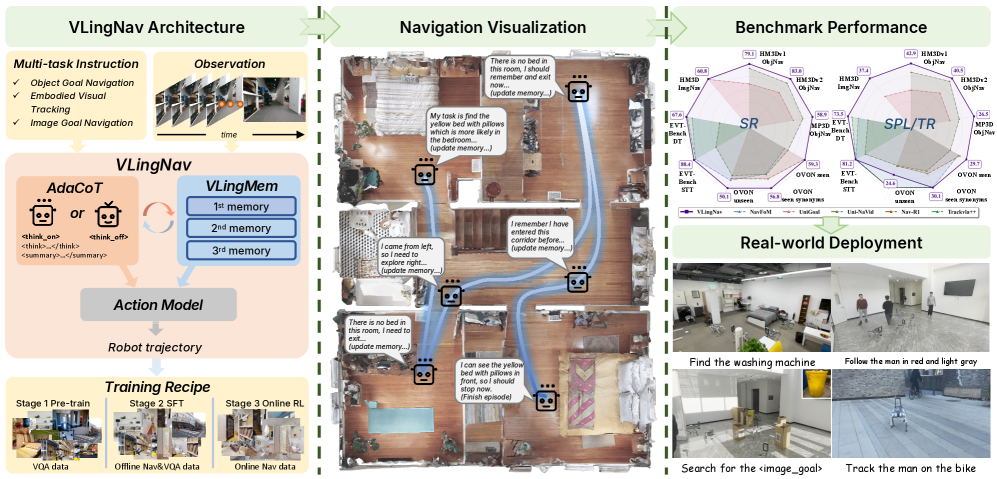
技术框架:VLingNav的整体框架包含三个主要模块:视觉感知模块、自适应推理模块和视觉辅助语言记忆模块。视觉感知模块负责从环境中提取视觉信息。自适应推理模块根据当前环境的复杂程度,决定是否触发思维链推理。视觉辅助语言记忆模块负责存储和检索历史信息,为推理提供上下文。整个流程是:智能体首先通过视觉感知模块获取环境信息,然后自适应推理模块判断是否需要进行显式推理,如果需要,则利用视觉辅助语言记忆模块检索相关信息,进行推理规划,最后执行动作。
关键创新:VLingNav的关键创新在于以下两点:一是自适应思维链机制,它允许智能体根据环境的复杂程度动态地选择是否进行显式推理,从而在效率和准确性之间取得平衡。二是视觉辅助语言记忆模块,它构建了一个持久的跨模态语义记忆,帮助智能体回忆过去的观察结果,防止重复探索,并推断动态环境中的运动趋势。
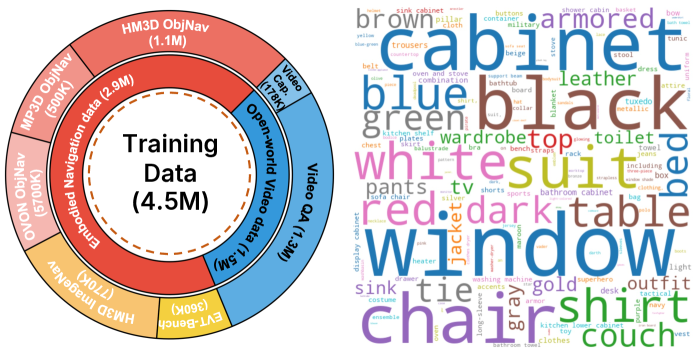
关键设计:Nav-AdaCoT-2.9M数据集包含自适应CoT标注,诱导智能体调整思考时机和内容。在线专家引导的强化学习阶段,使模型超越纯模仿学习,获得更鲁棒的自主探索导航行为。具体参数设置和网络结构细节未在摘要中详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
VLingNav在多个具身导航基准测试中取得了最先进的性能。更重要的是,VLingNav能够以零样本的方式迁移到真实机器人平台,执行各种导航任务,展示了强大的跨领域和跨任务泛化能力。具体的性能数据和对比基线未在摘要中详细描述,属于未知信息。
🎯 应用场景
VLingNav具有广泛的应用前景,例如家庭服务机器人、仓库物流机器人、自动驾驶等领域。它可以帮助机器人在复杂和动态的环境中进行自主导航,完成各种任务,例如送货、清洁、巡逻等。该研究的未来影响在于,它可以推动具身智能的发展,使机器人更加智能、自主和可靠。
📄 摘要(原文)
VLA models have shown promising potential in embodied navigation by unifying perception and planning while inheriting the strong generalization abilities of large VLMs. However, most existing VLA models rely on reactive mappings directly from observations to actions, lacking the explicit reasoning capabilities and persistent memory required for complex, long-horizon navigation tasks. To address these challenges, we propose VLingNav, a VLA model for embodied navigation grounded in linguistic-driven cognition. First, inspired by the dual-process theory of human cognition, we introduce an adaptive chain-of-thought mechanism, which dynamically triggers explicit reasoning only when necessary, enabling the agent to fluidly switch between fast, intuitive execution and slow, deliberate planning. Second, to handle long-horizon spatial dependencies, we develop a visual-assisted linguistic memory module that constructs a persistent, cross-modal semantic memory, enabling the agent to recall past observations to prevent repetitive exploration and infer movement trends for dynamic environments. For the training recipe, we construct Nav-AdaCoT-2.9M, the largest embodied navigation dataset with reasoning annotations to date, enriched with adaptive CoT annotations that induce a reasoning paradigm capable of adjusting both when to think and what to think about. Moreover, we incorporate an online expert-guided reinforcement learning stage, enabling the model to surpass pure imitation learning and to acquire more robust, self-explored navigation behaviors. Extensive experiments demonstrate that VLingNav achieves state-of-the-art performance across a wide range of embodied navigation benchmarks. Notably, VLingNav transfers to real-world robotic platforms in a zero-shot manner, executing various navigation tasks and demonstrating strong cross-domain and cross-task generalization.