Reinforcement Learning Position Control of a Quadrotor Using Soft Actor-Critic (SAC)
作者: Youssef Mahran, Zeyad Gamal, Ayman El-Badawy
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-12-20
备注: This is the Author Accepted Manuscript version of a paper accepted for publication. The final published version is available via IEEE Xplore
期刊: 2024 IEEE 6th Novel Intelligent and Leading Emerging Sciences Conference (NILES)
DOI: 10.1109/NILES63360.2024.10753187
💡 一句话要点
提出基于软演员-评论家算法的四旋翼推力矢量强化学习位置控制方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四旋翼 强化学习 软演员-评论家算法 推力矢量控制 位置控制
📋 核心要点
- 现有四旋翼控制方法主要集中于直接控制电机转速,控制过程复杂且训练时间较长。
- 本文提出一种基于强化学习的推力矢量控制方法,直接控制推力大小和横滚、俯仰角,简化控制流程。
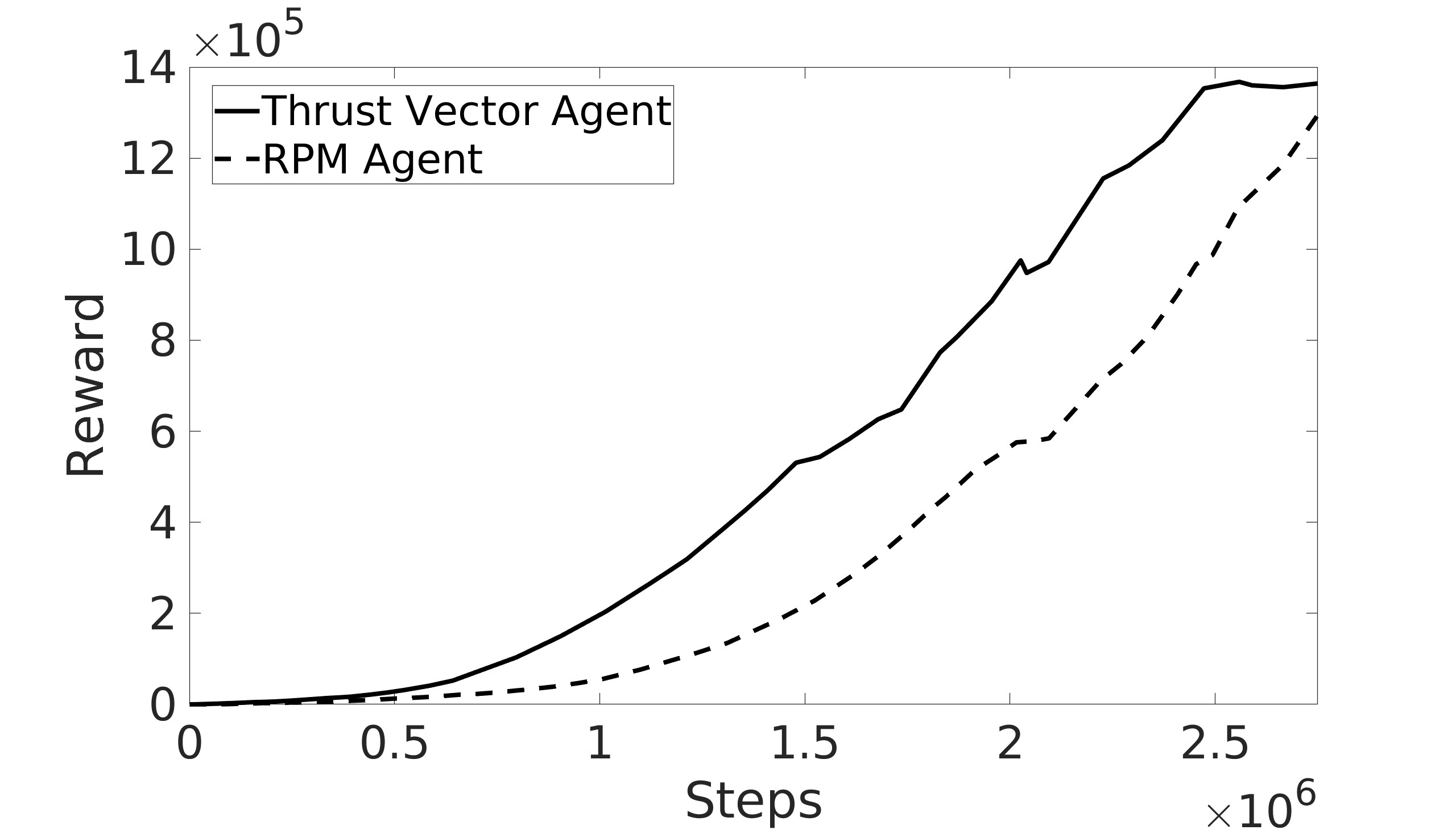
- 实验结果表明,相比于传统的转速控制方法,该方法训练速度更快,路径跟踪更加平滑和精确。
📝 摘要(中文)
本文提出了一种新的基于强化学习(RL)的四旋翼控制架构。与现有文献主要集中于直接控制四个旋翼的转速(RPM)不同,本文旨在控制四旋翼的推力矢量。强化学习智能体计算沿四旋翼z轴的总推力百分比以及期望的横滚角(φ)和俯仰角(θ)。然后,智能体将计算出的控制信号以及当前四旋翼的偏航角(ψ)发送到姿态PID控制器。PID控制器随后将控制信号映射到电机转速。采用软演员-评论家(SAC)算法,一种无模型的离策略随机强化学习算法来训练强化学习智能体。训练结果表明,与传统的RPM控制器相比,所提出的推力矢量控制器具有更快的训练时间。仿真结果表明,所提出的推力矢量控制器具有更平滑和更精确的路径跟踪性能。
🔬 方法详解
问题定义:现有四旋翼控制方法通常直接控制四个电机的转速,这种方法控制维度高,参数调整复杂,训练难度大,难以实现快速和精确的控制。尤其是在复杂环境中,需要更高级的控制策略。
核心思路:本文的核心思路是将控制目标从电机转速转换为直接控制四旋翼的推力矢量,即控制推力的大小和方向。通过强化学习智能体直接输出推力百分比以及期望的横滚角和俯仰角,从而简化控制过程,降低控制难度。
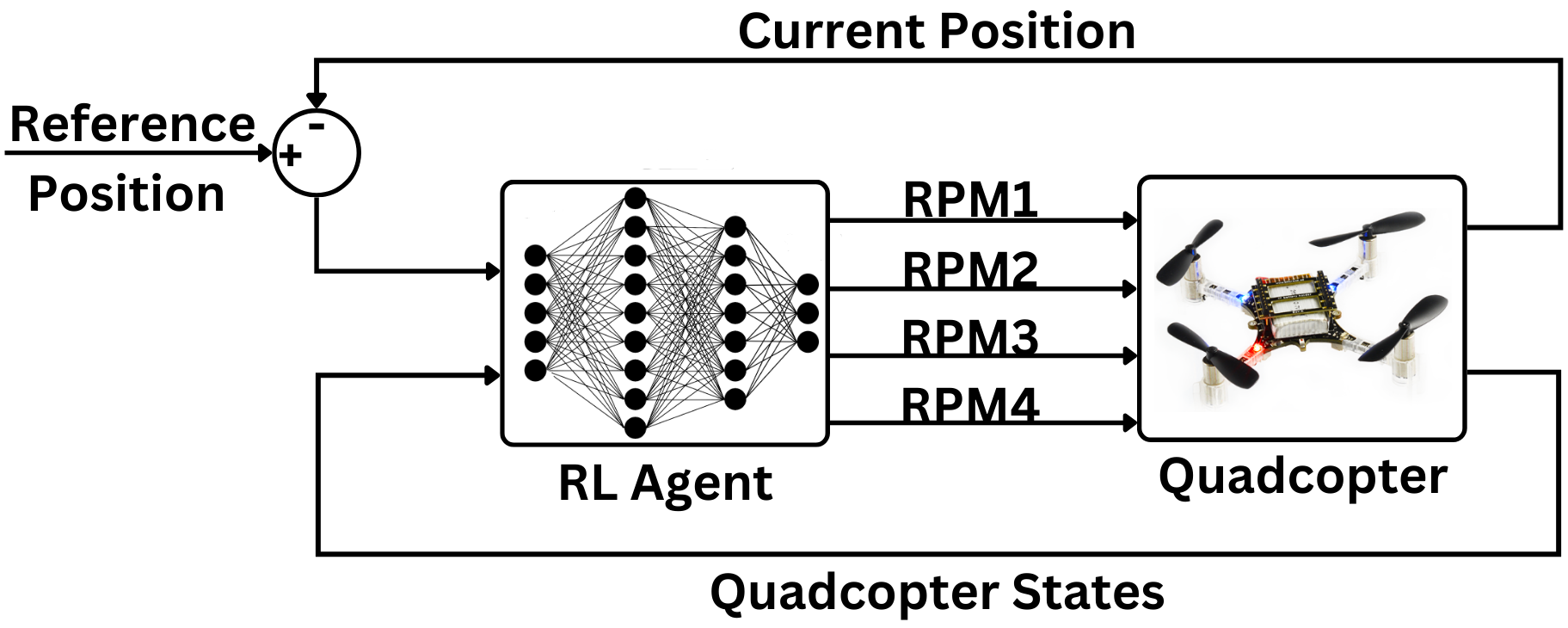
技术框架:整体框架包括强化学习智能体和姿态PID控制器。强化学习智能体使用软演员-评论家(SAC)算法进行训练,输入为四旋翼的状态信息(例如位置、速度、姿态角),输出为推力百分比、期望横滚角和期望俯仰角。然后,这些控制信号连同当前的偏航角一起被送入姿态PID控制器,PID控制器负责将这些信号转换为四个电机的转速。
关键创新:最重要的创新点在于控制变量的选择。传统方法控制电机转速,而本文直接控制推力矢量,降低了控制的维度,简化了控制逻辑。此外,使用SAC算法,一种离策略的强化学习算法,可以提高训练的稳定性和效率。
关键设计:SAC算法中的奖励函数需要精心设计,以引导智能体学习到期望的行为。例如,奖励函数可以包括与目标位置的距离、速度误差、姿态误差等。此外,SAC算法中的温度参数(alpha)也需要仔细调整,以平衡探索和利用。
🖼️ 关键图片

📊 实验亮点
实验结果表明,与传统的基于转速控制的强化学习方法相比,本文提出的基于推力矢量控制的方法训练时间显著缩短,路径跟踪的平滑性和精度也得到了提高。具体性能数据未在摘要中给出,但强调了在训练速度和控制精度上的优势。
🎯 应用场景
该研究成果可应用于无人机自主导航、精准物流、环境监测、灾害救援等领域。通过强化学习实现对四旋翼飞行器的精确控制,使其能够在复杂环境中完成各种任务,具有重要的实际应用价值和广阔的发展前景。未来可以进一步研究在真实环境中的应用,例如加入视觉信息,实现更鲁棒的控制。
📄 摘要(原文)
This paper proposes a new Reinforcement Learning (RL) based control architecture for quadrotors. With the literature focusing on controlling the four rotors' RPMs directly, this paper aims to control the quadrotor's thrust vector. The RL agent computes the percentage of overall thrust along the quadrotor's z-axis along with the desired Roll ($φ$) and Pitch ($θ$) angles. The agent then sends the calculated control signals along with the current quadrotor's Yaw angle ($ψ$) to an attitude PID controller. The PID controller then maps the control signals to motor RPMs. The Soft Actor-Critic algorithm, a model-free off-policy stochastic RL algorithm, was used to train the RL agents. Training results show the faster training time of the proposed thrust vector controller in comparison to the conventional RPM controllers. Simulation results show smoother and more accurate path-following for the proposed thrust vector controller.