AOMGen: Photoreal, Physics-Consistent Demonstration Generation for Articulated Object Manipulation
作者: Yulu Wu, Jiujun Cheng, Haowen Wang, Dengyang Suo, Pei Ren, Qichao Mao, Shangce Gao, Yakun Huang
分类: cs.RO
发布日期: 2025-12-20
💡 一句话要点
AOMGen:用于铰接物体操作的逼真、物理一致的演示数据生成框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 铰接物体操作 数据生成 视觉-语言-动作 机器人学习 物理仿真 合成数据 VLA策略 泛化能力
📋 核心要点
- 视觉-语言-动作(VLA)模型在机器人操作等任务中表现出色,但依赖于大量真实演示数据,尤其是在精细操作铰接物体时。
- AOMGen框架通过单个真实扫描和数字资产库,生成逼真且物理一致的铰接物体操作数据,有效降低了数据收集成本。
- 实验表明,使用AOMGen生成的数据微调VLA策略,显著提升了铰接物体操作的成功率,并在新物体和场景中表现出良好的泛化能力。
📝 摘要(中文)
本文提出AOMGen,一个可扩展的数据生成框架,用于铰接物体操作。该框架仅需单个真实扫描、演示以及易于获取的数字资产库,即可生成具有验证物理状态的逼真训练数据。AOMGen合成与动作命令时间对齐的多视角RGB图像,以及关节和接触点的状态标注,并系统地改变相机视角、物体风格和物体姿态,将单个执行过程扩展为多样化的数据集。实验结果表明,在AOMGen数据上微调VLA策略可将成功率从0%提高到88.7%,并且这些策略在未见过的物体和布局上进行了测试。
🔬 方法详解
问题定义:现有VLA方法在铰接物体操作任务中需要大量真实演示数据进行训练,而收集这些数据成本高昂,特别是对于精细操作。现有方法难以在不同物体风格、视角和姿态下泛化,限制了其在实际场景中的应用。
核心思路:AOMGen的核心思路是利用单个真实扫描、演示和数字资产库,通过程序化生成大量逼真且物理一致的合成数据。通过系统地改变相机视角、物体风格和物体姿态,可以有效地扩展数据集的多样性,从而提高VLA策略的泛化能力。
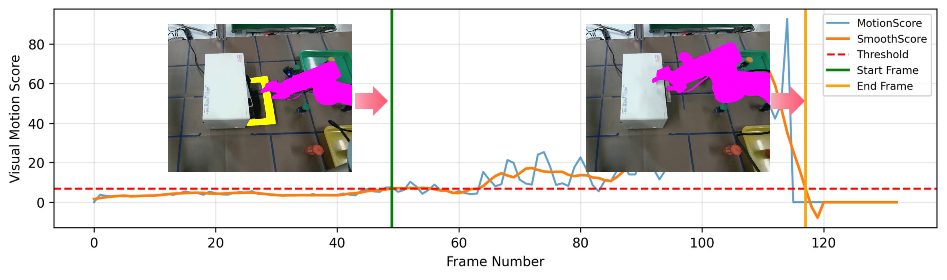
技术框架:AOMGen框架包含以下主要模块:1) 基于单个真实扫描和演示构建初始场景;2) 从数字资产库中选择不同的物体风格;3) 随机改变相机视角和物体姿态;4) 使用物理引擎模拟铰接物体的运动,并生成与动作命令时间对齐的多视角RGB图像和状态标注(关节角度、接触点等);5) 将生成的数据用于训练或微调VLA策略。
关键创新:AOMGen的关键创新在于其能够仅使用少量真实数据和数字资产,生成大量逼真且物理一致的铰接物体操作数据。与传统的完全依赖真实数据或简单合成数据的方法相比,AOMGen在数据质量和生成效率之间取得了更好的平衡。
关键设计:AOMGen使用物理引擎来保证生成数据的物理一致性,例如,确保铰接物体的运动符合物理规律,接触点的位置合理。此外,AOMGen还设计了一系列参数来控制相机视角、物体姿态和物体风格的变化范围,以确保生成数据的多样性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在AOMGen数据上微调VLA策略可将铰接物体操作的成功率从0%提高到88.7%。此外,经过AOMGen数据训练的策略在未见过的物体和布局上表现出良好的泛化能力,证明了AOMGen生成数据的有效性。
🎯 应用场景
AOMGen可广泛应用于机器人操作、虚拟现实、游戏开发等领域。通过生成大量高质量的训练数据,可以显著降低机器人学习的成本,提高机器人在复杂环境中的操作能力。此外,AOMGen还可以用于生成逼真的虚拟环境,用于训练和测试人工智能算法。
📄 摘要(原文)
Recent advances in Vision-Language-Action (VLA) and world-model methods have improved generalization in tasks such as robotic manipulation and object interaction. However, Successful execution of such tasks depends on large, costly collections of real demonstrations, especially for fine-grained manipulation of articulated objects. To address this, we present AOMGen, a scalable data generation framework for articulated manipulation which is instantiated from a single real scan, demonstration and a library of readily available digital assets, yielding photoreal training data with verified physical states. The framework synthesizes synchronized multi-view RGB temporally aligned with action commands and state annotations for joints and contacts, and systematically varies camera viewpoints, object styles, and object poses to expand a single execution into a diverse corpus. Experimental results demonstrate that fine-tuning VLA policies on AOMGen data increases the success rate from 0% to 88.7%, and the policies are tested on unseen objects and layouts.