On Swarm Leader Identification using Probing Policies
作者: Stergios E. Bachoumas, Panagiotis Artemiadis
分类: cs.RO, cs.AI, cs.MA
发布日期: 2025-12-20
备注: 13 pages, journal
💡 一句话要点
提出基于交互式探测的群体机器人领导者识别方法,解决对抗环境下的领导者隐藏问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 群体机器人 领导者识别 深度强化学习 图神经网络 时间图关系转换器 近端策略优化 零样本泛化 交互式探测
📋 核心要点
- 现有群体机器人领导者识别方法在对抗环境中存在不足,难以应对领导者隐藏的情况。
- 论文提出交互式探测方法,通过物理交互获取信息,利用深度强化学习训练探测策略。
- 实验表明,该方法在仿真和真实机器人环境中均表现良好,具有零样本泛化能力和鲁棒性。
📝 摘要(中文)
本文提出交互式群体领导者识别(iSLI)问题,即对抗探测智能体通过与群体成员的物理交互来识别领导者。我们将iSLI问题建模为部分可观测马尔可夫决策过程(POMDP),并采用深度强化学习,特别是近端策略优化(PPO)来训练探测器的策略。该方法使用一种新颖的神经网络架构,包含时间图关系转换器(TGR)层和简化的结构化状态空间序列(S5)模型。TGR层有效地处理群体的图结构观测,捕获时间依赖性,并使用学习到的门控机制融合关系信息,从而为策略学习生成信息丰富的表示。大量仿真表明,基于TGR的模型优于基线图神经网络架构,并在不同于训练的群体大小和速度下表现出显著的零样本泛化能力。训练后的探测器在识别领导者方面实现了高精度,即使在训练分布之外的场景中也能保持性能,并在其预测中表现出适当的置信度。使用物理机器人的真实实验进一步验证了该方法,证实了成功的sim-to-real迁移和对动态变化的鲁棒性,例如意外的智能体断开连接。
🔬 方法详解
问题定义:论文旨在解决对抗环境下群体机器人领导者的识别问题。现有方法通常依赖于被动观察,难以应对领导者刻意隐藏身份的情况。探测智能体需要主动与群体成员交互,通过物理接触等方式获取信息,从而推断出领导者的身份。
核心思路:核心思路是将领导者识别问题建模为部分可观测马尔可夫决策过程(POMDP),并利用深度强化学习训练一个探测智能体。该智能体通过与群体成员的交互,收集观测信息,并根据当前状态选择下一步的探测动作,最终目标是准确识别出领导者。这种主动探测的方式能够有效应对领导者的隐藏行为。
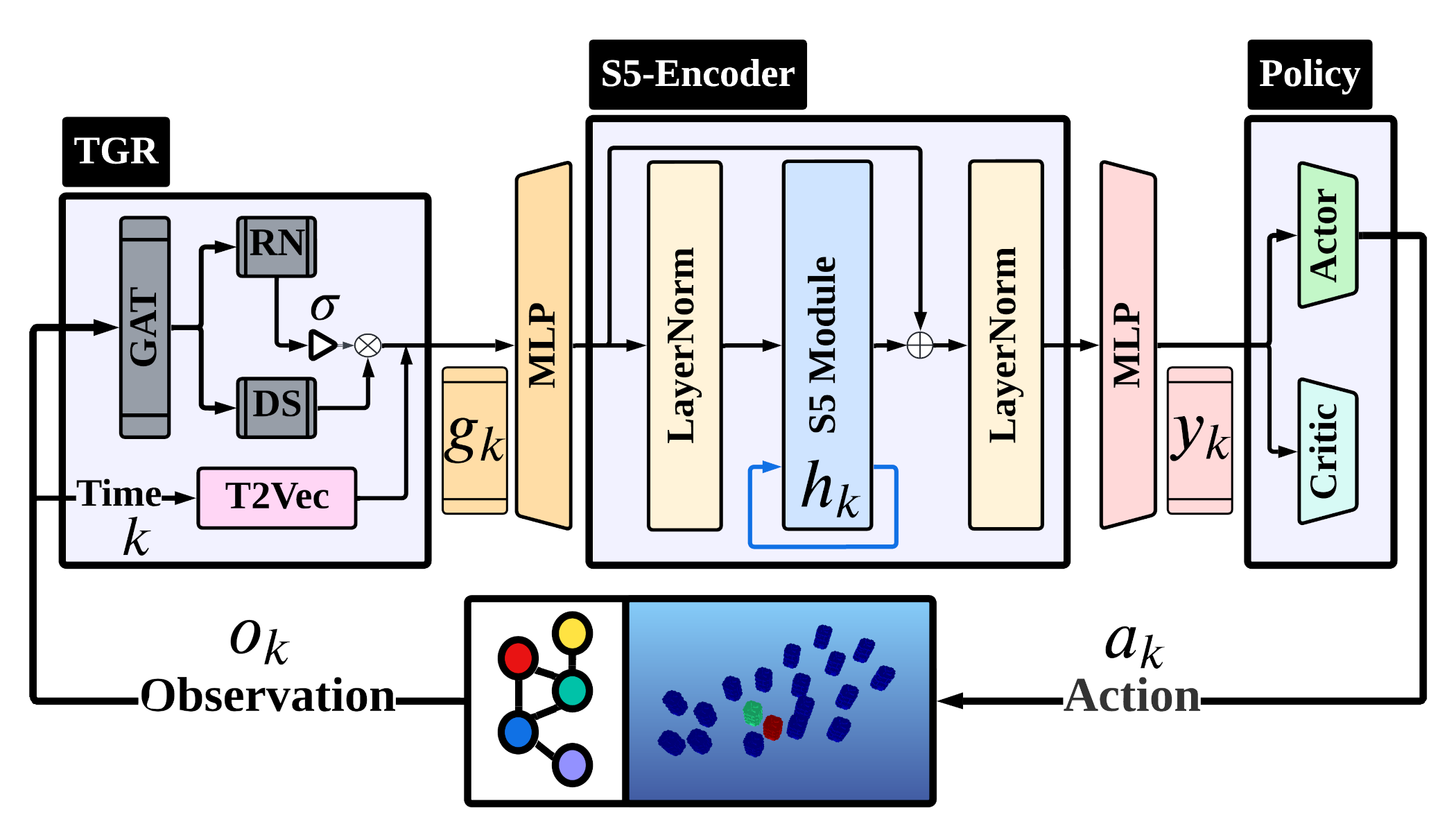
技术框架:整体框架包含一个群体机器人环境和一个探测智能体。群体机器人环境模拟了群体成员的运动和交互,以及领导者的隐藏行为。探测智能体通过神经网络学习策略,根据环境观测选择探测动作。神经网络的核心模块包括时间图关系转换器(TGR)层和简化的结构化状态空间序列(S5)模型。TGR层用于处理群体成员之间的关系信息,S5模型用于处理时间序列数据。
关键创新:最重要的创新点在于提出了时间图关系转换器(TGR)层,用于处理群体机器人之间的关系信息。TGR层能够有效地捕获群体成员之间的空间和时间依赖性,并利用学习到的门控机制融合关系信息,从而为策略学习提供更丰富的特征表示。与传统的图神经网络相比,TGR层能够更好地处理动态变化的群体关系。
关键设计:TGR层采用多头注意力机制,每个头关注不同的关系特征。门控机制用于控制不同关系特征的融合比例。S5模型采用简化的结构,降低了计算复杂度。损失函数采用近端策略优化(PPO)算法,用于优化探测智能体的策略。实验中,群体大小和速度等参数在训练和测试阶段进行了变化,以评估模型的泛化能力。
🖼️ 关键图片

📊 实验亮点
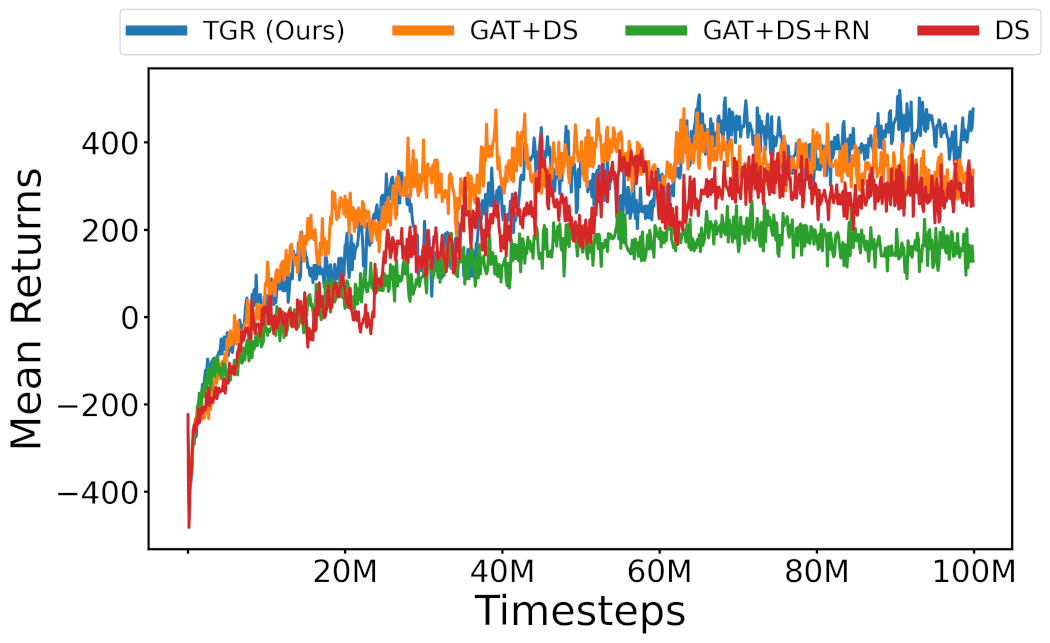
实验结果表明,基于TGR的模型在仿真环境中优于基线图神经网络架构,并在不同于训练的群体大小和速度下表现出显著的零样本泛化能力。在真实机器人实验中,该方法成功实现了sim-to-real迁移,并对动态变化(如智能体断开连接)表现出鲁棒性。探测器在识别领导者方面实现了高精度,即使在训练分布之外的场景中也能保持性能。
🎯 应用场景
该研究成果可应用于搜索救援、环境监测、目标追踪等领域。在这些场景中,群体机器人需要协同工作,而识别领导者对于协调行动至关重要。该方法能够提高群体机器人在复杂环境下的适应性和鲁棒性,增强其完成任务的能力。未来可进一步研究多领导者识别、动态环境下的领导者切换等问题。
📄 摘要(原文)
Identifying the leader within a robotic swarm is crucial, especially in adversarial contexts where leader concealment is necessary for mission success. This work introduces the interactive Swarm Leader Identification (iSLI) problem, a novel approach where an adversarial probing agent identifies a swarm's leader by physically interacting with its members. We formulate the iSLI problem as a Partially Observable Markov Decision Process (POMDP) and employ Deep Reinforcement Learning, specifically Proximal Policy Optimization (PPO), to train the prober's policy. The proposed approach utilizes a novel neural network architecture featuring a Timed Graph Relationformer (TGR) layer combined with a Simplified Structured State Space Sequence (S5) model. The TGR layer effectively processes graph-based observations of the swarm, capturing temporal dependencies and fusing relational information using a learned gating mechanism to generate informative representations for policy learning. Extensive simulations demonstrate that our TGR-based model outperforms baseline graph neural network architectures and exhibits significant zero-shot generalization capabilities across varying swarm sizes and speeds different from those used during training. The trained prober achieves high accuracy in identifying the leader, maintaining performance even in out-of-training distribution scenarios, and showing appropriate confidence levels in its predictions. Real-world experiments with physical robots further validate the approach, confirming successful sim-to-real transfer and robustness to dynamic changes, such as unexpected agent disconnections.