Proprioception Enhances Vision Language Model in Generating Captions and Subtask Segmentations for Robot Task
作者: Kanata Suzuki, Shota Shimizu, Tetsuya Ogata
分类: cs.RO
发布日期: 2025-12-24 (更新: 2026-01-12)
💡 一句话要点
提出一种融合机器人运动信息的视觉语言模型,用于机器人任务的自动描述和子任务分割。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 机器人任务理解 运动信息融合 视频描述 子任务分割
📋 核心要点
- 现有的视觉语言模型在理解机器人任务视频时,缺乏对底层机器人运动信息的有效利用,导致视频理解能力受限。
- 该论文提出一种融合机器人关节和末端执行器状态等运动信息的视觉语言模型,以增强其对机器人任务的理解能力。
- 通过模拟器实验验证,该方法在机器人任务的自动描述和子任务分割任务上均取得了较好的效果。
📝 摘要(中文)
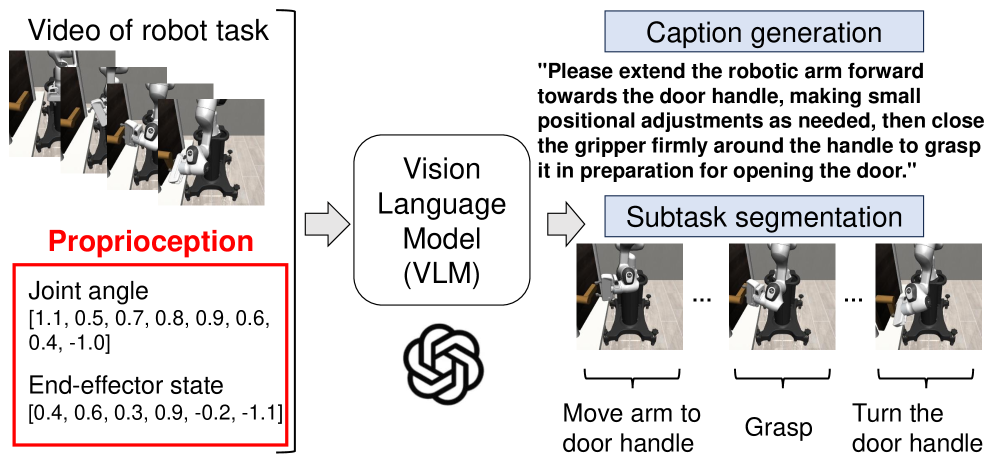
本文研究了仅使用离线数据(如图像和语言)训练的视觉语言模型(VLMs)是否能理解机器人运动,这对机器人技术的未来发展至关重要。由于VLMs的训练数据中不包含来自机器人的底层运动信息,因此包含轨迹信息的视频理解仍然是一个重大挑战。本研究通过一个包含底层机器人运动信息的视频描述任务,评估了VLMs的两项能力:(1)机器人任务的自动描述和(2)一系列任务的分割。这两项能力有望通过连接语言和运动来提高机器人模仿学习的效率,并作为衡量基础模型性能的指标。该方法利用图像描述和机器人任务的轨迹数据生成多个“场景”描述,然后通过总结这些单独的描述来生成完整的任务描述。此外,该方法通过比较图像描述的文本嵌入之间的相似性来执行子任务分割。在两个描述任务中,该方法旨在通过向VLM提供机器人的运动数据(关节和末端执行器状态)作为输入来提高性能。通过模拟器实验验证了该方法的有效性。
🔬 方法详解
问题定义:现有视觉语言模型(VLMs)在理解机器人任务视频时,主要依赖图像信息,忽略了机器人运动的底层信息(如关节状态、末端执行器轨迹等)。这导致VLMs难以准确描述机器人任务的细节,也难以进行子任务的有效分割。因此,如何将机器人运动信息有效地融入VLMs,提升其对机器人任务的理解能力,是本文要解决的核心问题。
核心思路:本文的核心思路是将机器人运动信息(关节状态和末端执行器状态)作为额外的输入,融入到视觉语言模型中。通过这种方式,VLM不仅可以利用图像信息,还可以利用机器人自身的运动信息,从而更全面地理解机器人任务。这种设计思路的合理性在于,机器人运动信息直接反映了机器人的操作意图和执行过程,是理解机器人任务的关键。
技术框架:该方法主要包含以下几个阶段:1) 视频帧提取和图像描述生成:对机器人任务视频进行帧提取,并使用图像描述模型为每一帧生成图像描述。2) 运动数据提取:提取机器人的关节状态和末端执行器状态等运动数据。3) 场景描述生成:将图像描述和运动数据融合,生成多个“场景”描述。4) 任务描述生成:通过总结这些单独的“场景”描述来生成完整的任务描述。5) 子任务分割:通过比较图像描述的文本嵌入之间的相似性来执行子任务分割。
关键创新:本文的关键创新在于将机器人运动信息融入到视觉语言模型中,从而提升了VLM对机器人任务的理解能力。与现有方法相比,本文的方法不仅利用了图像信息,还利用了机器人自身的运动信息,从而更全面地理解机器人任务。
关键设计:在场景描述生成阶段,如何有效地融合图像描述和运动数据是一个关键设计。具体实现细节未知,但可以推测可能采用注意力机制或者其他融合策略,使得VLM能够有效地利用运动信息。此外,子任务分割阶段,如何选择合适的文本嵌入模型以及如何设定相似度阈值也是需要仔细考虑的关键设计。
🖼️ 关键图片


📊 实验亮点
论文通过模拟器实验验证了所提方法的有效性。具体性能数据未知,但摘要中提到该方法旨在通过向VLM提供机器人的运动数据来提高性能,表明该方法在机器人任务的自动描述和子任务分割任务上均取得了较好的效果,优于未融合运动信息的基线方法。
🎯 应用场景
该研究成果可应用于机器人模仿学习、人机协作等领域。通过自动生成机器人任务的描述和子任务分割,可以降低机器人编程的难度,提高机器人学习的效率。此外,该技术还可以用于机器人故障诊断和远程控制等场景,具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
From the perspective of future developments in robotics, it is crucial to verify whether foundation models trained exclusively on offline data, such as images and language, can understand the robot motion. In particular, since Vision Language Models (VLMs) do not include low-level motion information from robots in their training datasets, video understanding including trajectory information remains a significant challenge. In this study, we assess two capabilities of VLMs through a video captioning task with low-level robot motion information: (1) automatic captioning of robot tasks and (2) segmentation of a series of tasks. Both capabilities are expected to enhance the efficiency of robot imitation learning by linking language and motion and serve as a measure of the foundation model's performance. The proposed method generates multiple "scene" captions using image captions and trajectory data from robot tasks. The full task caption is then generated by summarizing these individual captions. Additionally, the method performs subtask segmentation by comparing the similarity between text embeddings of image captions. In both captioning tasks, the proposed method aims to improve performance by providing the robot's motion data - joint and end-effector states - as input to the VLM. Simulator experiments were conducted to validate the effectiveness of the proposed method.