InDRiVE: Reward-Free World-Model Pretraining for Autonomous Driving via Latent Disagreement
作者: Feeza Khan Khanzada, Jaerock Kwon
分类: cs.RO
发布日期: 2025-12-21 (更新: 2025-12-27)
💡 一句话要点
InDRiVE:基于潜在差异的自动驾驶无奖励世界模型预训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 无奖励学习 世界模型 内在动机 强化学习
📋 核心要点
- 基于模型的强化学习依赖任务特定奖励,但奖励设计困难且易受分布偏移影响。
- InDRiVE利用潜在空间差异作为内在动机,引导智能体探索未知驾驶场景,实现无奖励预训练。
- 实验表明,InDRiVE在零样本迁移和少量样本适应方面表现出更强的鲁棒性,尤其是在避撞方面。
📝 摘要(中文)
本文提出InDRiVE,一种DreamerV3风格的基于模型的强化学习(MBRL)智能体,它在CARLA中使用仅从潜在集成差异导出的内在动机执行无奖励预训练。差异性作为认知不确定性的代理,驱动智能体探索未充分探索的驾驶场景,而基于想象的Actor-Critic直接从学习到的世界模型中学习无规划器的探索策略。在内在预训练之后,我们通过冻结所有参数并在未见过的城镇和路线上部署预训练的探索策略来评估零样本迁移。然后,我们研究通过使用有限的外部反馈训练下游目标(车道跟随和避撞)的任务策略来进行少量样本适应。在CARLA中跨城镇、路线和交通密度的实验表明,基于差异性的预训练在城镇转移和匹配的交互预算下,产生了更强的零样本鲁棒性和鲁棒的少量样本避撞,支持使用内在差异性作为可重用驾驶世界模型的实用无奖励预训练信号。
🔬 方法详解
问题定义:现有基于模型的强化学习方法在自动驾驶领域面临奖励函数设计的难题。奖励函数往往需要人工设计,难以泛化到新的环境和任务中,并且容易受到分布偏移的影响,导致性能下降。因此,如何设计一种无需人工奖励的、能够学习通用驾驶技能的预训练方法是亟待解决的问题。
核心思路:InDRiVE的核心思路是利用潜在空间中多个世界模型预测结果的差异性作为内在奖励信号。这种差异性反映了模型对当前状态的不确定性,智能体通过最大化这种不确定性来探索未知的驾驶场景,从而学习到更丰富的驾驶经验。这种方法无需人工设计奖励函数,能够自动地引导智能体进行有效的探索。
技术框架:InDRiVE采用DreamerV3的框架,包含一个世界模型和一个Actor-Critic网络。世界模型负责学习环境的动态特性,Actor-Critic网络负责学习驾驶策略。智能体首先在CARLA环境中进行无奖励预训练,利用潜在空间差异性作为内在奖励信号来训练世界模型和Actor-Critic网络。预训练完成后,智能体可以在新的环境和任务中进行零样本迁移或少量样本适应。
关键创新:InDRiVE的关键创新在于利用潜在空间差异性作为内在奖励信号进行无奖励预训练。与传统的基于人工奖励的强化学习方法相比,InDRiVE无需人工设计奖励函数,能够自动地引导智能体进行有效的探索。此外,InDRiVE还采用DreamerV3框架,能够有效地学习环境的动态特性和驾驶策略。
关键设计:InDRiVE使用多个世界模型集成,通过计算这些模型在潜在空间中的预测结果的方差来衡量差异性。差异性越大,表示模型对当前状态的不确定性越高。智能体通过最大化这种差异性来探索未知的驾驶场景。此外,InDRiVE还使用了一种基于想象的Actor-Critic算法,该算法通过在世界模型中进行rollout来学习驾驶策略。
🖼️ 关键图片
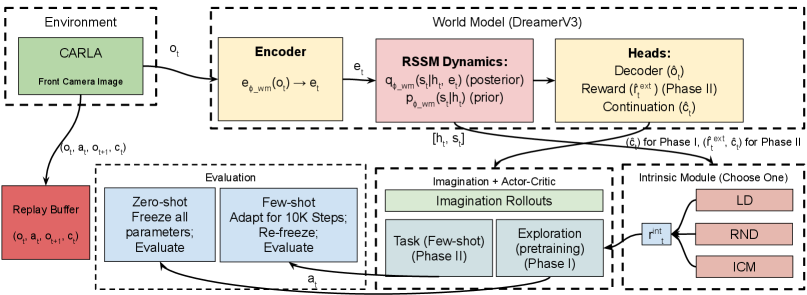
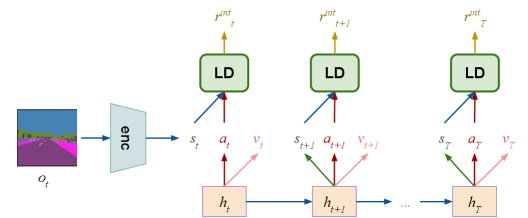
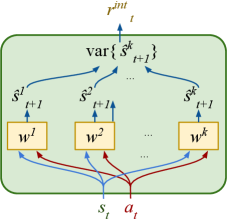
📊 实验亮点
实验结果表明,InDRiVE在CARLA模拟器中表现出强大的零样本迁移能力和少量样本适应能力。在城镇转移的情况下,InDRiVE在避撞方面表现出显著的鲁棒性。与没有预训练的模型相比,InDRiVE在少量样本学习中能够更快地适应新的任务。
🎯 应用场景
InDRiVE的研究成果可应用于自动驾驶领域的预训练任务,降低对人工标注数据的依赖,提升模型在复杂和未知环境中的泛化能力。该方法有望加速自动驾驶技术的研发和部署,并为其他机器人学习任务提供借鉴。
📄 摘要(原文)
Model-based reinforcement learning (MBRL) can reduce interaction cost for autonomous driving by learning a predictive world model, but it typically still depends on task-specific rewards that are difficult to design and often brittle under distribution shift. This paper presents InDRiVE, a DreamerV3-style MBRL agent that performs reward-free pretraining in CARLA using only intrinsic motivation derived from latent ensemble disagreement. Disagreement acts as a proxy for epistemic uncertainty and drives the agent toward under-explored driving situations, while an imagination-based actor-critic learns a planner-free exploration policy directly from the learned world model. After intrinsic pretraining, we evaluate zero-shot transfer by freezing all parameters and deploying the pretrained exploration policy in unseen towns and routes. We then study few-shot adaptation by training a task policy with limited extrinsic feedback for downstream objectives (lane following and collision avoidance). Experiments in CARLA across towns, routes, and traffic densities show that disagreement-based pretraining yields stronger zero-shot robustness and robust few-shot collision avoidance under town shift and matched interaction budgets, supporting the use of intrinsic disagreement as a practical reward-free pretraining signal for reusable driving world models.