Hiking in the Wild: A Scalable Perceptive Parkour Framework for Humanoids
作者: Shaoting Zhu, Ziwen Zhuang, Mengjie Zhao, Kun-Ying Lee, Hang Zhao
分类: cs.RO, cs.AI
发布日期: 2026-01-12
备注: Project Page: https://project-instinct.github.io/hiking-in-the-wild
💡 一句话要点
提出一种可扩展的拟人机器人野外地形感知跑酷框架,提升复杂地形的稳健行走能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 强化学习 野外行走 地形感知 跑酷 端到端学习 深度学习
📋 核心要点
- 现有基于地图的机器人行走方法易受状态估计漂移影响,端到端方法则面临扩展性和训练复杂性挑战。
- 该论文提出一种端到端跑酷感知框架,结合地形边缘检测和足部体积点,以及平坦区域采样策略,提升行走安全性。
- 实验表明,该方法使人形机器人能够以高达2.5米/秒的速度稳健地穿越复杂地形,代码已开源。
📝 摘要(中文)
为了使人形机器人在复杂的非结构化环境中实现稳健的行走,需要从被动的本体感受过渡到主动的外部感知。然而,整合外部感知仍然是一个巨大的挑战:基于地图的方法会受到状态估计漂移的影响;例如,基于激光雷达的方法不能很好地处理躯干抖动。现有的端到端方法通常难以扩展和训练复杂;特别是,一些先前使用虚拟障碍物的工作是针对特定情况实现的。本文提出了一种可扩展的端到端跑酷感知框架,名为“野外行走”,旨在实现稳健的人形机器人行走。为了确保安全性和训练稳定性,我们引入了两个关键机制:一个结合了可扩展的“地形边缘检测”和“足部体积点”的立足点安全机制,以防止在边缘发生灾难性滑动,以及一个通过生成可行的导航目标来缓解奖励利用的“平坦区域采样”策略。我们的方法采用单阶段强化学习方案,直接将原始深度输入和本体感受映射到关节动作,而不依赖于外部状态估计。在全尺寸人形机器人上进行的大量现场实验表明,我们的策略能够以高达2.5米/秒的速度稳健地穿越复杂地形。训练和部署代码已开源,以方便可重复的研究和在硬件修改最少的情况下在真实机器人上部署。
🔬 方法详解
问题定义:现有的人形机器人野外行走方法主要面临两个痛点:一是依赖地图的方法容易受到状态估计漂移的影响,导致行走不稳定;二是端到端方法在复杂地形下的训练难度大,泛化能力弱,难以扩展到新的地形环境。此外,奖励利用(reward hacking)问题也影响了训练的稳定性和安全性。
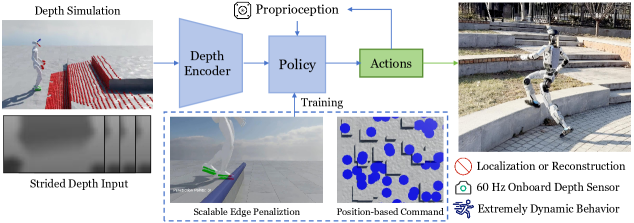
核心思路:该论文的核心思路是设计一个可扩展的端到端强化学习框架,直接从原始深度信息和本体感受学习到关节控制策略,避免了对精确状态估计的依赖。通过引入立足点安全机制和平坦区域采样策略,增强了训练的稳定性和安全性,从而实现了在复杂地形下的稳健行走。
技术框架:该框架采用单阶段强化学习方案,输入包括原始深度图像和本体感受信息,输出为关节动作。主要包含以下模块:1) 感知模块:处理深度图像,提取地形特征;2) 立足点安全机制:结合地形边缘检测和足部体积点,评估潜在立足点的安全性;3) 平坦区域采样策略:生成可行的导航目标,避免奖励利用;4) 强化学习策略:学习从感知信息到关节动作的映射。
关键创新:该论文的关键创新在于:1) 提出了一个可扩展的端到端跑酷感知框架,能够直接从原始深度信息学习行走策略;2) 引入了立足点安全机制,有效防止了在边缘发生灾难性滑动;3) 提出了平坦区域采样策略,缓解了奖励利用问题,提高了训练的稳定性。这些创新使得机器人能够在复杂地形下实现更安全、更稳健的行走。
关键设计:地形边缘检测使用深度图像梯度信息,足部体积点用于评估立足点的稳定性。平坦区域采样策略基于深度图像的局部平坦性进行采样,确保导航目标的可行性。强化学习算法采用PPO(Proximal Policy Optimization),奖励函数综合考虑了行走速度、稳定性、能量消耗等因素。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法使全尺寸人形机器人能够以高达2.5米/秒的速度稳健地穿越复杂地形。与传统的基于地图的方法相比,该方法避免了状态估计漂移问题,提高了行走的鲁棒性。与现有的端到端方法相比,该方法通过引入立足点安全机制和平坦区域采样策略,提高了训练的稳定性和安全性,实现了更好的泛化性能。
🎯 应用场景
该研究成果可应用于搜救机器人、勘探机器人、物流机器人等领域,使其能够在复杂、非结构化的野外环境中执行任务。例如,在灾难救援中,机器人可以利用该技术穿越废墟,搜寻幸存者;在地形勘探中,机器人可以自主行走,收集环境数据。该技术还有助于开发更智能、更灵活的人形机器人,拓展其应用范围。
📄 摘要(原文)
Achieving robust humanoid hiking in complex, unstructured environments requires transitioning from reactive proprioception to proactive perception. However, integrating exteroception remains a significant challenge: mapping-based methods suffer from state estimation drift; for instance, LiDAR-based methods do not handle torso jitter well. Existing end-to-end approaches often struggle with scalability and training complexity; specifically, some previous works using virtual obstacles are implemented case-by-case. In this work, we present \textit{Hiking in the Wild}, a scalable, end-to-end parkour perceptive framework designed for robust humanoid hiking. To ensure safety and training stability, we introduce two key mechanisms: a foothold safety mechanism combining scalable \textit{Terrain Edge Detection} with \textit{Foot Volume Points} to prevent catastrophic slippage on edges, and a \textit{Flat Patch Sampling} strategy that mitigates reward hacking by generating feasible navigation targets. Our approach utilizes a single-stage reinforcement learning scheme, mapping raw depth inputs and proprioception directly to joint actions, without relying on external state estimation. Extensive field experiments on a full-size humanoid demonstrate that our policy enables robust traversal of complex terrains at speeds up to 2.5 m/s. The training and deployment code is open-sourced to facilitate reproducible research and deployment on real robots with minimal hardware modifications.