LoGoPlanner: Localization Grounded Navigation Policy with Metric-aware Visual Geometry
作者: Jiaqi Peng, Wenzhe Cai, Yuqiang Yang, Tai Wang, Yuan Shen, Jiangmiao Pang
分类: cs.RO, cs.CV
发布日期: 2025-12-22 (更新: 2025-12-23)
备注: Project page:https://steinate.github.io/logoplanner.github.io/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
LoGoPlanner:基于度量视觉几何的定位引导端到端导航策略
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting)
关键词: 端到端导航 视觉几何 度量学习 机器人定位 强化学习 自主导航 环境感知
📋 核心要点
- 传统导航方法依赖独立的定位模块,易受传感器标定误差影响,限制了跨平台和环境的泛化能力。
- LoGoPlanner通过微调视觉几何骨干网络,实现度量尺度预测,并重建场景几何,从而进行隐式状态估计和环境感知。
- 实验结果表明,LoGoPlanner在仿真和真实环境中均优于传统方法,且在不同机器人形态和环境中具有良好的泛化性。
📝 摘要(中文)
本文提出LoGoPlanner,一个定位引导的端到端导航框架,旨在解决移动机器人在非结构化环境中轨迹规划的挑战。该框架通过以下方式克服了传统模块化流程的延迟和误差累积问题:(1) 微调长时程视觉几何骨干网络,以绝对度量尺度进行预测,从而为精确定位提供隐式状态估计;(2) 从历史观测中重建周围场景几何,为可靠的避障提供密集、细粒度的环境感知;(3) 基于上述辅助任务引导的隐式几何来调节策略,从而减少误差传播。在仿真和真实世界环境中的评估表明,LoGoPlanner的完全端到端设计减少了累积误差,而度量感知几何记忆增强了规划一致性和避障能力,与oracle定位基线相比,性能提升超过27.3%,并在不同形态和环境中表现出强大的泛化能力。代码和模型已公开。
🔬 方法详解
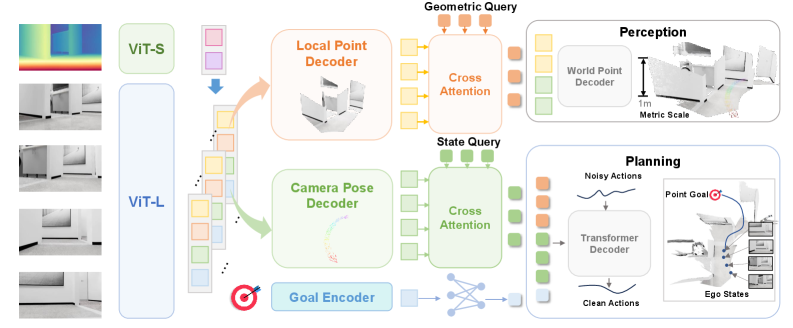
问题定义:现有移动机器人导航方法通常采用模块化流程,包括感知、定位、建图和规划等模块。这些模块之间存在延迟和误差累积,导致性能下降。此外,依赖于精确传感器外参标定的独立定位模块限制了系统在不同机器人平台和环境中的泛化能力。
核心思路:LoGoPlanner的核心思路是构建一个端到端的导航框架,该框架直接从原始视觉观测学习到控制信号或轨迹,无需显式的定位模块。通过引入度量感知的视觉几何学习,实现隐式的状态估计和环境感知,从而提高导航的准确性和鲁棒性。
技术框架:LoGoPlanner包含三个主要组成部分:(1) 长时程视觉几何骨干网络:用于从历史视觉观测中提取几何特征,并预测场景的度量尺度信息。(2) 几何重建模块:利用历史观测重建周围场景的几何信息,提供密集的、细粒度的环境感知。(3) 策略网络:基于隐式几何信息,学习导航策略,直接输出控制信号或轨迹。整个框架以端到端的方式进行训练。
关键创新:LoGoPlanner的关键创新在于将定位信息融入到端到端的导航框架中,通过学习度量感知的视觉几何表示,实现隐式的状态估计。与传统的依赖显式定位模块的方法相比,LoGoPlanner避免了误差累积和对传感器标定的依赖,提高了系统的鲁棒性和泛化能力。此外,利用历史观测进行几何重建,增强了环境感知能力,提高了避障的可靠性。
关键设计:长时程视觉几何骨干网络采用Transformer架构,用于学习视觉特征和时间依赖关系。几何重建模块使用深度学习方法,从历史观测中预测场景的深度图或点云。策略网络采用强化学习或模仿学习方法进行训练,目标是学习到最优的导航策略。损失函数包括几何重建损失、导航损失和正则化项,用于约束网络的学习。
🖼️ 关键图片


📊 实验亮点
LoGoPlanner在仿真和真实世界环境中进行了评估,实验结果表明,与依赖oracle定位的基线方法相比,LoGoPlanner的性能提升超过27.3%。此外,LoGoPlanner在不同机器人形态和环境中表现出强大的泛化能力,证明了其端到端设计和度量感知几何记忆的有效性。这些结果表明,LoGoPlanner是一种有前景的自主导航解决方案。
🎯 应用场景
LoGoPlanner具有广泛的应用前景,可应用于各种移动机器人平台,如自动驾驶汽车、无人机、服务机器人等。该研究成果有助于提升机器人在复杂、非结构化环境中的自主导航能力,降低对传感器标定的依赖,提高系统的鲁棒性和泛化能力。未来,该技术可应用于物流配送、安防巡检、环境监测等领域。
📄 摘要(原文)
Trajectory planning in unstructured environments is a fundamental and challenging capability for mobile robots. Traditional modular pipelines suffer from latency and cascading errors across perception, localization, mapping, and planning modules. Recent end-to-end learning methods map raw visual observations directly to control signals or trajectories, promising greater performance and efficiency in open-world settings. However, most prior end-to-end approaches still rely on separate localization modules that depend on accurate sensor extrinsic calibration for self-state estimation, thereby limiting generalization across embodiments and environments. We introduce LoGoPlanner, a localization-grounded, end-to-end navigation framework that addresses these limitations by: (1) finetuning a long-horizon visual-geometry backbone to ground predictions with absolute metric scale, thereby providing implicit state estimation for accurate localization; (2) reconstructing surrounding scene geometry from historical observations to supply dense, fine-grained environmental awareness for reliable obstacle avoidance; and (3) conditioning the policy on implicit geometry bootstrapped by the aforementioned auxiliary tasks, thereby reducing error propagation. We evaluate LoGoPlanner in both simulation and real-world settings, where its fully end-to-end design reduces cumulative error while metric-aware geometry memory enhances planning consistency and obstacle avoidance, leading to more than a 27.3\% improvement over oracle-localization baselines and strong generalization across embodiments and environments. The code and models have been made publicly available on the https://steinate.github.io/logoplanner.github.io.