Clutter-Resistant Vision-Language-Action Models through Object-Centric and Geometry Grounding
作者: Khoa Vo, Taisei Hanyu, Yuki Ikebe, Trong Thang Pham, Nhat Chung, Minh Nhat Vu, Duy Nguyen Ho Minh, Anh Nguyen, Anthony Gunderman, Chase Rainwater, Ngan Le
分类: cs.RO
发布日期: 2025-12-27
备注: Under review. Project website: https://uark-aicv.github.io/OBEYED_VLA
💡 一句话要点
提出OBEYED-VLA,通过对象中心和几何信息增强VLA模型在杂乱环境下的鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人操作 对象中心感知 几何感知 多视图立体 鲁棒性 环境理解
📋 核心要点
- 现有VLA模型在复杂环境中泛化能力不足,易受杂物、背景变化等因素干扰,影响操作精度。
- OBEYED-VLA通过显式解耦感知和控制,利用VLM进行对象中心语义理解,并结合几何信息增强3D结构感知。
- 实验表明,OBEYED-VLA在真实机器人操作任务中,显著提升了对干扰物、目标缺失和背景变化的鲁棒性。
📝 摘要(中文)
现有的视觉-语言-动作(VLA)模型通过对大型视觉-语言模型(VLM)进行动作预测的后训练,在通用机器人操作方面取得了显著进展。然而,大多数VLA模型将感知和控制纠缠在一个纯粹为动作优化的单片流程中,这会削弱语言条件下的基础。在我们的真实桌面测试中,策略在目标不存在时过度抓取,容易受到杂物干扰,并且过度拟合背景外观。为了解决这些问题,我们提出了OBEYED-VLA,一个明确将感知基础与动作推理分离的框架。OBEYED-VLA没有直接在原始RGB上操作,而是使用一个感知模块来增强VLA,该模块将多视图输入融入到任务条件、对象中心和几何感知的观察中。该模块包括一个基于VLM的对象中心基础阶段,用于选择跨相机视图的任务相关对象区域,以及一个补充的几何基础阶段,强调这些对象的3D结构而不是它们的外观。然后将生成的接地视图馈送到预训练的VLA策略,我们专门针对在没有环境杂乱或非目标对象的情况下收集的单对象演示进行微调。在真实的UR10e桌面设置中,OBEYED-VLA在四个具有挑战性的场景和多个难度级别上显著提高了对强VLA基线的鲁棒性:干扰对象、拒绝不存在的目标、背景外观变化以及未见对象的杂乱操作。消融研究证实,语义基础和几何感知基础对于这些增益至关重要。总的来说,结果表明,将感知作为一个显式的、以对象为中心的组件是加强和推广基于VLA的机器人操作的有效方法。
🔬 方法详解
问题定义:现有VLA模型在真实场景中,尤其是在存在杂物、目标缺失或背景变化的情况下,表现出较差的鲁棒性。它们通常将感知和控制紧密耦合,导致模型难以区分目标对象和干扰因素,容易产生错误的动作预测。现有方法缺乏对场景几何信息的有效利用,过度依赖视觉外观特征,容易受到光照、遮挡等因素的影响。
核心思路:OBEYED-VLA的核心思路是将感知和控制解耦,并显式地引入对象中心和几何信息。通过对象中心感知,模型能够专注于任务相关的对象区域,减少干扰因素的影响。通过几何感知,模型能够更好地理解场景的3D结构,提高对目标对象姿态和位置的估计精度。这种解耦和增强感知的设计使得模型能够更好地泛化到不同的场景和任务。
技术框架:OBEYED-VLA包含两个主要模块:感知模块和控制模块。感知模块负责从多视图RGB图像中提取对象中心和几何感知的特征表示。该模块首先使用VLM进行对象中心语义分割,识别任务相关的对象区域。然后,利用几何感知模块提取这些区域的3D结构信息。控制模块接收感知模块提取的特征表示,并使用预训练的VLA策略进行动作预测。该策略在单对象演示数据上进行微调,以提高其在复杂环境中的鲁棒性。
关键创新:OBEYED-VLA的关键创新在于其显式的对象中心和几何感知模块。与现有方法直接在原始RGB图像上进行动作预测不同,OBEYED-VLA首先提取任务相关的对象区域,并利用几何信息增强对这些区域的3D结构理解。这种显式的感知模块使得模型能够更好地应对复杂环境中的干扰因素,提高动作预测的准确性。
关键设计:对象中心语义分割使用预训练的VLM,并针对特定任务进行微调。几何感知模块使用多视图立体匹配算法提取3D点云,并利用PointNet等网络结构提取几何特征。控制模块使用预训练的VLA策略,并使用行为克隆损失进行微调。微调数据仅包含单对象演示,以避免模型过度拟合特定场景。
🖼️ 关键图片

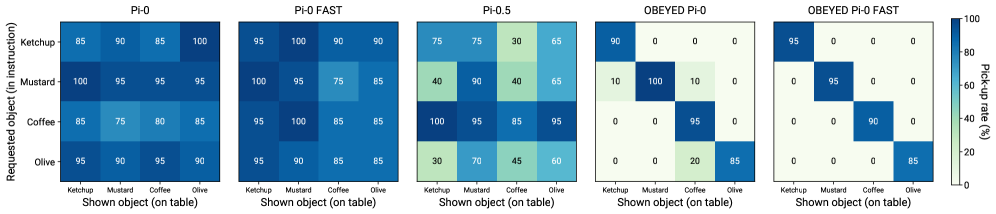
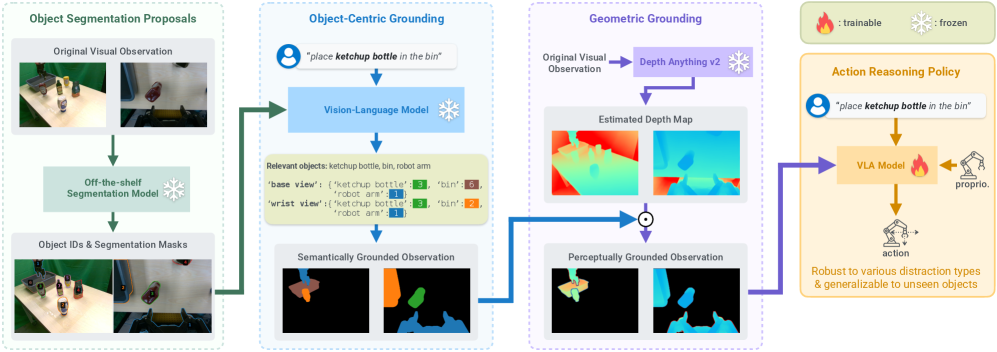
📊 实验亮点
在真实的UR10e机器人平台上,OBEYED-VLA在四个具有挑战性的场景中显著优于基线方法。例如,在存在干扰物的情况下,OBEYED-VLA的成功率比基线方法提高了20%以上。消融实验表明,对象中心语义分割和几何感知模块都对性能提升至关重要。这些结果表明,OBEYED-VLA是一种有效的增强VLA模型鲁棒性的方法。
🎯 应用场景
OBEYED-VLA可应用于各种机器人操作任务,尤其是在复杂、非结构化的环境中。例如,它可以用于仓库拣选、家庭服务机器人、医疗辅助机器人等领域。通过提高机器人对环境的理解和鲁棒性,可以实现更安全、更高效的自动化操作,降低人工成本,提高生产效率。
📄 摘要(原文)
Recent Vision-Language-Action (VLA) models have made impressive progress toward general-purpose robotic manipulation by post-training large Vision-Language Models (VLMs) for action prediction. Yet most VLAs entangle perception and control in a monolithic pipeline optimized purely for action, which can erode language-conditioned grounding. In our real-world tabletop tests, policies over-grasp when the target is absent, are distracted by clutter, and overfit to background appearance. To address these issues, we propose OBEYED-VLA (OBject-centric and gEometrY groundED VLA), a framework that explicitly disentangles perceptual grounding from action reasoning. Instead of operating directly on raw RGB, OBEYED-VLA augments VLAs with a perception module that grounds multi-view inputs into task-conditioned, object-centric, and geometry-aware observations. This module includes a VLM-based object-centric grounding stage that selects task-relevant object regions across camera views, along with a complementary geometric grounding stage that emphasizes the 3D structure of these objects over their appearance. The resulting grounded views are then fed to a pretrained VLA policy, which we fine-tune exclusively on single-object demonstrations collected without environmental clutter or non-target objects. On a real-world UR10e tabletop setup, OBEYED-VLA substantially improves robustness over strong VLA baselines across four challenging regimes and multiple difficulty levels: distractor objects, absent-target rejection, background appearance changes, and cluttered manipulation of unseen objects. Ablation studies confirm that both semantic grounding and geometry-aware grounding are critical to these gains. Overall, the results indicate that making perception an explicit, object-centric component is an effective way to strengthen and generalize VLA-based robotic manipulation.