Failure-Aware RL: Reliable Offline-to-Online Reinforcement Learning with Self-Recovery for Real-World Manipulation
作者: Huanyu Li, Kun Lei, Sheng Zang, Kaizhe Hu, Yongyuan Liang, Bo An, Xiaoli Li, Huazhe Xu
分类: cs.RO, cs.AI, cs.LG
发布日期: 2026-01-12
备注: Project page: https://failure-aware-rl.github.io
💡 一句话要点
提出FARL:一种面向真实世界操作的故障感知离线到在线强化学习方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 机器人操作 故障恢复 离线学习 在线学习 世界模型 安全评论家
📋 核心要点
- 现有基于深度强化学习的后训练算法在真实机器人应用中,容易出现需要人工干预的故障,阻碍了实际部署。
- FARL通过集成基于世界模型的安全评论家和离线训练的恢复策略,在在线探索过程中预防故障的发生。
- 实验结果表明,FARL在显著减少干预需求型故障的同时,提升了在线强化学习后训练的性能和泛化能力。
📝 摘要(中文)
本文提出了一种新的范式,即故障感知离线到在线强化学习(FARL),旨在最小化真实世界强化学习中的故障。为了解决现实探索中不可避免的干预需求型故障(IR故障),例如机器人洒水或打破易碎玻璃等问题,作者构建了FailureBench基准,该基准包含需要人工干预的常见故障场景。同时,提出了一种算法,该算法集成了基于世界模型的安全评论家和一个离线训练的恢复策略,以防止在线探索期间发生故障。大量的仿真和真实世界实验表明,FARL在显著减少IR故障的同时,提高了在线强化学习后训练期间的性能和泛化能力。在真实世界的强化学习后训练中,FARL平均降低了73.1%的IR故障,同时将性能提升了11.3%。
🔬 方法详解
问题定义:论文旨在解决真实世界机器人强化学习中,由于探索过程中出现需要人工干预的故障(如打翻物体、损坏设备等)而导致学习效率降低甚至任务失败的问题。现有方法通常忽略了这些故障带来的负面影响,或者依赖于昂贵的安全约束,限制了探索空间。
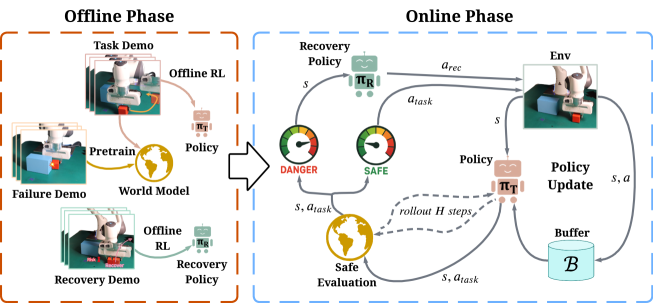
核心思路:FARL的核心思路是在离线数据中学习一个恢复策略,并在在线探索过程中利用世界模型预测潜在的故障,从而提前采取恢复动作,避免故障的发生。通过这种方式,FARL能够在保证安全性的前提下,更有效地进行在线强化学习。
技术框架:FARL包含以下几个主要模块:1) 离线数据集:包含机器人与环境交互的历史数据,包括成功和失败的轨迹。2) 离线恢复策略:利用离线数据训练一个策略,使其能够在故障发生后将机器人恢复到安全状态。3) 基于世界模型的安全评论家:利用世界模型预测机器人在当前状态下采取不同动作后可能产生的后果,并评估其安全性。4) 在线强化学习:利用安全评论家指导在线探索,并利用离线恢复策略避免故障。
关键创新:FARL的关键创新在于将离线恢复策略和基于世界模型的安全评论家相结合,从而在在线强化学习过程中实现故障感知和自我恢复。与现有方法相比,FARL不需要昂贵的安全约束,并且能够更有效地利用离线数据。
关键设计:FARL的关键设计包括:1) 世界模型的选择:论文使用了基于Transformer的世界模型,能够有效地预测机器人的未来状态。2) 安全评论家的设计:安全评论家通过预测未来状态的安全性来评估当前动作的安全性。3) 恢复策略的训练:恢复策略通过模仿学习的方式,从离线数据中学习如何将机器人从故障状态恢复到安全状态。
🖼️ 关键图片


📊 实验亮点
FARL在真实世界的机器人操作任务中表现出色,相较于传统方法,FARL在真实世界的强化学习后训练中,平均降低了73.1%的干预需求型故障(IR Failures),同时将性能提升了11.3%。这些结果表明,FARL能够有效地减少真实世界机器人强化学习中的故障,并提高学习效率。
🎯 应用场景
FARL具有广泛的应用前景,例如在工业机器人、服务机器人、自动驾驶等领域,可以提高机器人在复杂环境中的适应性和鲁棒性,降低故障率,减少人工干预,从而提高生产效率和服务质量。该研究对于推动机器人技术在实际场景中的应用具有重要意义。
📄 摘要(原文)
Post-training algorithms based on deep reinforcement learning can push the limits of robotic models for specific objectives, such as generalizability, accuracy, and robustness. However, Intervention-requiring Failures (IR Failures) (e.g., a robot spilling water or breaking fragile glass) during real-world exploration happen inevitably, hindering the practical deployment of such a paradigm. To tackle this, we introduce Failure-Aware Offline-to-Online Reinforcement Learning (FARL), a new paradigm minimizing failures during real-world reinforcement learning. We create FailureBench, a benchmark that incorporates common failure scenarios requiring human intervention, and propose an algorithm that integrates a world-model-based safety critic and a recovery policy trained offline to prevent failures during online exploration. Extensive simulation and real-world experiments demonstrate the effectiveness of FARL in significantly reducing IR Failures while improving performance and generalization during online reinforcement learning post-training. FARL reduces IR Failures by 73.1% while elevating performance by 11.3% on average during real-world RL post-training. Videos and code are available at https://failure-aware-rl.github.io.