Dynamic Entropy Tuning in Reinforcement Learning Low-Level Quadcopter Control: Stochasticity vs Determinism
作者: Youssef Mahran, Zeyad Gamal, Ayman El-Badawy
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-12-20
备注: This is the Author Accepted Manuscript version of a paper accepted for publication. The final published version is available via IEEE Xplore
期刊: 2024 IEEE 34th International Conference on Computer Theory and Applications (ICCTA)
DOI: 10.1109/ICCTA64612.2024.10974880
💡 一句话要点
提出基于动态熵调整的强化学习四旋翼控制方法,提升探索效率并避免灾难性遗忘。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 四旋翼控制 动态熵调整 SAC算法 TD3算法 自主飞行 机器人控制
📋 核心要点
- 现有强化学习方法在四旋翼控制中存在探索效率低和容易发生灾难性遗忘的问题。
- 该论文提出了一种基于动态熵调整的强化学习方法,旨在平衡探索与利用,从而提升控制性能。
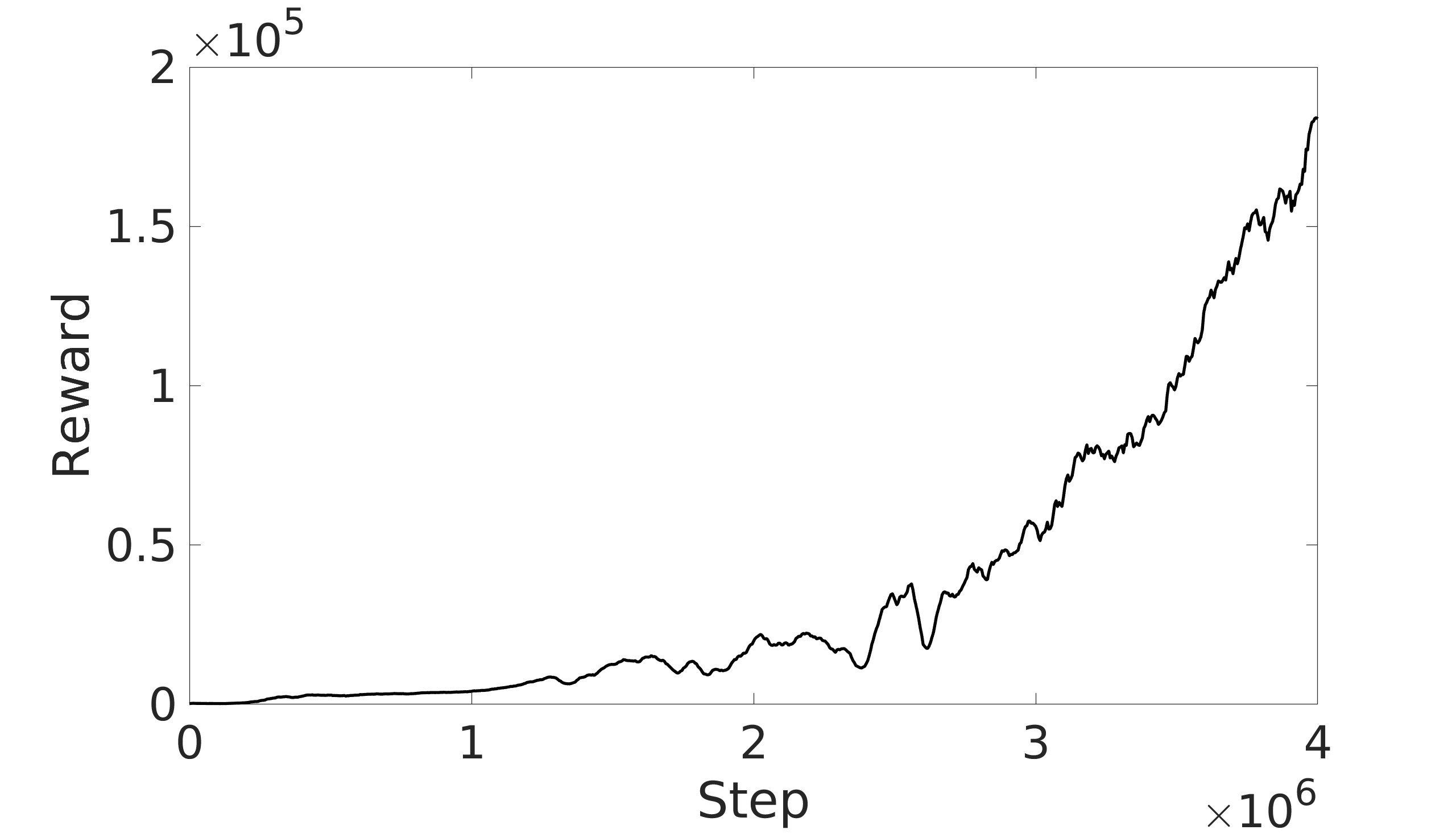
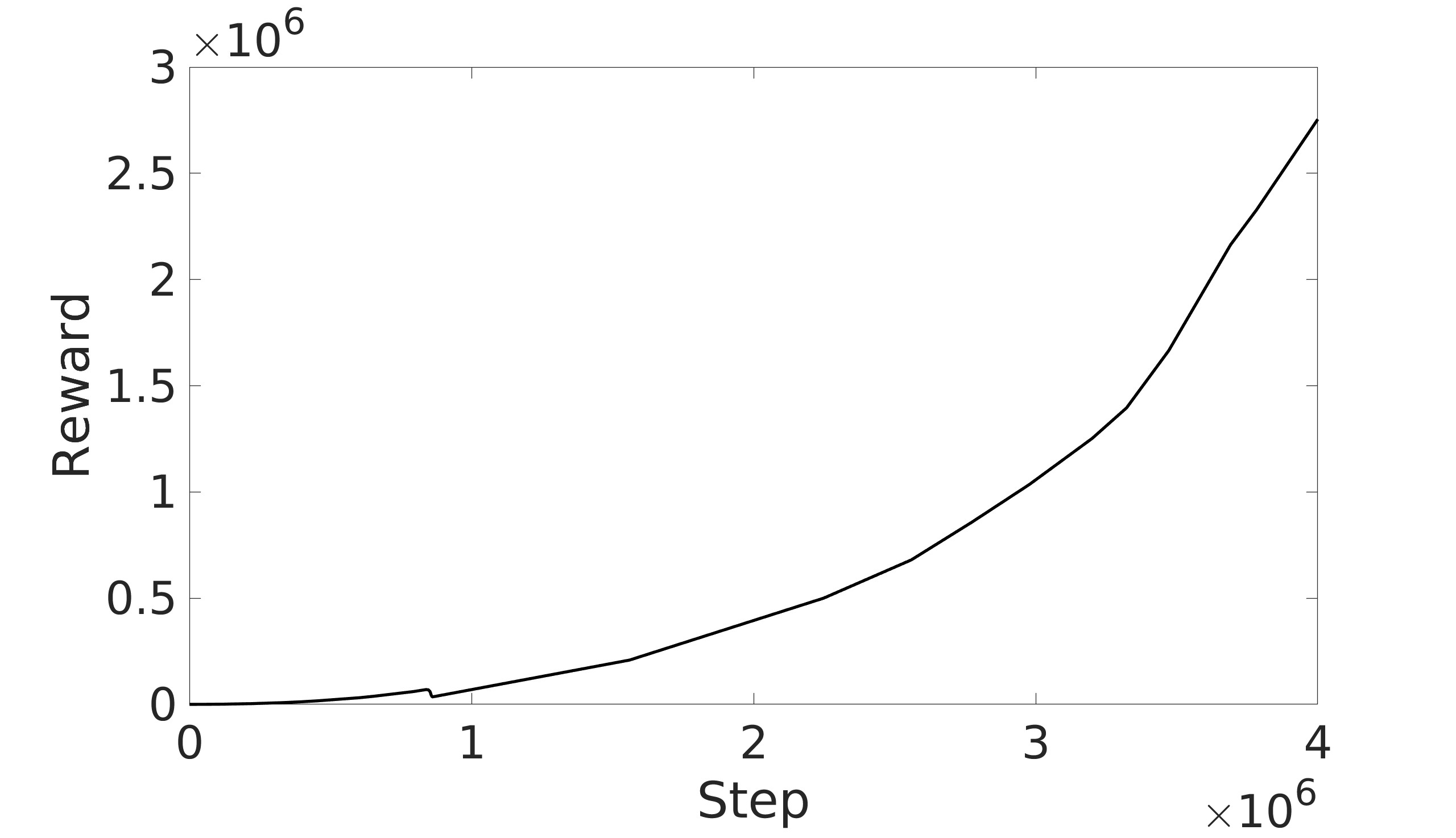
- 实验结果表明,动态熵调整能够有效防止灾难性遗忘,并显著提高四旋翼控制的探索效率。
📝 摘要(中文)
本文探讨了动态熵调整在训练随机策略的强化学习(RL)算法中的影响。将其性能与训练确定性策略的算法进行了比较。随机策略优化动作上的概率分布以最大化奖励,而确定性策略为每个状态选择单个确定性动作。研究了训练具有静态熵和动态熵的随机策略,然后执行确定性动作来控制四旋翼飞行器的效果。然后,将其与训练确定性策略并执行确定性动作进行比较。为了研究的目的,选择软演员-评论家(SAC)算法作为随机算法,而选择双延迟深度确定性策略梯度(TD3)作为确定性算法。训练和仿真结果表明,动态熵调整对控制四旋翼飞行器具有积极作用,可以防止灾难性遗忘并提高探索效率。
🔬 方法详解
问题定义:论文旨在解决四旋翼飞行器控制中,传统强化学习方法在探索效率和稳定性方面的不足。具体来说,现有方法容易陷入局部最优,导致探索效率低下,并且在训练过程中容易发生灾难性遗忘,影响控制性能。
核心思路:论文的核心思路是通过动态调整熵值,平衡强化学习中的探索(exploration)和利用(exploitation)。熵值越高,策略的随机性越强,有利于探索未知状态空间;熵值越低,策略的确定性越强,有利于利用已知知识获取更高奖励。动态调整熵值可以在训练过程中自适应地调整探索和利用的比例,从而提高学习效率和稳定性。
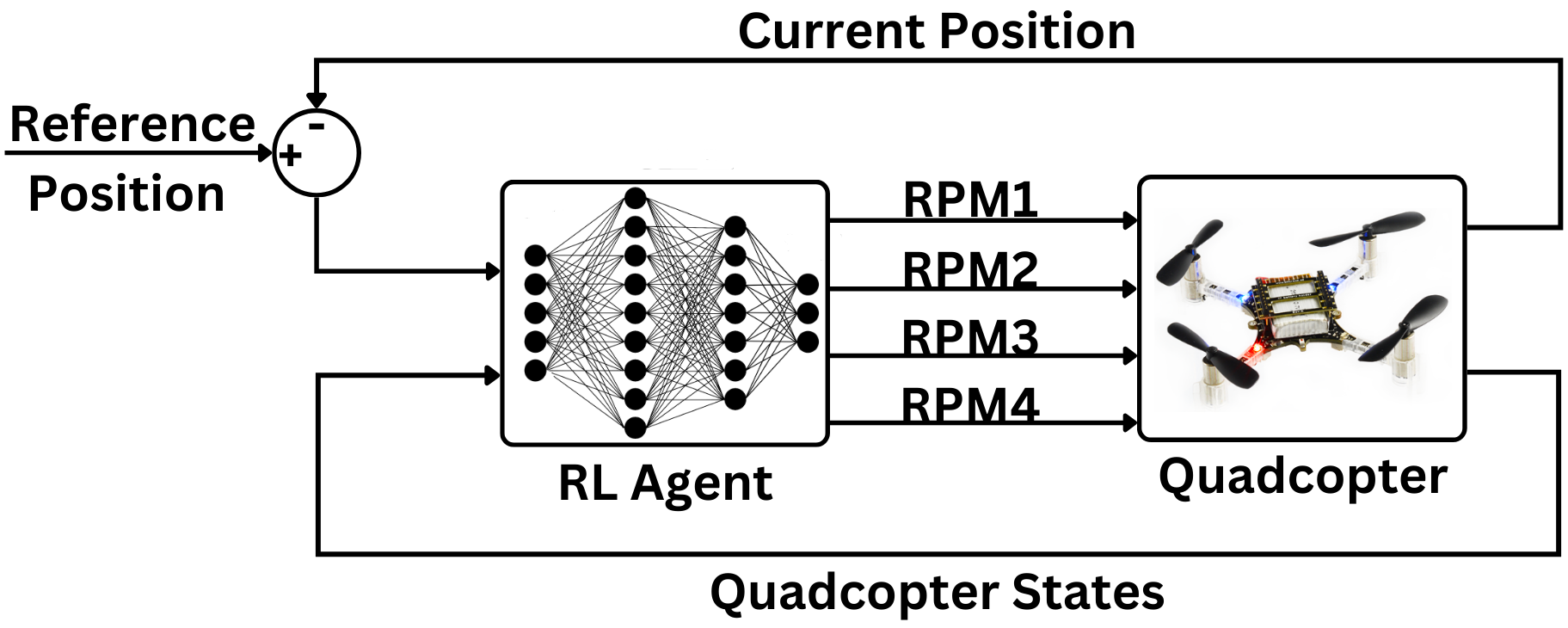
技术框架:整体框架包括使用强化学习算法(SAC和TD3)训练四旋翼飞行器的控制策略。SAC算法用于训练随机策略,TD3算法用于训练确定性策略。关键在于SAC算法中熵值的动态调整机制。训练完成后,将学习到的策略部署到四旋翼飞行器上进行仿真验证。
关键创新:论文的关键创新在于将动态熵调整机制引入到四旋翼飞行器的强化学习控制中。与传统的静态熵值方法相比,动态熵调整能够根据训练过程中的状态自适应地调整熵值,从而更好地平衡探索和利用。这使得算法能够更快地找到最优策略,并避免陷入局部最优。
关键设计:SAC算法中的熵值调整通常基于当前策略的熵值和期望奖励。具体实现中,可以设置一个目标熵值,然后根据当前熵值与目标熵值的差异来调整熵值的学习率。损失函数通常包括策略梯度损失、Q函数损失和熵正则化项。网络结构方面,SAC算法通常采用Actor-Critic架构,Actor网络用于生成策略,Critic网络用于评估策略的价值。
🖼️ 关键图片
📊 实验亮点
实验结果表明,采用动态熵调整的SAC算法在四旋翼控制任务中表现优于静态熵的SAC算法和TD3算法。动态熵调整能够显著提高探索效率,并有效防止灾难性遗忘。具体性能数据(例如,奖励曲线、控制精度等)需要在论文中查找。
🎯 应用场景
该研究成果可应用于无人机自主飞行、机器人控制等领域。通过动态熵调整,可以提高无人机在复杂环境中的自主导航和避障能力,降低对人工干预的依赖。此外,该方法还可以推广到其他需要平衡探索与利用的强化学习任务中,具有广泛的应用前景。
📄 摘要(原文)
This paper explores the impact of dynamic entropy tuning in Reinforcement Learning (RL) algorithms that train a stochastic policy. Its performance is compared against algorithms that train a deterministic one. Stochastic policies optimize a probability distribution over actions to maximize rewards, while deterministic policies select a single deterministic action per state. The effect of training a stochastic policy with both static entropy and dynamic entropy and then executing deterministic actions to control the quadcopter is explored. It is then compared against training a deterministic policy and executing deterministic actions. For the purpose of this research, the Soft Actor-Critic (SAC) algorithm was chosen for the stochastic algorithm while the Twin Delayed Deep Deterministic Policy Gradient (TD3) was chosen for the deterministic algorithm. The training and simulation results show the positive effect the dynamic entropy tuning has on controlling the quadcopter by preventing catastrophic forgetting and improving exploration efficiency.