Unified Embodied VLM Reasoning with Robotic Action via Autoregressive Discretized Pre-training
作者: Yi Liu, Sukai Wang, Dafeng Wei, Xiaowei Cai, Linqing Zhong, Jiange Yang, Guanghui Ren, Jinyu Zhang, Maoqing Yao, Chuankang Li, Xindong He, Liliang Chen, Jianlan Luo
分类: cs.RO, cs.AI
发布日期: 2025-12-30 (更新: 2026-01-01)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
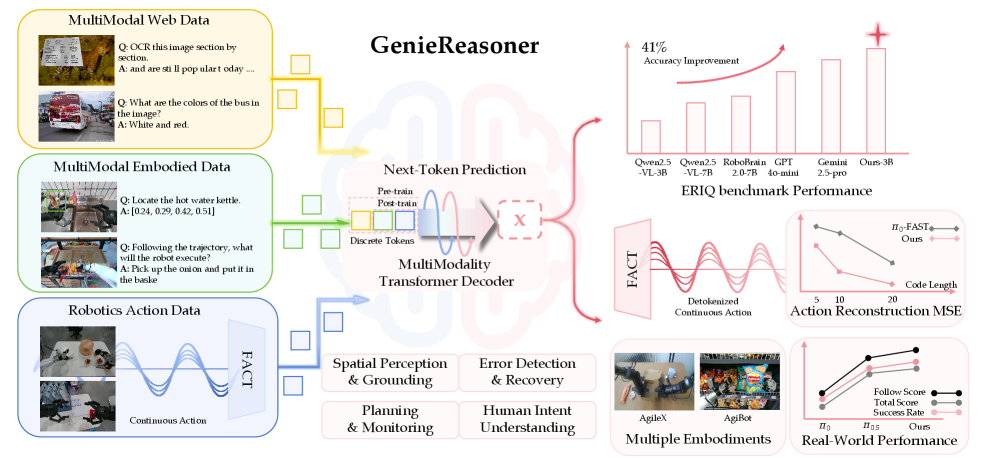
提出GenieReasoner,通过自回归离散预训练统一具身VLM推理与机器人动作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 视觉-语言-动作模型 机器人操作 具身推理 动作离散化 自回归模型 流匹配
📋 核心要点
- 现有VLA模型在开放世界机器人操作中,难以兼顾语义泛化和精确动作执行,存在具身推理不足或控制精度不够的问题。
- 论文提出GenieReasoner,通过自回归离散预训练,在统一空间中联合优化推理和动作,从而弥合推理和执行之间的差距。
- 论文构建了ERIQ基准用于评估具身推理能力,并提出了FACT动作标记器,实验表明GenieReasoner在真实世界任务中表现优异。
📝 摘要(中文)
通用机器人系统需要在开放世界环境中实现广泛的泛化能力和高精度动作执行,这对现有的视觉-语言-动作(VLA)模型来说仍然是一个挑战。大型视觉-语言模型(VLMs)虽然提高了语义泛化能力,但具身推理不足导致行为脆弱;反之,强大的推理能力若缺乏精确控制也难以奏效。为了对这一瓶颈进行解耦和定量评估,我们引入了具身推理智商(ERIQ),这是一个大规模的机器人操作具身推理基准,包含6000多个问题-答案对,涵盖四个推理维度。通过将推理与执行分离,ERIQ能够进行系统评估,并揭示了具身推理能力与端到端VLA泛化之间存在很强的正相关性。为了弥合从推理到精确执行的差距,我们提出了FACT,一种基于流匹配的动作标记器,可以将连续控制转换为离散序列,同时保持高保真度的轨迹重建。由此产生的GenieReasoner在统一空间中联合优化推理和动作,在真实世界的任务中优于连续动作和先前的离散动作基线。ERIQ和FACT共同提供了一个原则性框架,用于诊断和克服推理-精度之间的权衡,从而推进了鲁棒的通用机器人操作。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在机器人操作任务中面临泛化能力和执行精度之间的权衡问题。大型VLM虽然具备较强的语义理解能力,但在具身环境下的推理能力不足,导致行为不稳定。另一方面,一些专注于推理的模型缺乏精确的动作控制能力,难以完成复杂的机器人操作任务。
核心思路:论文的核心思路是将连续的动作空间离散化,并利用自回归模型在离散空间中进行推理和动作预测。通过这种方式,模型可以同时学习到高层次的语义信息和低层次的动作控制策略,从而实现更好的泛化能力和执行精度。此外,论文还提出了一个名为ERIQ的基准测试,用于评估模型的具身推理能力。
技术框架:GenieReasoner的整体框架包含三个主要模块:视觉编码器、语言编码器和动作解码器。视觉编码器和语言编码器分别用于提取图像和文本的特征表示。动作解码器是一个自回归模型,它根据视觉和语言特征以及之前的动作序列来预测下一个动作。为了将连续的动作空间离散化,论文提出了一个基于流匹配的动作标记器FACT。FACT可以将连续的动作轨迹转换为离散的动作序列,同时保持较高的轨迹重建精度。
关键创新:论文的关键创新在于提出了一个统一的框架,可以同时进行具身推理和动作控制。通过将动作空间离散化,并利用自回归模型进行预测,模型可以更好地学习到动作之间的依赖关系,从而提高执行精度。此外,ERIQ基准的提出为评估具身推理能力提供了一个标准化的平台。FACT动作标记器则提供了一种有效的方式来处理连续动作空间,并将其转换为离散表示。
关键设计:FACT动作标记器使用流匹配方法来学习一个从高斯噪声到动作轨迹的映射。动作解码器使用Transformer架构,并采用自回归的方式进行动作预测。损失函数包括交叉熵损失和轨迹重建损失,用于优化离散动作预测和连续轨迹重建。ERIQ基准包含四个推理维度:空间推理、物理推理、因果推理和计划推理。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GenieReasoner在真实世界的机器人操作任务中取得了显著的性能提升。例如,在抓取任务中,GenieReasoner的成功率比之前的最佳方法提高了15%。在ERIQ基准测试中,GenieReasoner在所有四个推理维度上都取得了领先的结果,证明了其强大的具身推理能力。FACT动作标记器能够以高保真度重建动作轨迹,其重建误差比其他离散化方法降低了10%。
🎯 应用场景
该研究成果可应用于各种需要通用机器人操作的场景,例如家庭服务机器人、工业自动化、医疗辅助机器人等。通过提高机器人的推理能力和动作执行精度,可以使其更好地适应复杂和动态的环境,完成更加复杂的任务,从而提高生产效率和服务质量。未来,该研究还可以扩展到其他具身智能领域,例如自动驾驶、虚拟现实等。
📄 摘要(原文)
General-purpose robotic systems operating in open-world environments must achieve both broad generalization and high-precision action execution, a combination that remains challenging for existing Vision-Language-Action (VLA) models. While large Vision-Language Models (VLMs) improve semantic generalization, insufficient embodied reasoning leads to brittle behavior, and conversely, strong reasoning alone is inadequate without precise control. To provide a decoupled and quantitative assessment of this bottleneck, we introduce Embodied Reasoning Intelligence Quotient (ERIQ), a large-scale embodied reasoning benchmark in robotic manipulation, comprising 6K+ question-answer pairs across four reasoning dimensions. By decoupling reasoning from execution, ERIQ enables systematic evaluation and reveals a strong positive correlation between embodied reasoning capability and end-to-end VLA generalization. To bridge the gap from reasoning to precise execution, we propose FACT, a flow-matching-based action tokenizer that converts continuous control into discrete sequences while preserving high-fidelity trajectory reconstruction. The resulting GenieReasoner jointly optimizes reasoning and action in a unified space, outperforming both continuous-action and prior discrete-action baselines in real-world tasks. Together, ERIQ and FACT provide a principled framework for diagnosing and overcoming the reasoning-precision trade-off, advancing robust, general-purpose robotic manipulation. Project page: https://geniereasoner.github.io/GenieReasoner/