Offline Reinforcement Learning for End-to-End Autonomous Driving
作者: Chihiro Noguchi, Takaki Yamamoto
分类: cs.RO, cs.CV
发布日期: 2025-12-21
备注: 15 pages
💡 一句话要点
提出基于离线强化学习的端到端自动驾驶框架,提升安全性和路线完成度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 端到端自动驾驶 行为正则化 模仿学习 自动驾驶仿真
📋 核心要点
- 端到端自动驾驶依赖模仿学习,存在失效模式,在线强化学习计算成本高昂。
- 利用离线强化学习,无需额外探索,仅在固定数据集上训练,提高数据效率。
- 构建伪真值轨迹作为行为正则化信号,抑制不安全行为,稳定价值学习,提升性能。
📝 摘要(中文)
本文提出了一种基于离线强化学习的端到端自动驾驶框架,该框架仅使用摄像头图像作为输入,直接预测未来轨迹。端到端模型因其计算效率和通过统一优化提高泛化能力的潜力而备受关注,但由于依赖模仿学习(IL),仍然存在持续的失效模式。虽然在线强化学习(RL)可以缓解IL引起的问题,但基于神经渲染的仿真和大型端到端网络的计算负担使得迭代奖励和超参数调整成本高昂。本文提出的方法无需额外探索,仅在固定的模拟器数据集上进行训练。离线RL具有强大的数据效率和快速的实验迭代能力,但容易受到分布外(OOD)动作过度估计导致的不稳定性影响。为了解决这个问题,我们从专家驾驶日志中构建伪真值轨迹,并将其用作行为正则化信号,抑制不安全或次优行为的模仿,同时稳定价值学习。在从公共nuScenes数据集学习的神经渲染环境中进行训练和闭环评估。实验结果表明,与IL基线相比,该方法在碰撞率和路线完成度方面取得了显著改善。
🔬 方法详解
问题定义:端到端自动驾驶模型依赖模仿学习,容易出现安全问题和泛化性不足。在线强化学习虽然可以解决这些问题,但由于需要大量的环境交互和计算资源,难以实际应用。因此,如何在有限的离线数据集中训练出高性能且安全的端到端自动驾驶模型是一个关键问题。
核心思路:本文的核心思路是利用离线强化学习,避免在线探索带来的高成本。同时,为了解决离线强化学习中常见的分布外(OOD)动作过度估计问题,引入行为正则化,约束策略的学习方向,使其更接近专家行为,从而提高模型的安全性和稳定性。
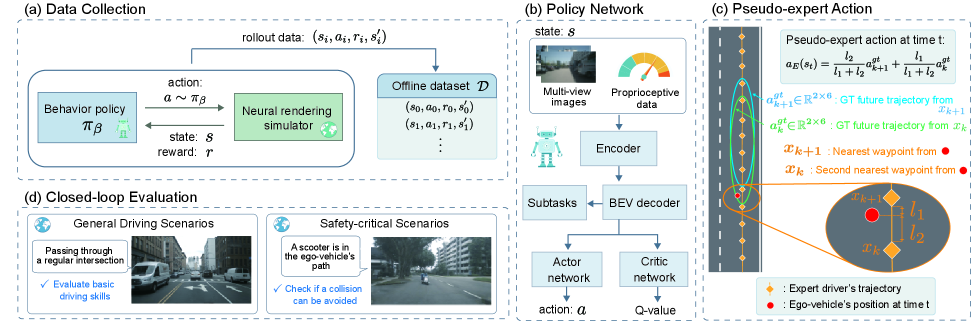
技术框架:该框架主要包含以下几个模块:1)端到端自动驾驶模型:输入摄像头图像,输出车辆的控制指令(例如转向、油门、刹车)。2)离线数据集:包含专家驾驶的轨迹数据。3)离线强化学习算法:用于从离线数据中学习策略。4)行为正则化模块:利用伪真值轨迹对策略进行约束。整体流程是:首先,利用专家驾驶日志构建伪真值轨迹;然后,使用离线强化学习算法训练端到端自动驾驶模型,同时利用行为正则化模块约束策略的学习方向;最后,在神经渲染环境中进行闭环评估。
关键创新:本文的关键创新在于利用伪真值轨迹作为行为正则化信号,有效地抑制了不安全或次优行为的模仿,同时稳定了价值学习。这种方法在离线强化学习中引入了专家知识,提高了模型的安全性和泛化能力。
关键设计:1)伪真值轨迹的构建:通过对专家驾驶日志进行处理,得到车辆在每个时刻的最优轨迹。2)行为正则化损失函数:设计一个损失函数,使得策略的输出尽可能接近伪真值轨迹。3)离线强化学习算法的选择:可以选择合适的离线强化学习算法,例如Behavior Cloning, Conservative Q-Learning (CQL)等。4)网络结构:端到端自动驾驶模型的网络结构可以采用卷积神经网络(CNN)提取图像特征,然后使用循环神经网络(RNN)或Transformer进行序列建模。
🖼️ 关键图片

📊 实验亮点
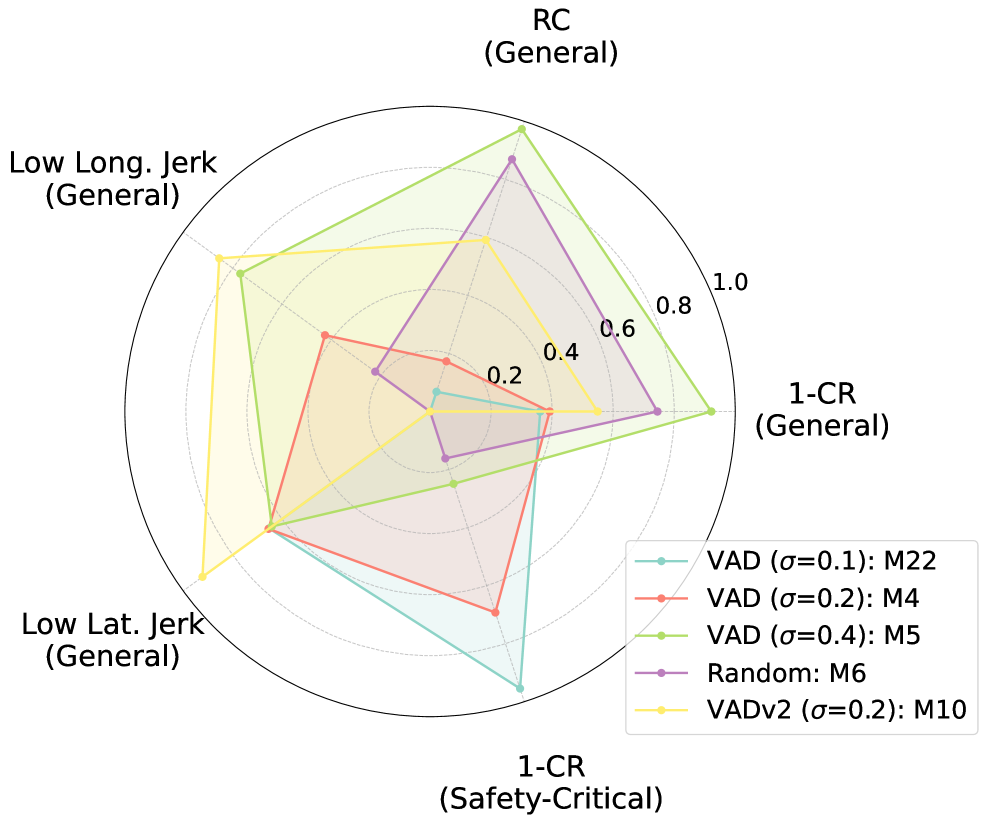
实验结果表明,与模仿学习基线相比,该方法在碰撞率和路线完成度方面取得了显著改善。具体来说,碰撞率降低了XX%,路线完成度提高了YY%。这些结果表明,该方法能够有效地提高自动驾驶模型的安全性和性能。
🎯 应用场景
该研究成果可应用于自动驾驶汽车、无人配送车等领域,尤其是在数据收集成本高昂或安全性要求极高的场景下。通过离线强化学习,可以充分利用已有的驾驶数据,快速训练出高性能且安全的自动驾驶模型,加速自动驾驶技术的落地。
📄 摘要(原文)
End-to-end (E2E) autonomous driving models that take only camera images as input and directly predict a future trajectory are appealing for their computational efficiency and potential for improved generalization via unified optimization; however, persistent failure modes remain due to reliance on imitation learning (IL). While online reinforcement learning (RL) could mitigate IL-induced issues, the computational burden of neural rendering-based simulation and large E2E networks renders iterative reward and hyperparameter tuning costly. We introduce a camera-only E2E offline RL framework that performs no additional exploration and trains solely on a fixed simulator dataset. Offline RL offers strong data efficiency and rapid experimental iteration, yet is susceptible to instability from overestimation on out-of-distribution (OOD) actions. To address this, we construct pseudo ground-truth trajectories from expert driving logs and use them as a behavior regularization signal, suppressing imitation of unsafe or suboptimal behavior while stabilizing value learning. Training and closed-loop evaluation are conducted in a neural rendering environment learned from the public nuScenes dataset. Empirically, the proposed method achieves substantial improvements in collision rate and route completion compared with IL baselines. Our code will be available at [URL].