LLaViDA: A Large Language Vision Driving Assistant for Explicit Reasoning and Enhanced Trajectory Planning
作者: Yudong Liu, Spencer Hallyburton, Jiwoo Kim, Yueqian Lin, Yiming Li, Qinsi Wang, Hui Ye, Jingwei Sun, Miroslav Pajic, Yiran Chen, Hai Li
分类: cs.RO, cs.AI
发布日期: 2025-12-20
💡 一句话要点
提出LLaViDA,利用视觉语言模型增强自动驾驶轨迹规划的推理能力。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 轨迹规划 视觉语言模型 VLM 思维链推理 NuScenes 轨迹偏好优化
📋 核心要点
- 端到端轨迹规划器在恶劣天气和复杂路况下泛化能力不足,缺乏对训练数据之外场景的few-shot能力。
- LLaViDA利用VLM进行目标运动预测、语义对齐和思维链推理,从而提升自动驾驶轨迹规划的性能。
- 通过监督微调和轨迹偏好优化,LLaViDA在NuScenes测试集上取得了优异的轨迹规划效果,显著降低了轨迹误差和碰撞率。
📝 摘要(中文)
本文提出了一种名为LLaViDA的大型语言视觉驾驶助手,它利用视觉语言模型(VLM)进行目标运动预测、语义对齐以及用于自动驾驶轨迹规划的思维链推理。通过一个两阶段的训练流程——监督微调和轨迹偏好优化(TPO),该方法通过注入基于回归的监督来增强场景理解和轨迹规划,从而产生一个强大的“用于自动驾驶的VLM轨迹规划器”。在NuScenes基准测试中,LLaViDA在开放循环轨迹规划任务中超越了最先进的端到端方法和其他基于VLM/LLM的基线,在NuScenes测试集上实现了0.31米的平均L2轨迹误差和0.10%的碰撞率。
🔬 方法详解
问题定义:自动驾驶中的轨迹规划是一个关键但具有挑战性的问题。现有的端到端规划器在面对复杂场景(如恶劣天气、不确定的人类行为或复杂的道路布局)时,由于缺乏足够的泛化能力和少样本学习能力,表现往往不佳。这些方法难以有效利用场景中的语义信息进行推理,导致规划出的轨迹不够安全和合理。
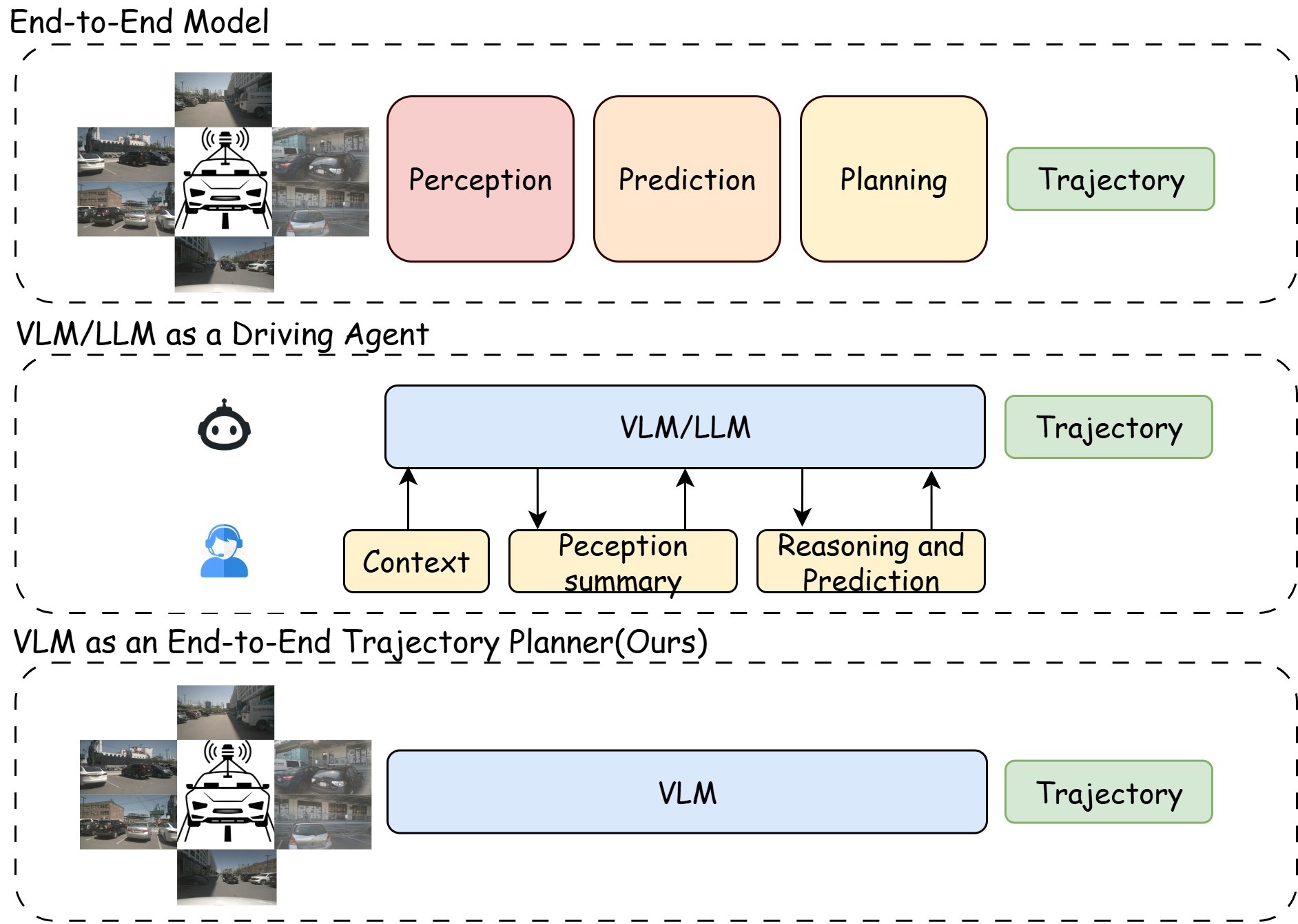
核心思路:LLaViDA的核心思路是利用大型视觉语言模型(VLM)的强大能力,将视觉感知和语言推理相结合,从而更好地理解驾驶场景并生成更优的轨迹。通过VLM,模型可以预测场景中物体的运动,进行语义对齐,并进行链式思考推理,从而做出更明智的决策。
技术框架:LLaViDA的整体框架包含以下几个主要模块:1) 视觉感知模块:用于从摄像头图像中提取场景信息。2) 视觉语言模型(VLM):用于将视觉信息与语言信息对齐,并进行推理。3) 轨迹规划模块:基于VLM的输出,生成车辆的轨迹。该方法采用两阶段训练流程:首先进行监督微调,然后进行轨迹偏好优化(TPO)。
关键创新:LLaViDA的关键创新在于将VLM引入到自动驾驶的轨迹规划中,并设计了一个有效的两阶段训练流程。与传统的端到端方法相比,LLaViDA能够更好地利用场景中的语义信息进行推理,从而提高轨迹规划的性能。与其他的基于VLM/LLM的方法相比,LLaViDA通过轨迹偏好优化,能够更好地学习人类驾驶员的驾驶习惯,从而生成更自然的轨迹。
关键设计:在训练过程中,LLaViDA使用了回归损失函数来监督VLM的学习,使其能够准确预测场景中物体的运动。轨迹偏好优化(TPO)则通过比较不同轨迹的优劣,来学习人类驾驶员的驾驶习惯。具体的网络结构和参数设置在论文中有详细描述,但摘要中未提供具体细节。
🖼️ 关键图片


📊 实验亮点
LLaViDA在NuScenes基准测试中取得了显著的成果,超越了现有的最先进方法。在开放循环轨迹规划任务中,LLaViDA在NuScenes测试集上实现了0.31米的平均L2轨迹误差和0.10%的碰撞率。相较于其他基于VLM/LLM的基线方法,LLaViDA在轨迹规划的准确性和安全性方面均有显著提升。
🎯 应用场景
LLaViDA具有广泛的应用前景,可用于提高自动驾驶系统的安全性和可靠性。该技术可以应用于各种自动驾驶车辆,包括乘用车、卡车和无人巴士。此外,LLaViDA还可以用于辅助驾驶系统,帮助驾驶员更好地理解驾驶场景并做出更明智的决策。未来,该技术有望在智慧交通领域发挥重要作用。
📄 摘要(原文)
Trajectory planning is a fundamental yet challenging component of autonomous driving. End-to-end planners frequently falter under adverse weather, unpredictable human behavior, or complex road layouts, primarily because they lack strong generalization or few-shot capabilities beyond their training data. We propose LLaViDA, a Large Language Vision Driving Assistant that leverages a Vision-Language Model (VLM) for object motion prediction, semantic grounding, and chain-of-thought reasoning for trajectory planning in autonomous driving. A two-stage training pipeline--supervised fine-tuning followed by Trajectory Preference Optimization (TPO)--enhances scene understanding and trajectory planning by injecting regression-based supervision, produces a powerful "VLM Trajectory Planner for Autonomous Driving." On the NuScenes benchmark, LLaViDA surpasses state-of-the-art end-to-end and other recent VLM/LLM-based baselines in open-loop trajectory planning task, achieving an average L2 trajectory error of 0.31 m and a collision rate of 0.10% on the NuScenes test set. The code for this paper is available at GitHub.