AME-2: Agile and Generalized Legged Locomotion via Attention-Based Neural Map Encoding
作者: Chong Zhang, Victor Klemm, Fan Yang, Marco Hutter
分类: cs.RO
发布日期: 2026-01-13
备注: under review
💡 一句话要点
提出基于注意力机制神经地图编码的AME-2框架,实现敏捷且泛化的腿足机器人运动控制。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 腿足机器人 强化学习 运动控制 注意力机制 地图编码 地形感知 敏捷运动 泛化能力
📋 核心要点
- 现有腿足机器人运动方法在敏捷性和泛化性上存在局限,难以同时应对遮挡和稀疏落脚点等复杂地形。
- AME-2框架通过注意力机制神经地图编码器提取地形特征,并结合强化学习控制,实现敏捷且泛化的运动控制。
- 实验结果表明,AME-2在四足和双足机器人上均表现出良好的敏捷性和泛化能力,并在真实环境中进行了验证。
📝 摘要(中文)
本文提出了一种统一的强化学习框架AME-2,用于实现敏捷且泛化的腿足机器人运动控制。该框架在控制策略中引入了一种新颖的基于注意力机制的地图编码器,用于提取局部和全局地图特征,并通过注意力机制聚焦于显著区域,从而为基于强化学习的控制生成可解释且泛化的嵌入。此外,还提出了一种基于学习的地图构建流程,该流程能够快速生成具有不确定性的地形表示,且对噪声和遮挡具有鲁棒性,并作为策略输入。该流程使用神经网络将深度观测转换为具有不确定性的局部高程,并将其与里程计信息融合。该流程还与并行仿真集成,从而可以使用在线地图构建来训练控制器,从而有助于从仿真到现实的迁移。在四足和双足机器人上验证了AME-2与所提出的地图构建流程,结果表明,所得到的控制器在仿真和真实世界的实验中都表现出强大的敏捷性和对未见地形的泛化能力。
🔬 方法详解
问题定义:现有腿足机器人运动控制方法,要么依赖端到端模型,泛化性和可解释性差,要么泛化性好但敏捷性不足,难以应对视觉遮挡等复杂情况。因此,需要一种既能保证敏捷性,又能具备良好泛化能力的运动控制框架。
核心思路:AME-2的核心思路是将感知和控制紧密结合,利用注意力机制从地形地图中提取关键信息,并将其编码为强化学习策略的输入。通过学习一个能够关注重要地形特征的地图编码器,提高控制策略的泛化能力和鲁棒性。
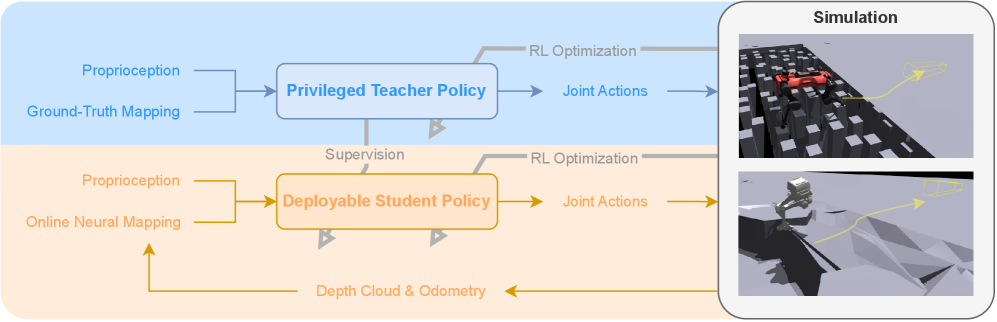
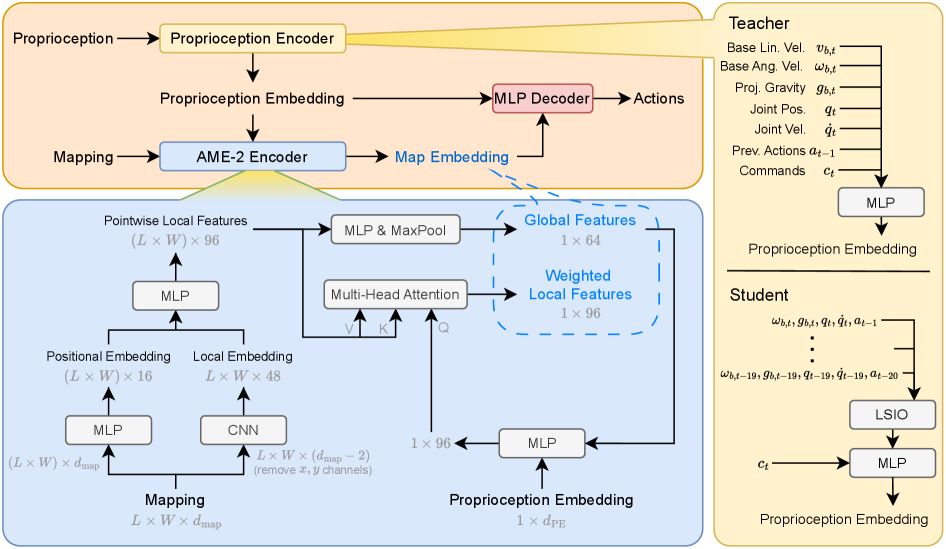
技术框架:AME-2框架包含两个主要模块:基于学习的地图构建流程和基于注意力机制的神经地图编码器。地图构建流程负责将深度观测数据转换为带有不确定性的局部高程图,并与里程计信息融合,生成全局地形地图。神经地图编码器则从地形地图中提取局部和全局特征,并通过注意力机制选择关键区域,生成用于强化学习控制的嵌入。
关键创新:AME-2的关键创新在于提出了基于注意力机制的神经地图编码器,该编码器能够学习关注地形地图中的关键区域,从而提高控制策略的泛化能力和可解释性。此外,基于学习的地图构建流程能够快速生成具有不确定性的地形表示,并对噪声和遮挡具有鲁棒性。
关键设计:地图构建流程使用神经网络将深度图像转换为局部高程图,并估计每个高程值的不确定性。注意力机制采用Transformer结构,用于学习不同区域的重要性权重。强化学习采用PPO算法,奖励函数的设计考虑了运动速度、稳定性、能量消耗等因素。
🖼️ 关键图片

📊 实验亮点
在仿真和真实世界的实验中,AME-2框架在四足和双足机器人上都取得了显著的成果。实验结果表明,AME-2能够使机器人表现出强大的敏捷性和对未见地形的泛化能力。具体性能数据未知,但论文强调了其在复杂地形上的优越表现。
🎯 应用场景
AME-2框架可应用于各种腿足机器人,使其能够在复杂地形中进行自主导航和运动控制,例如搜救、勘探、物流等领域。该框架还可用于开发更智能、更灵活的机器人,以适应各种不同的应用场景。
📄 摘要(原文)
Achieving agile and generalized legged locomotion across terrains requires tight integration of perception and control, especially under occlusions and sparse footholds. Existing methods have demonstrated agility on parkour courses but often rely on end-to-end sensorimotor models with limited generalization and interpretability. By contrast, methods targeting generalized locomotion typically exhibit limited agility and struggle with visual occlusions. We introduce AME-2, a unified reinforcement learning (RL) framework for agile and generalized locomotion that incorporates a novel attention-based map encoder in the control policy. This encoder extracts local and global mapping features and uses attention mechanisms to focus on salient regions, producing an interpretable and generalized embedding for RL-based control. We further propose a learning-based mapping pipeline that provides fast, uncertainty-aware terrain representations robust to noise and occlusions, serving as policy inputs. It uses neural networks to convert depth observations into local elevations with uncertainties, and fuses them with odometry. The pipeline also integrates with parallel simulation so that we can train controllers with online mapping, aiding sim-to-real transfer. We validate AME-2 with the proposed mapping pipeline on a quadruped and a biped robot, and the resulting controllers demonstrate strong agility and generalization to unseen terrains in simulation and in real-world experiments.