SurgWorld: Learning Surgical Robot Policies from Videos via World Modeling
作者: Yufan He, Pengfei Guo, Mengya Xu, Zhaoshuo Li, Andriy Myronenko, Dillan Imans, Bingjie Liu, Dongren Yang, Mingxue Gu, Yongnan Ji, Yueming Jin, Ren Zhao, Baiyong Shen, Daguang Xu
分类: cs.RO, cs.CV
发布日期: 2025-12-29 (更新: 2026-01-05)
💡 一句话要点
SurgWorld:通过世界建模从视频中学习手术机器人策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手术机器人 世界模型 视觉语言动作 逆动力学 数据增强
📋 核心要点
- 手术机器人自主学习面临数据匮乏,尤其是缺乏带精确动作标签的视频数据。
- 提出SurgWorld世界模型,结合SATA数据集生成逼真手术视频,并用逆动力学推断伪运动学。
- 实验表明,用SurgWorld增强数据训练的VLA策略,在真实机器人上显著优于仅用真实数据训练的模型。
📝 摘要(中文)
数据稀缺是实现完全自主手术机器人的根本障碍。大规模视觉语言动作(VLA)模型通过利用来自不同领域的配对视频动作数据,在家庭和工业操作中表现出令人印象深刻的泛化能力,但手术机器人技术却面临着缺乏包含视觉观察和精确机器人运动学的数据集的问题。相比之下,存在大量的手术视频语料库,但它们缺乏相应的动作标签,从而无法直接应用模仿学习或VLA训练。在这项工作中,我们旨在通过从SurgWorld(一种专为手术物理AI设计的世界模型)中学习策略模型来缓解这个问题。我们整理了手术动作文本对齐(SATA)数据集,其中包含专门针对手术机器人的详细动作描述。然后,我们基于最先进的物理AI世界模型和SATA构建了SurgeWorld。它能够生成多样化、可泛化和逼真的手术视频。我们也是第一个使用逆动力学模型从合成手术视频中推断伪运动学,从而生成合成的配对视频动作数据。我们证明,使用这些增强数据训练的手术VLA策略在真实手术机器人平台上明显优于仅在真实演示上训练的模型。我们的方法通过利用大量未标记的手术视频和生成式世界建模,为自主手术技能获取提供了一条可扩展的路径,从而为可泛化和数据高效的手术机器人策略打开了大门。
🔬 方法详解
问题定义:手术机器人自主学习面临数据稀缺问题,特别是缺乏包含视觉信息和精确机器人运动学信息的配对数据。现有方法难以直接利用大量未标注的手术视频,限制了模仿学习和视觉语言动作模型的应用。
核心思路:论文的核心思路是构建一个名为SurgWorld的合成手术环境,通过世界模型生成大量带有动作标签的视频数据,从而克服真实数据稀缺的问题。通过逆动力学模型从合成视频中推断伪运动学信息,弥补了合成数据与真实数据之间的差距。
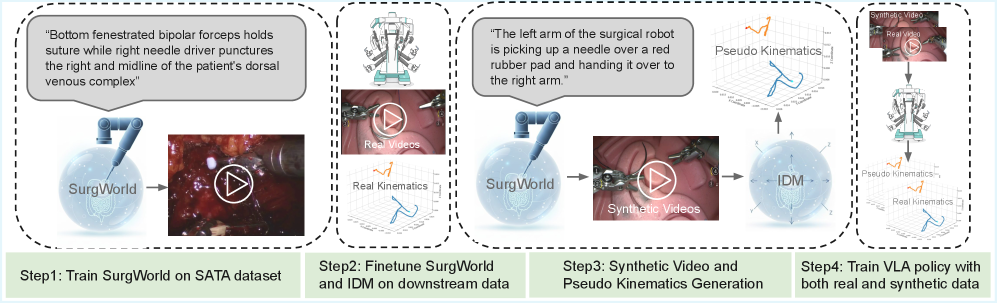
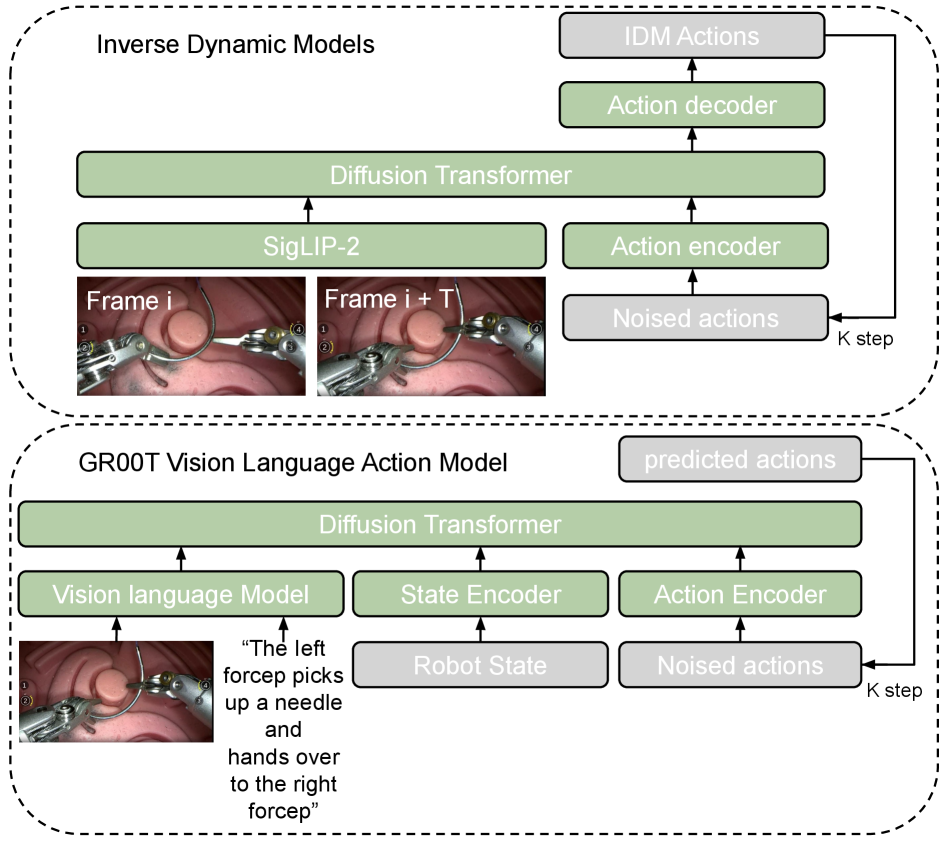
技术框架:整体框架包含以下几个主要模块:1) SATA数据集构建,包含手术动作的文本描述;2) 基于物理AI世界模型构建SurgWorld,用于生成逼真的手术视频;3) 逆动力学模型,用于从合成视频中推断伪运动学信息;4) VLA策略训练,使用合成数据增强真实数据,训练手术机器人控制策略。
关键创新:最重要的技术创新点在于利用世界模型生成合成手术视频,并结合逆动力学模型推断伪运动学信息,从而构建大规模的配对视频动作数据集。这种方法有效地解决了手术机器人领域数据稀缺的问题,为自主学习提供了新的途径。
关键设计:SATA数据集的设计注重动作描述的详细程度和准确性,世界模型的构建基于先进的物理AI技术,保证了生成视频的真实性和多样性。逆动力学模型的设计需要考虑手术机器人的运动学特性和动力学特性,以保证推断的伪运动学信息的准确性。VLA策略训练过程中,需要合理设置合成数据和真实数据的比例,以平衡模型的泛化能力和真实性。
🖼️ 关键图片
📊 实验亮点
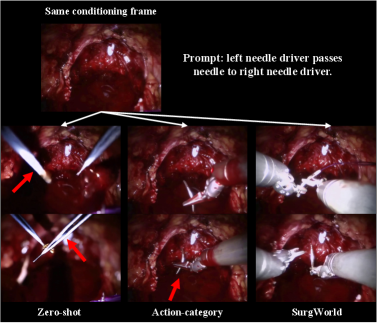
实验结果表明,使用SurgWorld生成的合成数据增强训练的VLA策略,在真实手术机器人平台上显著优于仅使用真实数据训练的模型。具体性能提升幅度未知,但该结果验证了SurgWorld在解决数据稀缺问题上的有效性,并为手术机器人自主学习提供了新的思路。
🎯 应用场景
该研究成果可应用于手术机器人的自主技能学习、手术规划和导航、以及手术机器人的远程操作等领域。通过利用大量未标注的手术视频,可以降低手术机器人自主学习的成本,提高手术机器人的智能化水平,最终提升手术效率和安全性,改善患者的治疗效果。
📄 摘要(原文)
Data scarcity remains a fundamental barrier to achieving fully autonomous surgical robots. While large scale vision language action (VLA) models have shown impressive generalization in household and industrial manipulation by leveraging paired video action data from diverse domains, surgical robotics suffers from the paucity of datasets that include both visual observations and accurate robot kinematics. In contrast, vast corpora of surgical videos exist, but they lack corresponding action labels, preventing direct application of imitation learning or VLA training. In this work, we aim to alleviate this problem by learning policy models from SurgWorld, a world model designed for surgical physical AI. We curated the Surgical Action Text Alignment (SATA) dataset with detailed action description specifically for surgical robots. Then we built SurgeWorld based on the most advanced physical AI world model and SATA. It's able to generate diverse, generalizable and realistic surgery videos. We are also the first to use an inverse dynamics model to infer pseudokinematics from synthetic surgical videos, producing synthetic paired video action data. We demonstrate that a surgical VLA policy trained with these augmented data significantly outperforms models trained only on real demonstrations on a real surgical robot platform. Our approach offers a scalable path toward autonomous surgical skill acquisition by leveraging the abundance of unlabeled surgical video and generative world modeling, thus opening the door to generalizable and data efficient surgical robot policies.