Do You Have Freestyle? Expressive Humanoid Locomotion via Audio Control
作者: Zhe Li, Cheng Chi, Yangyang Wei, Boan Zhu, Tao Huang, Zhenguo Sun, Yibo Peng, Pengwei Wang, Zhongyuan Wang, Fangzhou Liu, Chang Xu, Shanghang Zhang
分类: cs.RO
发布日期: 2025-12-29 (更新: 2026-01-04)
💡 一句话要点
RoboPerform:提出一种基于音频控制的拟人机器人表达性运动生成框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 音频控制 机器人运动生成 拟人机器人 扩散模型 ResMoE 运动风格迁移 人机交互
📋 核心要点
- 现有拟人机器人缺乏表达性的即兴运动能力,通常局限于预定义的动作或稀疏的指令,无法自然地对音频做出反应。
- RoboPerform将音频作为隐式风格信号,直接生成与音频匹配的机器人运动,避免了传统方法中显式的运动重建过程。
- 实验结果表明,RoboPerform生成的运动在物理合理性和音频对齐方面表现良好,能够使机器人根据音频进行舞蹈和姿态表演。
📝 摘要(中文)
本文提出RoboPerform,首个统一的音频到运动框架,能够直接从音频生成音乐驱动的舞蹈和语音驱动的协同语音姿态,无需显式的运动重建。该框架遵循“运动=内容+风格”的核心原则,将音频视为隐式的风格信号,避免了显式运动重建的需求,从而降低了延迟和误差累积。RoboPerform集成了ResMoE教师策略以适应多样化的运动模式,以及一个基于扩散模型的学生策略用于音频风格注入。这种无需重定向的设计确保了低延迟和高保真度。实验验证表明,RoboPerform在物理合理性和音频对齐方面取得了有希望的结果,成功地将机器人转变为能够对音频做出反应的表演者。
🔬 方法详解
问题定义:现有方法在生成音频驱动的机器人运动时,通常需要先从音频重建人体运动,然后再将运动重定向到机器人。这种方法存在级联误差、高延迟以及声学-驱动映射不连贯等问题,限制了机器人的表达性和实时性。
核心思路:RoboPerform的核心思路是将音频直接映射到机器人的运动控制信号,避免了中间的运动重建步骤。该方法将音频视为运动风格的隐式表达,通过学习音频和运动之间的直接映射关系,实现低延迟和高保真度的运动生成。遵循“运动=内容+风格”的原则,将音频信息融入到运动生成过程中。
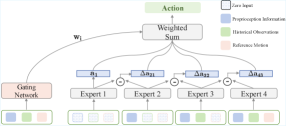
技术框架:RoboPerform框架包含一个ResMoE(Residual Mixture of Experts)教师策略和一个基于扩散模型的学生策略。教师策略负责学习多样化的运动模式,学生策略则负责将音频风格注入到运动中。整个框架采用端到端的设计,直接从音频生成机器人的关节控制信号。
关键创新:RoboPerform的关键创新在于其无需重定向的设计,避免了传统方法中的运动重建和重定向步骤,从而降低了延迟和误差累积。此外,该框架还采用了ResMoE教师策略和扩散模型学生策略,提高了运动的多样性和真实感。
关键设计:ResMoE教师策略采用残差连接和混合专家网络,能够更好地适应多样化的运动模式。扩散模型学生策略则通过学习音频和运动之间的条件概率分布,实现音频风格的注入。损失函数包括运动学损失、物理损失和音频对齐损失,以保证生成的运动在物理上合理,并且与音频同步。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RoboPerform在物理合理性和音频对齐方面取得了显著的成果。通过与现有方法的对比,RoboPerform能够生成更加自然和流畅的机器人运动,并且能够更好地与音频同步。此外,该框架还具有较低的延迟,能够实现实时的音频驱动运动生成。
🎯 应用场景
RoboPerform具有广泛的应用前景,例如:娱乐机器人、虚拟人物控制、康复训练等。它可以使机器人能够根据音乐跳舞,或者根据语音进行自然的姿态表达,从而提高人机交互的自然性和趣味性。未来,该技术可以应用于更复杂的机器人控制任务,例如:辅助机器人进行精细操作,或者使机器人在复杂环境中进行自主导航。
📄 摘要(原文)
Humans intuitively move to sound, but current humanoid robots lack expressive improvisational capabilities, confined to predefined motions or sparse commands. Generating motion from audio and then retargeting it to robots relies on explicit motion reconstruction, leading to cascaded errors, high latency, and disjointed acoustic-actuation mapping. We propose RoboPerform, the first unified audio-to-locomotion framework that can directly generate music-driven dance and speech-driven co-speech gestures from audio. Guided by the core principle of "motion = content + style", the framework treats audio as implicit style signals and eliminates the need for explicit motion reconstruction. RoboPerform integrates a ResMoE teacher policy for adapting to diverse motion patterns and a diffusion-based student policy for audio style injection. This retargeting-free design ensures low latency and high fidelity. Experimental validation shows that RoboPerform achieves promising results in physical plausibility and audio alignment, successfully transforming robots into responsive performers capable of reacting to audio.