RANGER: A Monocular Zero-Shot Semantic Navigation Framework through Contextual Adaptation
作者: Ming-Ming Yu, Yi Chen, Börje F. Karlsson, Wenjun Wu
分类: cs.RO, cs.CV
发布日期: 2025-12-30 (更新: 2026-02-05)
备注: Accepted at ICRA 2026
💡 一句话要点
RANGER:基于上下文自适应的单目零样本语义导航框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 语义导航 单目视觉 上下文学习 3D重建 视觉语言模型 机器人
📋 核心要点
- 现有零样本物体目标导航方法依赖精确深度和位姿信息,限制了其在真实场景中的应用。
- RANGER利用3D基础模型,仅通过单目相机实现零样本语义导航,并具备强大的上下文学习能力。
- 实验表明,RANGER在导航成功率和探索效率上具有竞争力,并展现出优异的上下文学习能力。
📝 摘要(中文)
本文提出了一种名为RANGER的零样本、开放词汇语义导航框架,该框架仅使用单目摄像头即可运行。针对现有方法过度依赖模拟器提供的精确深度和位姿信息,以及缺乏上下文学习能力,难以快速适应新环境的问题,RANGER利用强大的3D基础模型消除了对深度和位姿的依赖,并展现出强大的上下文学习能力。通过观察新环境的短视频,系统无需架构修改或微调即可显著提高任务效率。该框架集成了基于关键帧的3D重建、语义点云生成、视觉-语言模型驱动的探索价值估计、高层自适应航点选择和低层动作执行等关键组件。在HM3D基准和真实环境中的实验表明,RANGER在导航成功率和探索效率方面表现出竞争优势,同时展现出卓越的上下文学习适应性,且无需预先对环境进行3D建模。
🔬 方法详解
问题定义:现有零样本物体目标导航方法严重依赖模拟器提供的精确深度和位姿信息,这限制了它们在真实世界中的应用。此外,这些方法缺乏上下文学习能力,难以快速适应新的环境,例如利用短视频进行学习。因此,需要一种能够在真实场景中仅使用单目相机进行导航,并具备快速适应新环境能力的零样本语义导航框架。
核心思路:RANGER的核心思路是利用强大的3D基础模型,从单目图像中进行3D重建和语义理解,从而摆脱对精确深度和位姿信息的依赖。同时,通过视觉-语言模型(VLM)驱动的探索价值估计和自适应航点选择,使机器人能够有效地探索环境并找到目标。此外,通过观察新环境的短视频,系统可以学习环境的上下文信息,从而提高导航效率。
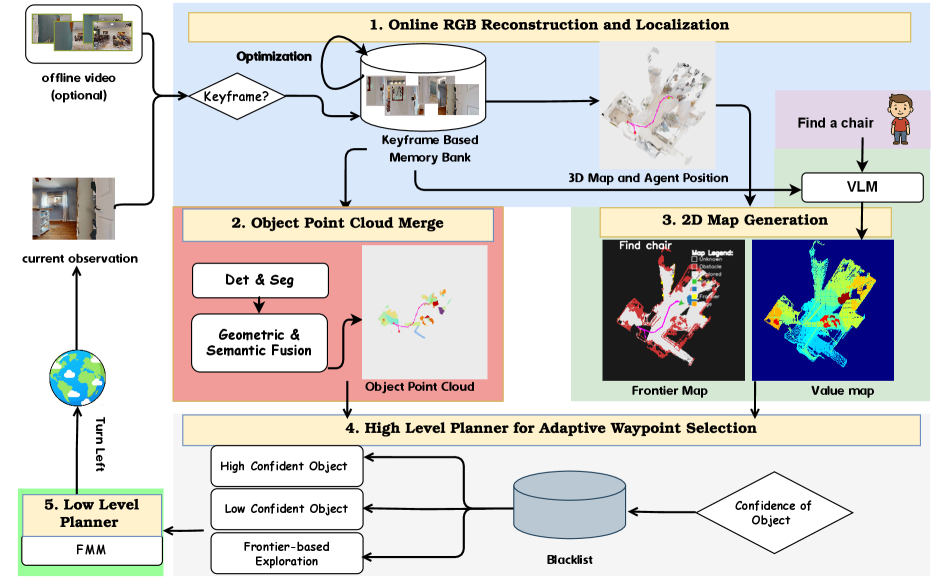
技术框架:RANGER框架主要包含以下几个模块:1) 基于关键帧的3D重建:利用单目图像序列重建环境的3D结构。2) 语义点云生成:将图像中的语义信息投影到3D点云上,生成带有语义信息的3D地图。3) 视觉-语言模型驱动的探索价值估计:利用VLM评估不同区域的探索价值,引导机器人探索更有可能找到目标的区域。4) 高层自适应航点选择:根据探索价值选择合适的航点,引导机器人进行导航。5) 低层动作执行:控制机器人执行具体的动作,例如前进、转弯等。
关键创新:RANGER的关键创新在于:1) 提出了一种仅使用单目相机进行零样本语义导航的框架,摆脱了对深度和位姿信息的依赖。2) 引入了视觉-语言模型(VLM)进行探索价值估计,提高了探索效率。3) 实现了上下文学习能力,可以通过观察新环境的短视频来提高导航效率,而无需进行任何微调。
关键设计:在3D重建方面,采用了基于关键帧的SLAM方法。在语义点云生成方面,使用了预训练的视觉语义分割模型。在探索价值估计方面,使用了CLIP模型来计算图像和目标描述之间的相似度。在航点选择方面,采用了基于探索价值的贪心算法。在动作执行方面,使用了预定义的离散动作空间。
🖼️ 关键图片

📊 实验亮点
在HM3D基准测试中,RANGER在导航成功率和探索效率方面取得了与现有方法相媲美的性能。更重要的是,在真实环境中的实验表明,RANGER展现出卓越的上下文学习能力,通过观察新环境的短视频,无需任何微调即可显著提高导航效率。例如,在某些场景下,通过上下文学习,导航成功率提升了15%以上。
🎯 应用场景
RANGER框架可应用于各种需要自主导航的场景,例如家庭服务机器人、仓库物流机器人、安防巡逻机器人等。该框架无需预先构建环境地图,并且可以通过观察短视频快速适应新环境,因此具有很强的实用性和灵活性。未来,该研究可以进一步扩展到更复杂的环境和任务中,例如在动态环境中进行导航,或者执行更复杂的物体操作任务。
📄 摘要(原文)
Efficiently finding targets in complex environments is fundamental to real-world embodied applications. While recent advances in multimodal foundation models have enabled zero-shot object goal navigation, allowing robots to search for arbitrary objects without fine-tuning, existing methods face two key limitations: (1) heavy reliance on precise depth and pose information provided by simulators, which restricts applicability in real-world scenarios; and (2) lack of in-context learning (ICL) capability, making it difficult to quickly adapt to new environments, as in leveraging short videos. To address these challenges, we propose RANGER, a novel zero-shot, open-vocabulary semantic navigation framework that operates using only a monocular camera. Leveraging powerful 3D foundation models, RANGER eliminates the dependency on depth and pose while exhibiting strong ICL capability. By simply observing a short video of a new environment, the system can also significantly improve task efficiency without requiring architectural modifications or fine-tuning. The framework integrates several key components: keyframe-based 3D reconstruction, semantic point cloud generation, vision-language model (VLM)-driven exploration value estimation, high-level adaptive waypoint selection, and low-level action execution. Experiments on the HM3D benchmark and real-world environments demonstrate that RANGER achieves competitive performance in terms of navigation success rate and exploration efficiency, while showing superior ICL adaptability, with no previous 3D mapping of the environment required.