LeLaR: The First In-Orbit Demonstration of an AI-Based Satellite Attitude Controller
作者: Kirill Djebko, Tom Baumann, Erik Dilger, Frank Puppe, Sergio Montenegro
分类: cs.RO, cs.AI, cs.LG, eess.SY
发布日期: 2025-12-22 (更新: 2026-01-16)
备注: This work has been submitted to the IEEE for possible publication. 55 pages, 27 figures, 29 tables. The maneuver telemetry datasets generated and analyzed during this work are available in the GitHub repository under https://github.com/kdjebko/lelar-in-orbit-data
💡 一句话要点
LeLaR:首次在轨演示基于AI的卫星姿态控制器,解决传统控制器的设计难题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 卫星姿态控制 深度强化学习 Sim2Real 在轨演示 AI控制器
📋 核心要点
- 传统卫星姿态控制器设计复杂,对模型误差和环境变化敏感,难以适应复杂任务。
- 利用深度强化学习在仿真环境中训练AI控制器,使其具备自适应能力,无需人工设计控制策略。
- 成功将仿真训练的AI控制器部署到真实卫星InnoCube上,并验证了其在轨姿态控制的有效性和鲁棒性。
📝 摘要(中文)
姿态控制对许多卫星任务至关重要。然而,经典控制器设计耗时,且对模型不确定性和运行边界条件的变化敏感。深度强化学习(DRL)通过与仿真环境的自主交互学习自适应控制策略,提供了一种有前景的替代方案。克服Sim2Real差距,即将仿真中训练的智能体部署到真实的物理卫星上,仍然是一个重大挑战。本文介绍了首次成功在轨演示基于AI的惯性指向机动姿态控制器。该控制器完全在仿真中训练,并部署到由维尔茨堡大学与柏林工业大学合作开发的InnoCube 3U纳米卫星上,该卫星于2025年1月发射。我们介绍了AI智能体设计、训练过程的方法、仿真与真实卫星观测行为之间的差异,以及基于AI的姿态控制器与InnoCube经典PD控制器的比较。稳态指标证实了基于AI的控制器在重复在轨机动期间的鲁棒性能。
🔬 方法详解
问题定义:论文旨在解决传统卫星姿态控制器的设计复杂性、对模型不确定性的敏感性以及对运行环境变化的适应性问题。现有方法需要耗时的手动设计和参数调整,难以应对复杂的任务需求和未知的环境变化。
核心思路:论文的核心思路是利用深度强化学习(DRL)训练一个AI控制器,使其能够通过与仿真环境的交互自主学习最优的控制策略。这种方法可以避免手动设计控制器的复杂过程,并使控制器具备自适应能力,从而更好地应对模型不确定性和环境变化。
技术框架:整体框架包括以下几个主要阶段:1) 仿真环境构建:构建一个尽可能逼真的卫星姿态控制仿真环境,包括卫星动力学模型、传感器模型和执行器模型。2) AI控制器设计:设计一个基于深度神经网络的AI控制器,该控制器以卫星的姿态和角速度作为输入,输出控制力矩。3) 强化学习训练:使用强化学习算法(具体算法未知)在仿真环境中训练AI控制器,使其学习到最优的姿态控制策略。4) Sim2Real迁移:将训练好的AI控制器部署到真实的卫星上,并进行在轨测试和验证。
关键创新:最重要的技术创新点是成功地将一个完全在仿真环境中训练的AI控制器部署到真实的卫星上,并实现了有效的姿态控制。这克服了Sim2Real的挑战,证明了DRL在卫星姿态控制领域的潜力。与传统方法相比,该方法无需手动设计控制器,且具备更强的自适应能力。
关键设计:论文中没有详细说明AI控制器的具体网络结构、损失函数和训练参数等技术细节。但是,可以推断,AI控制器可能采用了某种形式的深度神经网络,例如多层感知机(MLP)或循环神经网络(RNN),并使用强化学习算法(具体算法未知)进行训练。损失函数的设计可能考虑了姿态误差、角速度误差和控制力矩的约束。
🖼️ 关键图片
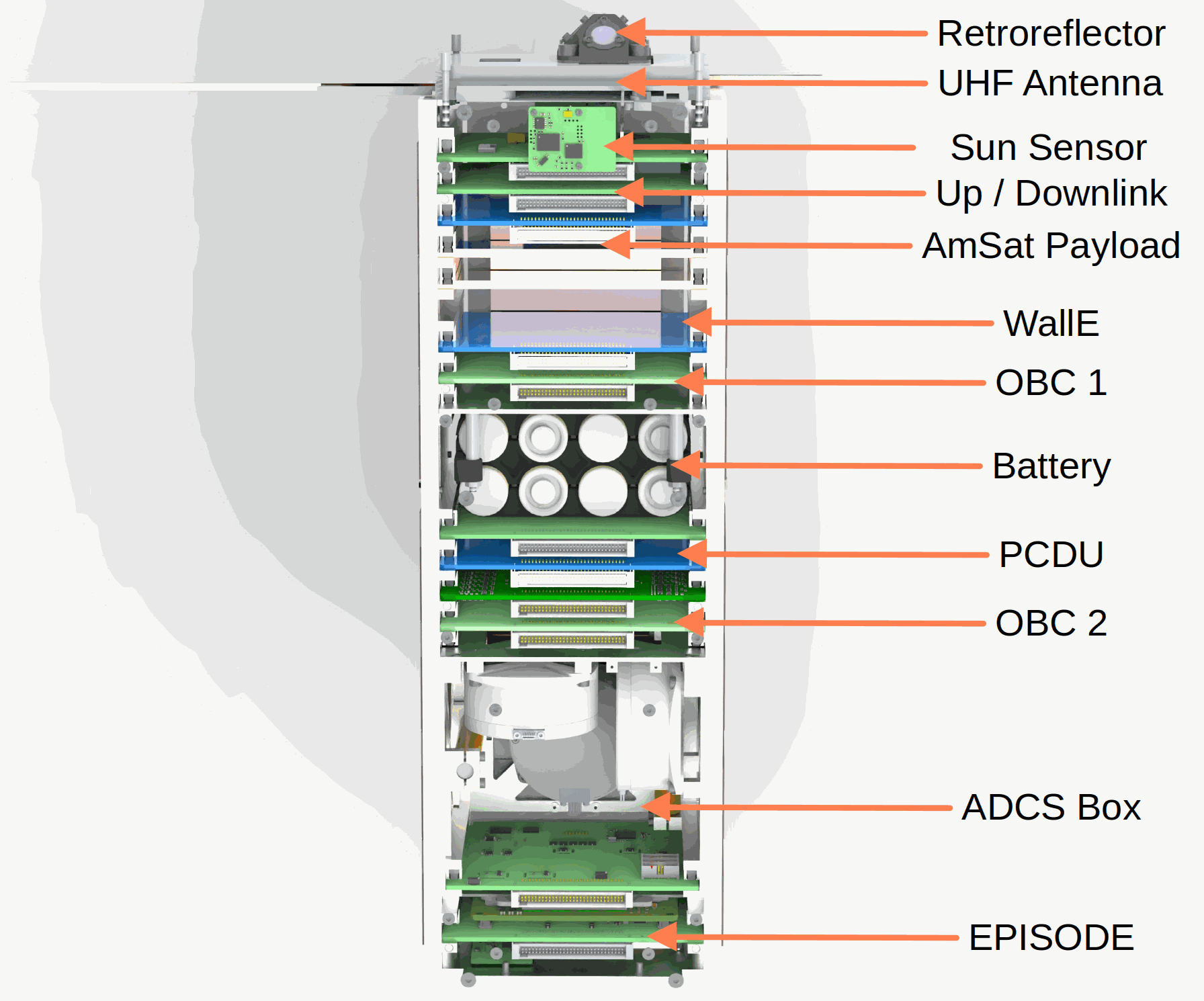
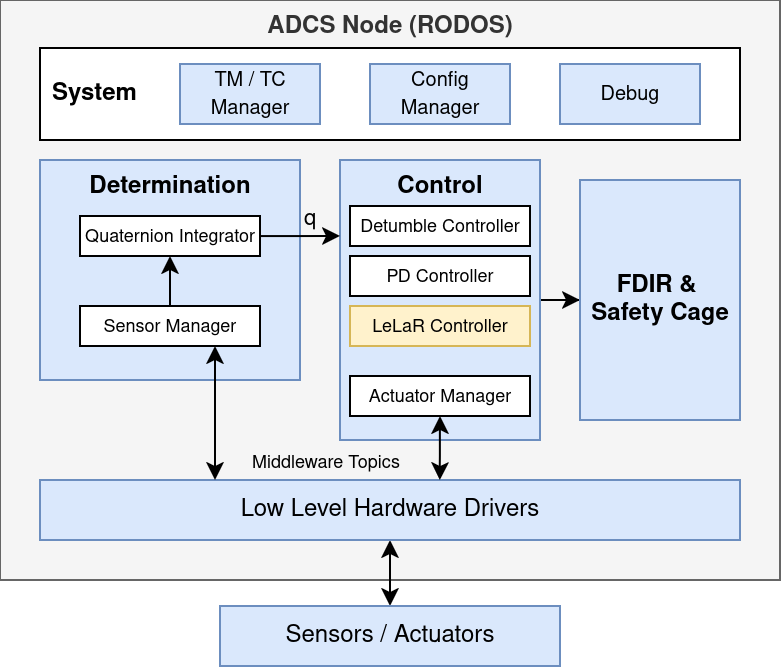

📊 实验亮点
该研究首次在轨演示了基于AI的卫星姿态控制器,验证了其在真实环境中的有效性和鲁棒性。通过与InnoCube的经典PD控制器进行比较,AI控制器在稳态性能方面表现出相当的水平,证明了其在实际应用中的潜力。具体的性能数据(例如姿态误差和稳定时间)未在摘要中给出,但强调了AI控制器在重复在轨机动中的鲁棒性。
🎯 应用场景
该研究成果可应用于各种需要精确姿态控制的卫星任务,例如遥感、通信和科学探测。基于AI的姿态控制器可以降低卫星控制系统的设计和维护成本,提高卫星的自主性和可靠性,并为未来的智能卫星发展奠定基础。此外,该研究在Sim2Real迁移方面的经验也为其他机器人和控制系统的AI应用提供了借鉴。
📄 摘要(原文)
Attitude control is essential for many satellite missions. Classical controllers, however, are time-consuming to design and sensitive to model uncertainties and variations in operational boundary conditions. Deep Reinforcement Learning (DRL) offers a promising alternative by learning adaptive control strategies through autonomous interaction with a simulation environment. Overcoming the Sim2Real gap, which involves deploying an agent trained in simulation onto the real physical satellite, remains a significant challenge. In this work, we present the first successful in-orbit demonstration of an AI-based attitude controller for inertial pointing maneuvers. The controller was trained entirely in simulation and deployed to the InnoCube 3U nanosatellite, which was developed by the Julius-Maximilians-Universität Würzburg in cooperation with the Technische Universität Berlin, and launched in January 2025. We present the AI agent design, the methodology of the training procedure, the discrepancies between the simulation and the observed behavior of the real satellite, and a comparison of the AI-based attitude controller with the classical PD controller of InnoCube. Steady-state metrics confirm the robust performance of the AI-based controller during repeated in-orbit maneuvers.