Robotic VLA Benefits from Joint Learning with Motion Image Diffusion
作者: Yu Fang, Kanchana Ranasinghe, Le Xue, Honglu Zhou, Juntao Tan, Ran Xu, Shelby Heinecke, Caiming Xiong, Silvio Savarese, Daniel Szafir, Mingyu Ding, Michael S. Ryoo, Juan Carlos Niebles
分类: cs.RO, cs.CV
发布日期: 2025-12-19
备注: Website: https://vla-motion.github.io/
💡 一句话要点
提出基于运动图像扩散的联合学习方法,提升机器人VLA模型的运动推理能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉语言动作模型 运动推理 扩散模型 联合学习
📋 核心要点
- 现有VLA模型缺乏预测性的运动推理能力,限制了其在复杂机器人操作任务中的表现。
- 提出一种基于运动图像扩散的联合学习策略,通过预测光流运动图像来增强VLA模型的运动推理能力。
- 实验结果表明,该方法在仿真和真实环境中均能显著提升VLA模型的成功率,尤其是在真实环境中提升了23%。
📝 摘要(中文)
视觉-语言-动作(VLA)模型通过将多模态观测和指令直接映射到动作,在机器人操作领域取得了显著进展。然而,它们通常模仿专家轨迹,缺乏预测性的运动推理,限制了其动作决策能力。为了解决这一局限性,我们提出了一种基于运动图像扩散的联合学习策略,以增强VLA模型的运动推理能力。我们的方法通过双头设计扩展了VLA架构:动作头预测动作块,而运动头(Diffusion Transformer, DiT)预测基于光流的运动图像,捕捉未来动态。两个头联合训练,使共享的VLM骨干网络学习将机器人控制与运动知识相结合的表征。这种联合学习构建了时间连贯且物理上合理的表征,同时保持了标准VLA的推理延迟。在仿真和真实环境中的实验表明,基于运动图像扩散的联合学习将pi-series VLA在LIBERO基准测试中的成功率提高到97.5%,在RoboTwin基准测试中提高到58.0%,真实环境性能提升了23%,验证了其增强大规模VLA运动推理能力的有效性。
🔬 方法详解
问题定义:现有VLA模型主要通过模仿学习,直接将视觉、语言信息映射到动作,缺乏对未来运动轨迹的预测和推理能力。这导致模型在面对复杂或未知的环境时,难以做出合理的动作决策,泛化能力受限。现有方法的痛点在于缺乏对运动信息的有效建模和利用。
核心思路:论文的核心思路是将动作预测与运动预测相结合,通过联合学习的方式,让VLA模型能够同时学习动作控制和运动推理。具体来说,模型不仅预测下一步的动作,还预测未来一段时间内的运动图像(光流),从而显式地建模运动信息。这样设计的目的是让模型能够理解动作与运动之间的关系,从而做出更合理的动作决策。
技术框架:该方法在现有的VLA架构上增加了一个运动头,形成一个双头结构。整个框架包含以下几个主要模块:1) 共享的VLM骨干网络:用于提取视觉和语言特征;2) 动作头:用于预测动作序列;3) 运动头(Diffusion Transformer, DiT):用于预测光流运动图像。训练过程中,动作头和运动头联合训练,共享VLM骨干网络的参数。推理时,只使用动作头进行动作预测,保持了推理效率。
关键创新:最重要的技术创新点在于将扩散模型(Diffusion Transformer)引入到VLA模型中,用于预测运动图像。与直接预测动作相比,预测运动图像能够更全面地捕捉未来动态,提供更丰富的运动信息。此外,联合学习的方式使得模型能够同时学习动作控制和运动推理,从而提升了模型的泛化能力。与现有方法的本质区别在于,该方法显式地建模了运动信息,并将其与动作控制相结合。
关键设计:运动头采用Diffusion Transformer (DiT) 架构,以光流图像作为预测目标。损失函数包括动作预测损失和运动图像预测损失,两者加权求和。具体的权重参数需要根据实验进行调整。在训练过程中,采用了数据增强等技术来提高模型的鲁棒性。光流计算采用标准的算法,例如Farnebäck算法。
🖼️ 关键图片
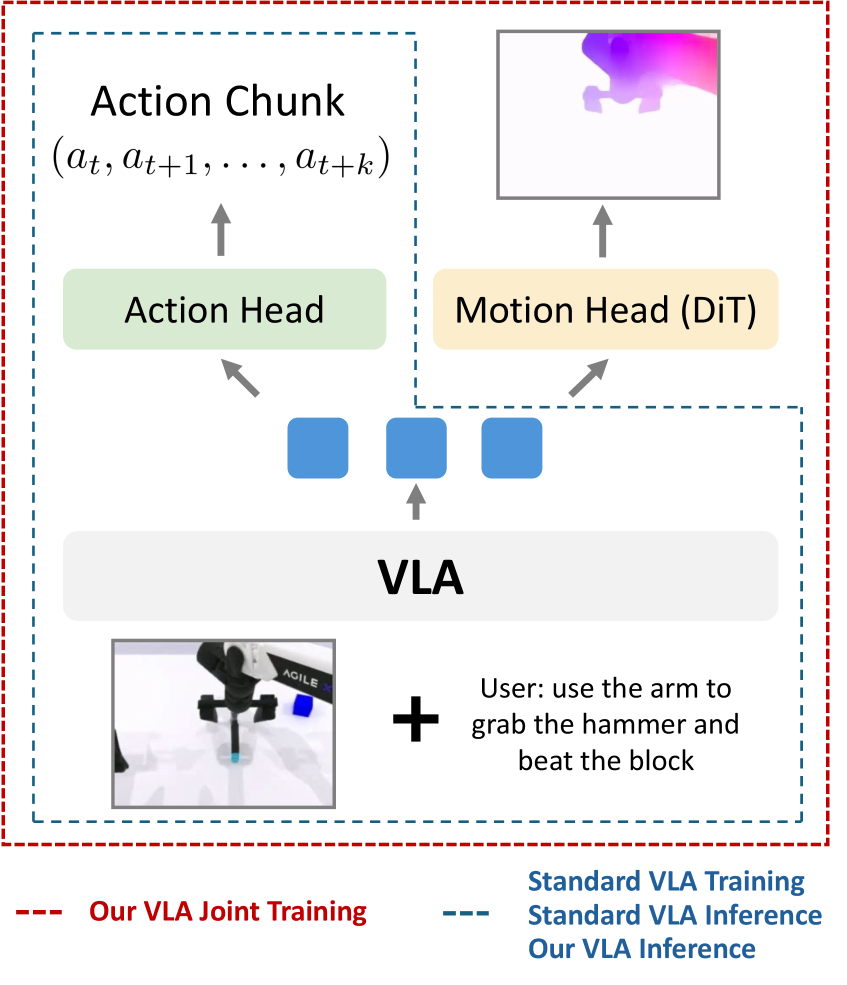
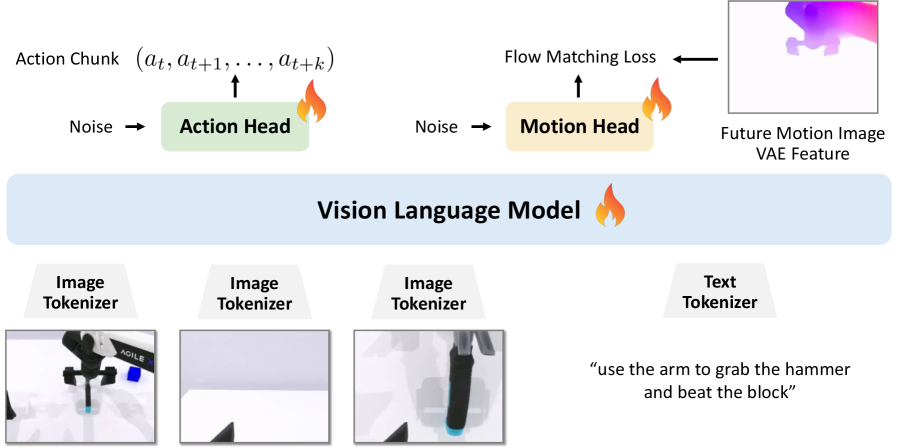
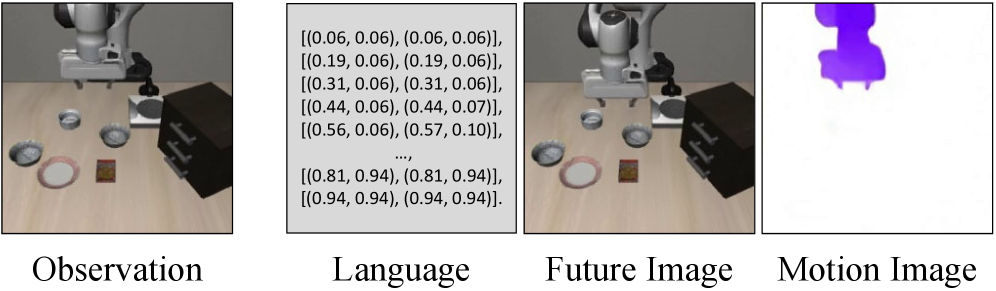
📊 实验亮点
实验结果表明,该方法在LIBERO和RoboTwin基准测试中均取得了显著的性能提升。在LIBERO基准测试中,成功率达到了97.5%。在更具挑战性的RoboTwin基准测试中,成功率达到了58.0%。特别是在真实环境中,该方法将VLA模型的性能提升了23%,验证了其在实际应用中的有效性。这些结果表明,基于运动图像扩散的联合学习能够有效提升VLA模型的运动推理能力。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如家庭服务机器人、工业机器人、自动驾驶等。通过提升机器人的运动推理能力,可以使其在复杂环境中更好地完成任务,提高工作效率和安全性。未来,该方法还可以扩展到其他领域,例如视频预测、动作生成等。
📄 摘要(原文)
Vision-Language-Action (VLA) models have achieved remarkable progress in robotic manipulation by mapping multimodal observations and instructions directly to actions. However, they typically mimic expert trajectories without predictive motion reasoning, which limits their ability to reason about what actions to take. To address this limitation, we propose joint learning with motion image diffusion, a novel strategy that enhances VLA models with motion reasoning capabilities. Our method extends the VLA architecture with a dual-head design: while the action head predicts action chunks as in vanilla VLAs, an additional motion head, implemented as a Diffusion Transformer (DiT), predicts optical-flow-based motion images that capture future dynamics. The two heads are trained jointly, enabling the shared VLM backbone to learn representations that couple robot control with motion knowledge. This joint learning builds temporally coherent and physically grounded representations without modifying the inference pathway of standard VLAs, thereby maintaining test-time latency. Experiments in both simulation and real-world environments demonstrate that joint learning with motion image diffusion improves the success rate of pi-series VLAs to 97.5% on the LIBERO benchmark and 58.0% on the RoboTwin benchmark, yielding a 23% improvement in real-world performance and validating its effectiveness in enhancing the motion reasoning capability of large-scale VLAs.