Reinforcement learning with timed constraints for robotics motion planning
作者: Zhaoan Wang, Junchao Li, Mahdi Mohammad, Shaoping Xiao
分类: cs.RO, cs.LG
发布日期: 2025-12-31
💡 一句话要点
提出基于时序约束的强化学习框架,解决机器人运动规划中时序任务难题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 机器人运动规划 时序逻辑 自动机 时间约束
📋 核心要点
- 现有机器人规划方法难以同时满足复杂任务序列和严格时序约束,尤其是在动态和不确定环境中。
- 论文提出一种基于自动机的强化学习框架,将时序逻辑规范转化为自动机,并与强化学习过程结合,实现时序约束下的策略学习。
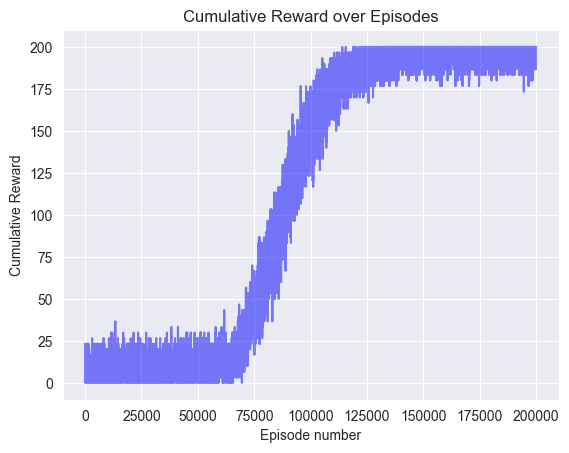
- 实验表明,该框架在MDP和POMDP环境中均能有效学习满足时序约束的策略,并具有良好的可扩展性。
📝 摘要(中文)
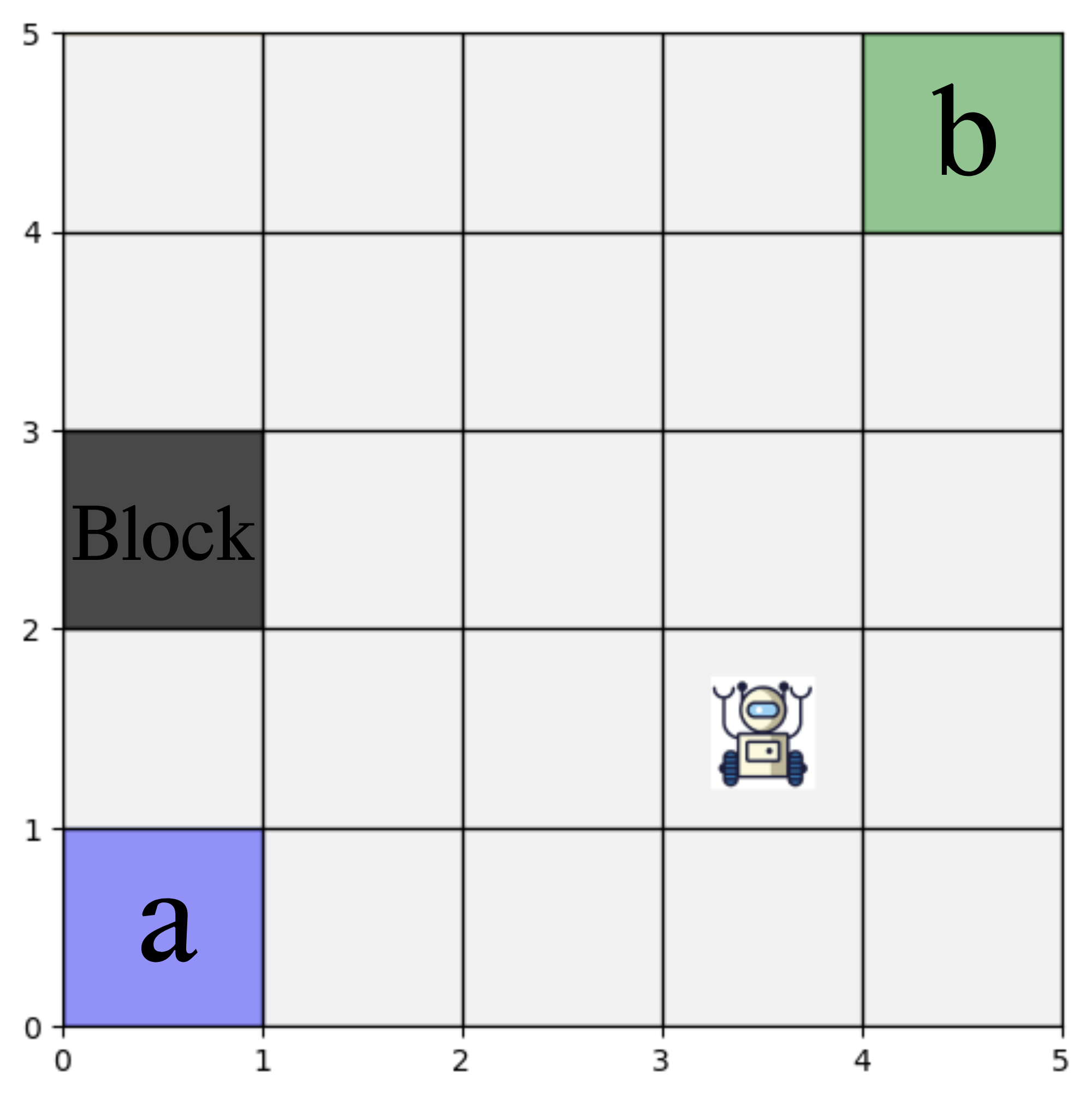
本文提出了一种统一的基于自动机的强化学习框架,用于在马尔可夫决策过程(MDP)和部分可观察马尔可夫决策过程(POMDP)中,根据度量区间时序逻辑(MITL)规范合成策略。该方法将MITL公式转换为时间限制确定性广义Büchi自动机(Timed-LDGBA),并与底层决策过程同步,构建适用于Q学习的乘积时间模型。一个简单而富有表现力的奖励结构在强制执行时间正确性的同时,允许额外的性能目标。该方法在三个仿真研究中得到验证:一个公式化为MDP的5x5网格世界,一个公式化为POMDP的10x10网格世界,以及一个类似办公室的服务机器人场景。结果表明,所提出的框架能够持续学习满足随机转换下严格时间约束的策略,扩展到更大的状态空间,并在部分可观察环境中保持有效性,突出了其在时间关键和不确定环境中可靠机器人规划的潜力。
🔬 方法详解
问题定义:论文旨在解决机器人运动规划中,如何在动态和不确定环境中,同时满足复杂任务序列和严格时序约束的问题。现有方法在处理此类问题时,往往难以兼顾任务的复杂性和时序约束的严格性,尤其是在部分可观察的环境中,策略学习更具挑战。
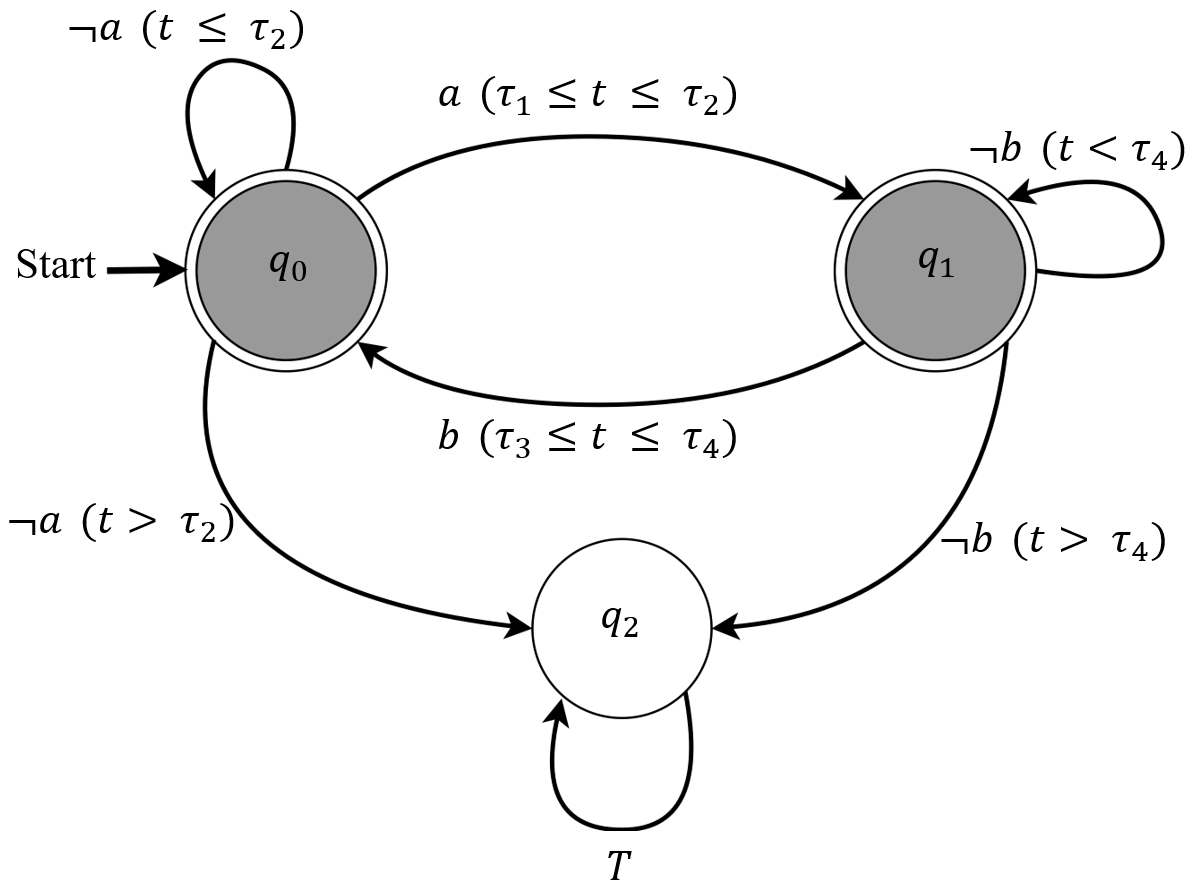
核心思路:论文的核心思路是将时序逻辑规范(MITL)转化为时间限制确定性广义Büchi自动机(Timed-LDGBA),然后将该自动机与底层的马尔可夫决策过程(MDP)或部分可观察马尔可夫决策过程(POMDP)同步,构建一个乘积时间模型。通过在这个乘积模型上进行强化学习,可以学习到满足时序约束的策略。这种方法将时序约束嵌入到强化学习的过程中,从而保证了学习到的策略的正确性。
技术框架:整体框架包括以下几个主要步骤:1) 将MITL公式转化为Timed-LDGBA;2) 将Timed-LDGBA与MDP/POMDP同步,构建乘积时间模型;3) 在乘积时间模型上使用Q-learning算法进行策略学习;4) 设计奖励函数,鼓励满足时序约束的行为,并优化其他性能指标。
关键创新:最重要的技术创新点在于将时序逻辑规范与强化学习过程紧密结合,通过自动机转换和乘积模型构建,将时序约束嵌入到强化学习的奖励函数中。与传统的强化学习方法相比,该方法能够保证学习到的策略满足严格的时序约束,并且能够处理部分可观察的环境。
关键设计:关键设计包括:1) Timed-LDGBA的构建方法,确保能够准确地表示MITL公式;2) 乘积模型的构建方法,保证能够将时序约束与环境动态相结合;3) 奖励函数的设计,既要保证满足时序约束,又要优化其他性能指标。奖励函数通常包括两部分:一部分是与自动机状态相关的奖励,用于鼓励agent进入接受状态;另一部分是与环境状态相关的奖励,用于优化其他性能指标。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该框架在5x5 MDP和10x10 POMDP网格世界中均能成功学习到满足时序约束的策略。在类似办公室的服务机器人场景中,该框架也能够有效地学习到满足时序约束的导航策略。这些结果表明,该框架具有良好的可扩展性和鲁棒性,能够在不同的环境和任务中应用。
🎯 应用场景
该研究成果可应用于各种需要在动态和不确定环境中执行时序任务的机器人系统,例如:服务机器人、自动驾驶汽车、工业机器人等。通过该方法,可以保证机器人在执行任务时,不仅能够完成任务序列,还能够满足严格的时间约束,从而提高系统的可靠性和安全性。未来,该方法还可以扩展到更复杂的任务和环境,例如:多机器人协作、人机协作等。
📄 摘要(原文)
Robotic systems operating in dynamic and uncertain environments increasingly require planners that satisfy complex task sequences while adhering to strict temporal constraints. Metric Interval Temporal Logic (MITL) offers a formal and expressive framework for specifying such time-bounded requirements; however, integrating MITL with reinforcement learning (RL) remains challenging due to stochastic dynamics and partial observability. This paper presents a unified automata-based RL framework for synthesizing policies in both Markov Decision Processes (MDPs) and Partially Observable Markov Decision Processes (POMDPs) under MITL specifications. MITL formulas are translated into Timed Limit-Deterministic Generalized Büchi Automata (Timed-LDGBA) and synchronized with the underlying decision process to construct product timed models suitable for Q-learning. A simple yet expressive reward structure enforces temporal correctness while allowing additional performance objectives. The approach is validated in three simulation studies: a $5 \times 5$ grid-world formulated as an MDP, a $10 \times 10$ grid-world formulated as a POMDP, and an office-like service-robot scenario. Results demonstrate that the proposed framework consistently learns policies that satisfy strict time-bounded requirements under stochastic transitions, scales to larger state spaces, and remains effective in partially observable environments, highlighting its potential for reliable robotic planning in time-critical and uncertain settings.