FSAG: Enhancing Human-to-Dexterous-Hand Finger-Specific Affordance Grounding via Diffusion Models
作者: Yifan Han, Pengfei Yi, Junyan Li, Hanqing Wang, Gaojing Zhang, Qi Peng Liu, Wenzhao Lian
分类: cs.RO
发布日期: 2026-01-13
💡 一句话要点
FSAG:利用扩散模型增强人手到灵巧手的手指特定可供性抓取
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灵巧手抓取 扩散模型 可供性 跨机械手泛化 深度学习 机器人操作
📋 核心要点
- 现有灵巧抓取方法依赖大量特定硬件数据,难以扩展到新机械手设计。
- 利用预训练扩散模型中的语义先验,从人类演示视频中提取细粒度抓取可供性。
- 无需特定硬件数据集,实现跨机械手的泛化,仅用深度信息即可实现高性能抓取。
📝 摘要(中文)
灵巧抓取合成仍然是一个核心挑战:多指手的维度高和运动学多样性阻碍了为平行爪夹持器开发的算法的直接迁移。现有方法通常依赖于在模拟中或通过昂贵的真实世界试验收集的大型、特定于硬件的抓取数据集,这阻碍了随着新的灵巧手设计的出现而进行扩展。为此,我们提出了一个数据高效的框架,该框架旨在通过利用预训练生成扩散模型中潜在的丰富的、以对象为中心的语义先验来绕过机器人抓取数据收集。从原始人类视频演示中提取时间对齐和细粒度的抓取可供性,并将其与来自深度图像的3D场景几何融合,以推断语义接地的接触目标。然后,一个运动学感知的重定向模块将这些可供性表示映射到不同的灵巧手,而无需对手进行重新训练。由此产生的系统产生稳定的、功能上适当的多接触抓取,这些抓取在常见物体和工具上保持可靠的成功,同时在类别中以前未见过的物体实例、姿势变化和多种手部形态中表现出强大的泛化能力。这项工作(i)引入了一个利用视觉-语言生成先验进行灵巧抓取的语义可供性提取管道,(ii)展示了无需构建特定于硬件的抓取数据集的跨手泛化,以及(iii)证明了当与基础模型语义相结合时,单个深度模态足以实现高性能抓取合成。我们的结果突出了由人类演示和预训练生成模型驱动的可扩展的、硬件无关的灵巧操作的路径。
🔬 方法详解
问题定义:灵巧手抓取合成面临挑战,现有方法依赖大量特定硬件的数据集,难以扩展到新的灵巧手设计。这些数据集的收集成本高昂,限制了灵巧手抓取技术的应用范围。
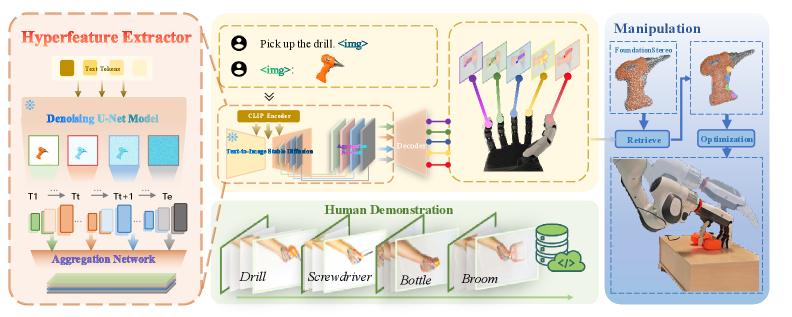
核心思路:利用预训练的生成扩散模型中蕴含的丰富的、以物体为中心的语义信息,绕过对大量机器人抓取数据的依赖。通过从人类演示视频中提取抓取的可供性信息,并将其与3D场景几何信息融合,实现语义接地的抓取目标推断。
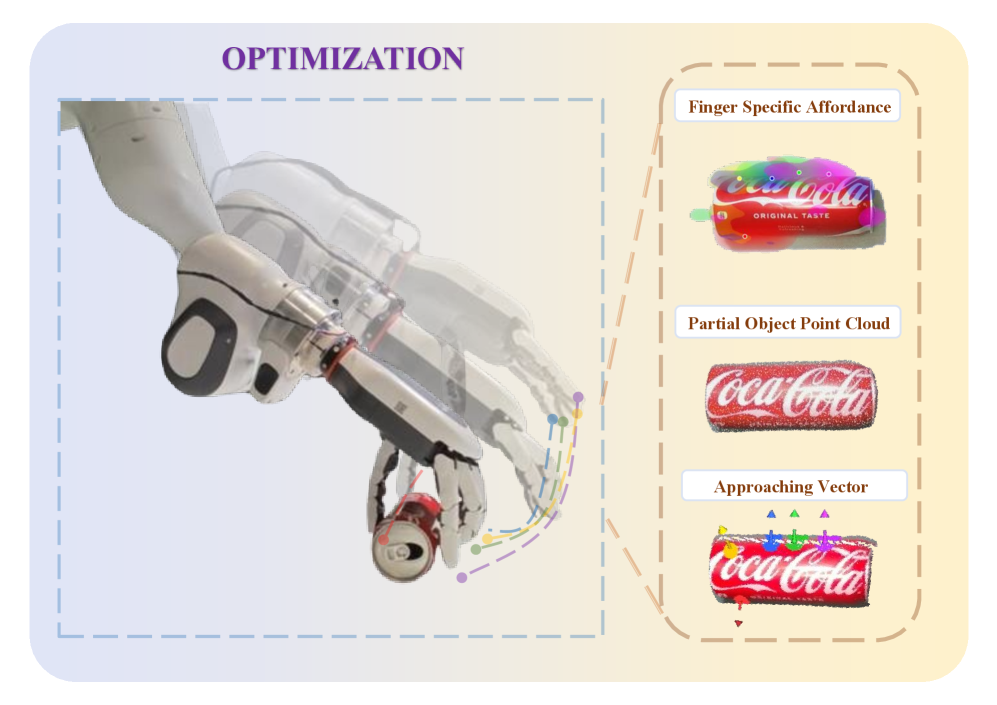
技术框架:该框架包含以下几个主要模块:1) 从人类视频演示中提取时间对齐和细粒度的抓取可供性;2) 将提取的可供性信息与从深度图像获取的3D场景几何信息融合;3) 利用运动学感知的重定向模块,将可供性表示映射到不同的灵巧手,实现跨机械手的抓取。
关键创新:该方法的核心创新在于利用预训练的视觉-语言生成模型来提取抓取的可供性信息,从而避免了对大量特定硬件的机器人抓取数据的依赖。这种方法使得灵巧手抓取技术能够更容易地扩展到新的机械手设计。
关键设计:该方法使用深度图像作为输入,结合预训练扩散模型提取的语义信息,推断抓取目标。运动学感知的重定向模块是实现跨机械手泛化的关键,该模块能够将可供性表示映射到不同机械手的运动学结构上。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
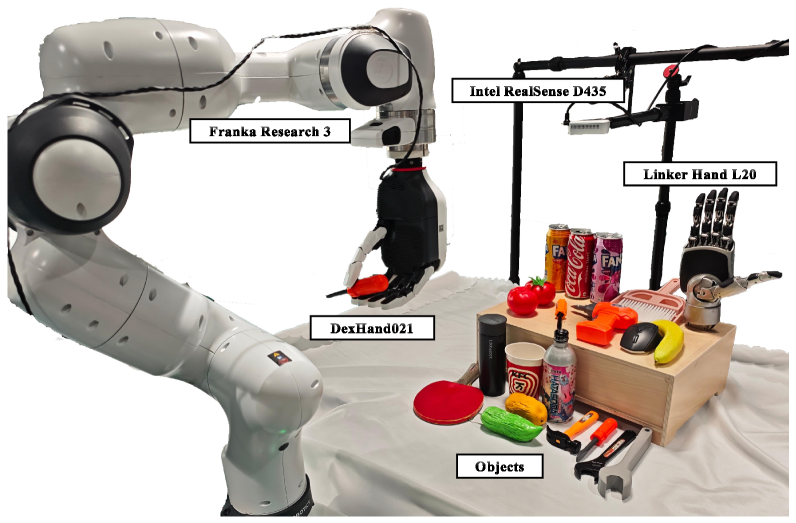
该研究表明,仅使用深度信息,结合预训练扩散模型的语义信息,即可实现高性能的抓取合成。实验结果表明,该方法在常见物体和工具上实现了稳定的、功能上适当的多接触抓取,并且在未见过的物体实例、姿势变化和多种手部形态中表现出强大的泛化能力。具体的性能数据和对比基线在论文中进行了详细描述(未知)。
🎯 应用场景
该研究成果可应用于机器人自动化、智能制造、家庭服务机器人等领域。通过赋予机器人更强的灵巧操作能力,可以实现更复杂的任务,例如物体组装、工具使用、精细操作等。该方法降低了灵巧手抓取技术的应用门槛,促进了机器人技术的普及。
📄 摘要(原文)
Dexterous grasp synthesis remains a central challenge: the high dimensionality and kinematic diversity of multi-fingered hands prevent direct transfer of algorithms developed for parallel-jaw grippers. Existing approaches typically depend on large, hardware-specific grasp datasets collected in simulation or through costly real-world trials, hindering scalability as new dexterous hand designs emerge. To this end, we propose a data-efficient framework, which is designed to bypass robot grasp data collection by exploiting the rich, object-centric semantic priors latent in pretrained generative diffusion models. Temporally aligned and fine-grained grasp affordances are extracted from raw human video demonstrations and fused with 3D scene geometry from depth images to infer semantically grounded contact targets. A kinematics-aware retargeting module then maps these affordance representations to diverse dexterous hands without per-hand retraining. The resulting system produces stable, functionally appropriate multi-contact grasps that remain reliably successful across common objects and tools, while exhibiting strong generalization across previously unseen object instances within a category, pose variations, and multiple hand embodiments. This work (i) introduces a semantic affordance extraction pipeline leveraging vision-language generative priors for dexterous grasping, (ii) demonstrates cross-hand generalization without constructing hardware-specific grasp datasets, and (iii) establishes that a single depth modality suffices for high-performance grasp synthesis when coupled with foundation-model semantics. Our results highlight a path toward scalable, hardware-agnostic dexterous manipulation driven by human demonstrations and pretrained generative models.