STORM: Search-Guided Generative World Models for Robotic Manipulation
作者: Wenjun Lin, Jensen Zhang, Kaitong Cai, Keze Wang
分类: cs.RO, cs.CV
发布日期: 2025-12-20
备注: Under submission
💡 一句话要点
STORM:面向机器人操作的搜索引导生成世界模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 生成世界模型 扩散模型 蒙特卡洛树搜索 视觉-语言-动作模型 时空推理 视频预测
📋 核心要点
- 现有VLA模型依赖抽象潜在空间或语言组件进行推理,缺乏可解释性和前瞻性。
- STORM通过扩散模型生成动作,世界模型预测结果,MCTS搜索优化,实现视觉展开中的规划。
- 实验表明,STORM在机器人操作任务中超越现有方法,并具备强大的重新规划和故障恢复能力。
📝 摘要(中文)
本文提出了一种名为STORM(搜索引导生成世界模型)的新框架,用于机器人操作中的时空推理,它统一了基于扩散的动作生成、条件视频预测和基于搜索的规划。与依赖抽象潜在动态或将推理委托给语言组件的先前视觉-语言-动作(VLA)模型不同,STORM将规划建立在显式的视觉展开中,从而实现可解释的和具有前瞻性的决策。基于扩散的VLA策略提出多样化的候选动作,生成式视频世界模型模拟它们的视觉和奖励结果,蒙特卡洛树搜索(MCTS)通过前瞻评估选择性地细化计划。在SimplerEnv操作基准上的实验表明,STORM实现了51.0%的平均成功率,优于CogACT等强大的基线。奖励增强的视频预测显著提高了时空保真度和任务相关性,将Frechet视频距离降低了75%以上。此外,STORM表现出强大的重新规划和故障恢复能力,突出了搜索引导生成世界模型在长时程机器人操作中的优势。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在机器人操作任务中,通常依赖于抽象的潜在动态或将推理过程委托给语言组件,这导致了模型缺乏可解释性,难以进行有效的长时程规划,并且在面对意外情况时缺乏鲁棒性。这些方法难以充分利用视觉信息进行精确的预测和决策。
核心思路:STORM的核心思路是将规划过程显式地建立在视觉展开(visual rollouts)中。通过生成式世界模型预测动作的视觉结果,并利用搜索算法(蒙特卡洛树搜索)对潜在的行动序列进行评估和优化。这种方法使得模型能够进行前瞻性的决策,并具备更好的可解释性和鲁棒性。
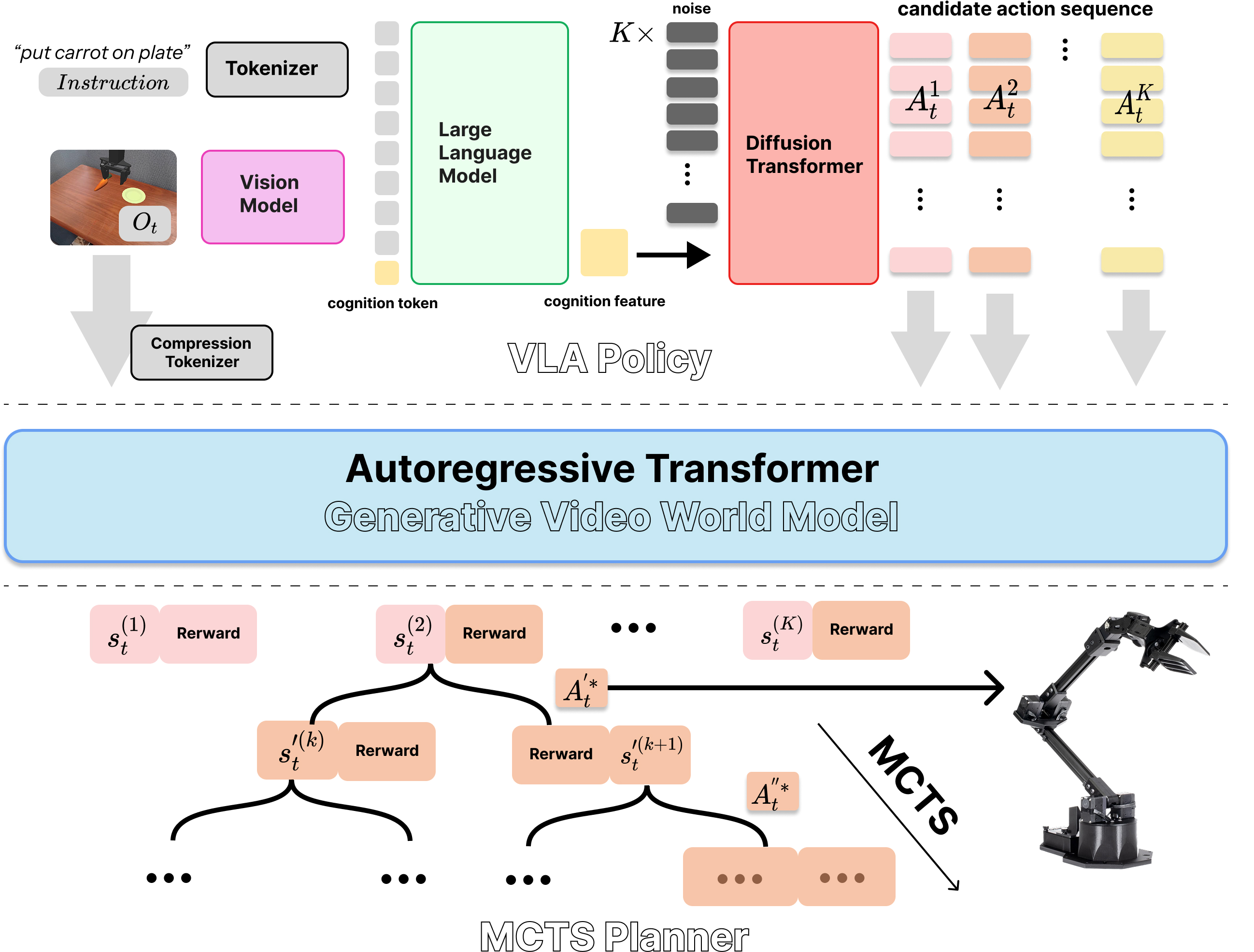
技术框架:STORM框架包含三个主要模块:1) 基于扩散的VLA策略:用于生成多样化的候选动作。2) 生成式视频世界模型:用于模拟动作的视觉和奖励结果。该模型以当前状态和动作作为输入,预测下一时刻的视觉状态和奖励。3) 蒙特卡洛树搜索(MCTS):用于通过前瞻评估选择性地细化计划。MCTS利用世界模型进行模拟,并根据模拟结果更新节点价值,最终选择最优的动作序列。
关键创新:STORM的关键创新在于将生成式世界模型与搜索算法相结合,实现了基于视觉展开的规划。与传统的VLA模型相比,STORM能够更有效地利用视觉信息进行推理和决策,并且具备更好的可解释性和鲁棒性。奖励增强的视频预测是另一个重要的创新,它显著提高了时空保真度和任务相关性。
关键设计:扩散模型用于生成动作,其损失函数旨在最大化生成动作的多样性,同时保证动作的有效性。世界模型采用条件变分自编码器(CVAE)结构,并使用对抗训练来提高生成视频的真实感。奖励预测模块与视频预测模块联合训练,以提高奖励预测的准确性。MCTS的搜索策略采用UCT(Upper Confidence Bound applied to Trees)算法,并根据任务特点进行调整。
🖼️ 关键图片


📊 实验亮点
STORM在SimplerEnv操作基准测试中取得了51.0%的平均成功率,超越了CogACT等基线方法。奖励增强的视频预测将Frechet视频距离降低了75%以上,显著提高了时空保真度和任务相关性。实验还表明,STORM具备强大的重新规划和故障恢复能力。
🎯 应用场景
STORM框架可应用于各种机器人操作任务,例如物体抓取、装配、导航等。该研究的实际价值在于提高了机器人操作的智能化水平和鲁棒性,使其能够更好地适应复杂和动态的环境。未来,该技术有望应用于智能制造、自动驾驶、家庭服务等领域。
📄 摘要(原文)
We present STORM (Search-Guided Generative World Models), a novel framework for spatio-temporal reasoning in robotic manipulation that unifies diffusion-based action generation, conditional video prediction, and search-based planning. Unlike prior Vision-Language-Action (VLA) models that rely on abstract latent dynamics or delegate reasoning to language components, STORM grounds planning in explicit visual rollouts, enabling interpretable and foresight-driven decision-making. A diffusion-based VLA policy proposes diverse candidate actions, a generative video world model simulates their visual and reward outcomes, and Monte Carlo Tree Search (MCTS) selectively refines plans through lookahead evaluation. Experiments on the SimplerEnv manipulation benchmark demonstrate that STORM achieves a new state-of-the-art average success rate of 51.0 percent, outperforming strong baselines such as CogACT. Reward-augmented video prediction substantially improves spatio-temporal fidelity and task relevance, reducing Frechet Video Distance by over 75 percent. Moreover, STORM exhibits robust re-planning and failure recovery behavior, highlighting the advantages of search-guided generative world models for long-horizon robotic manipulation.