AnyTask: an Automated Task and Data Generation Framework for Advancing Sim-to-Real Policy Learning
作者: Ran Gong, Xiaohan Zhang, Jinghuan Shang, Maria Vittoria Minniti, Jigarkumar Patel, Valerio Pepe, Riedana Yan, Ahmet Gundogdu, Ivan Kapelyukh, Ali Abbas, Xiaoqiang Yan, Harsh Patel, Laura Herlant, Karl Schmeckpeper
分类: cs.RO, cs.AI
发布日期: 2025-12-19 (更新: 2026-01-20)
备注: 28 pages, 25 figures. The first four authors contributed equally
💡 一句话要点
AnyTask:自动化任务与数据生成框架,推进Sim-to-Real策略学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 Sim-to-Real 自动化任务生成 数据生成 行为克隆
📋 核心要点
- 现实世界机器人数据收集成本高昂,阻碍了通用机器人学习的发展。
- AnyTask框架结合GPU仿真与基础模型,自动化生成多样化操作任务和机器人数据。
- 通过行为克隆策略,在真实机器人上实现了44%的平均成功率,验证了方法的有效性。
📝 摘要(中文)
通用机器人学习受到数据限制:大规模、多样化和高质量的交互数据在现实世界中收集成本高昂。虽然仿真已成为扩展数据收集的一种有前景的方法,但相关任务,包括仿真任务设计、任务感知场景生成、专家演示合成以及Sim-to-Real迁移,仍然需要大量的人工干预。我们提出了AnyTask,一个自动化框架,它将大规模并行GPU仿真与基础模型相结合,以设计多样化的操作任务并合成机器人数据。我们引入了三个AnyTask代理来生成专家演示,旨在解决尽可能多的任务:1) ViPR,一种新颖的任务和运动规划代理,具有VLM在环并行细化;2) ViPR-Eureka,一种强化学习代理,具有生成的密集奖励和LLM引导的接触采样;3) ViPR-RL,一种混合规划和学习方法,它仅使用稀疏奖励共同产生高质量的演示。我们在生成的数据上训练行为克隆策略,在仿真中验证它们,并将它们直接部署在真实机器人硬件上。这些策略推广到新的物体姿势,在真实世界的抓取放置、抽屉打开、富接触推以及长时程操作任务中实现了44%的平均成功率。
🔬 方法详解
问题定义:现有机器人学习方法依赖大量真实世界数据,但数据收集成本高昂且耗时。仿真环境可以生成大量数据,但任务设计、场景生成、专家演示合成和Sim-to-Real迁移仍然需要大量人工干预,限制了仿真数据的利用效率。
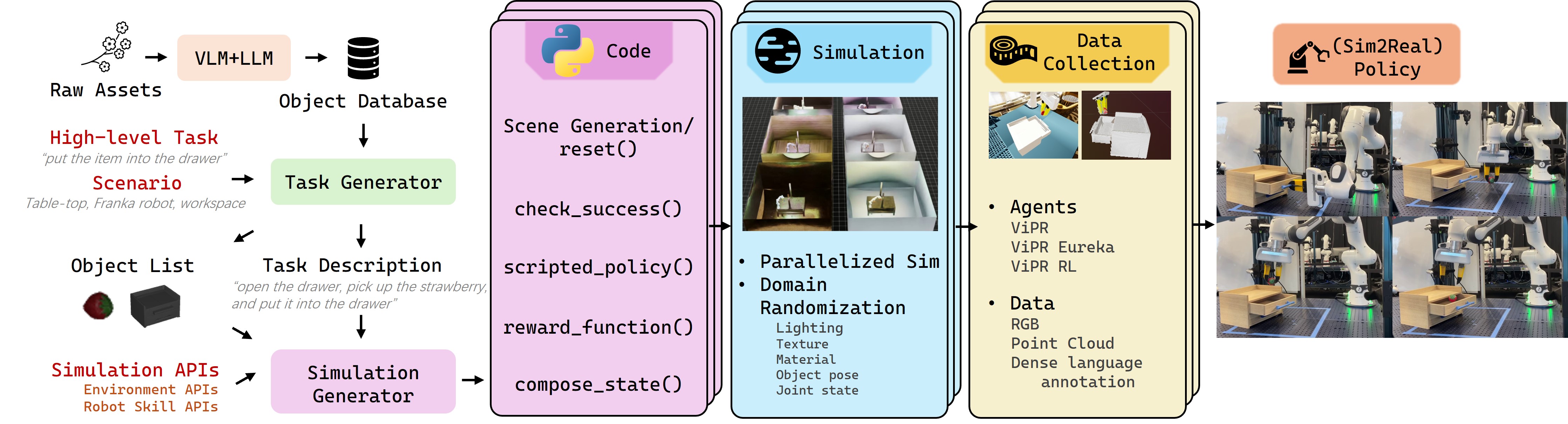
核心思路:AnyTask框架的核心在于自动化任务和数据生成流程,通过结合大规模并行GPU仿真和基础模型,降低人工干预,提高数据生成效率和多样性。利用生成的数据训练策略,并实现从仿真到真实的迁移。
技术框架:AnyTask框架包含任务设计、场景生成、专家演示合成和Sim-to-Real迁移等模块。其中,专家演示合成模块是核心,包含三个AnyTask代理:ViPR(VLM-in-the-loop Parallel Refinement)、ViPR-Eureka(强化学习+LLM引导)和ViPR-RL(混合规划与学习)。这些代理负责生成高质量的专家演示数据。
关键创新:AnyTask的关键创新在于将大规模并行GPU仿真与基础模型相结合,实现了任务和数据的自动化生成。特别是ViPR代理,通过VLM在环并行细化,能够有效地进行任务和运动规划。ViPR-Eureka利用LLM引导的接触采样,提高了强化学习的效率。
关键设计:ViPR代理使用VLM进行任务理解和目标设定,并通过并行细化策略优化运动轨迹。ViPR-Eureka代理使用LLM生成密集奖励函数,并引导接触采样,加速强化学习过程。ViPR-RL代理则结合了规划和学习方法,利用稀疏奖励生成高质量的演示数据。行为克隆策略使用生成的数据进行训练,并通过域随机化等技术实现Sim-to-Real迁移。
🖼️ 关键图片
📊 实验亮点
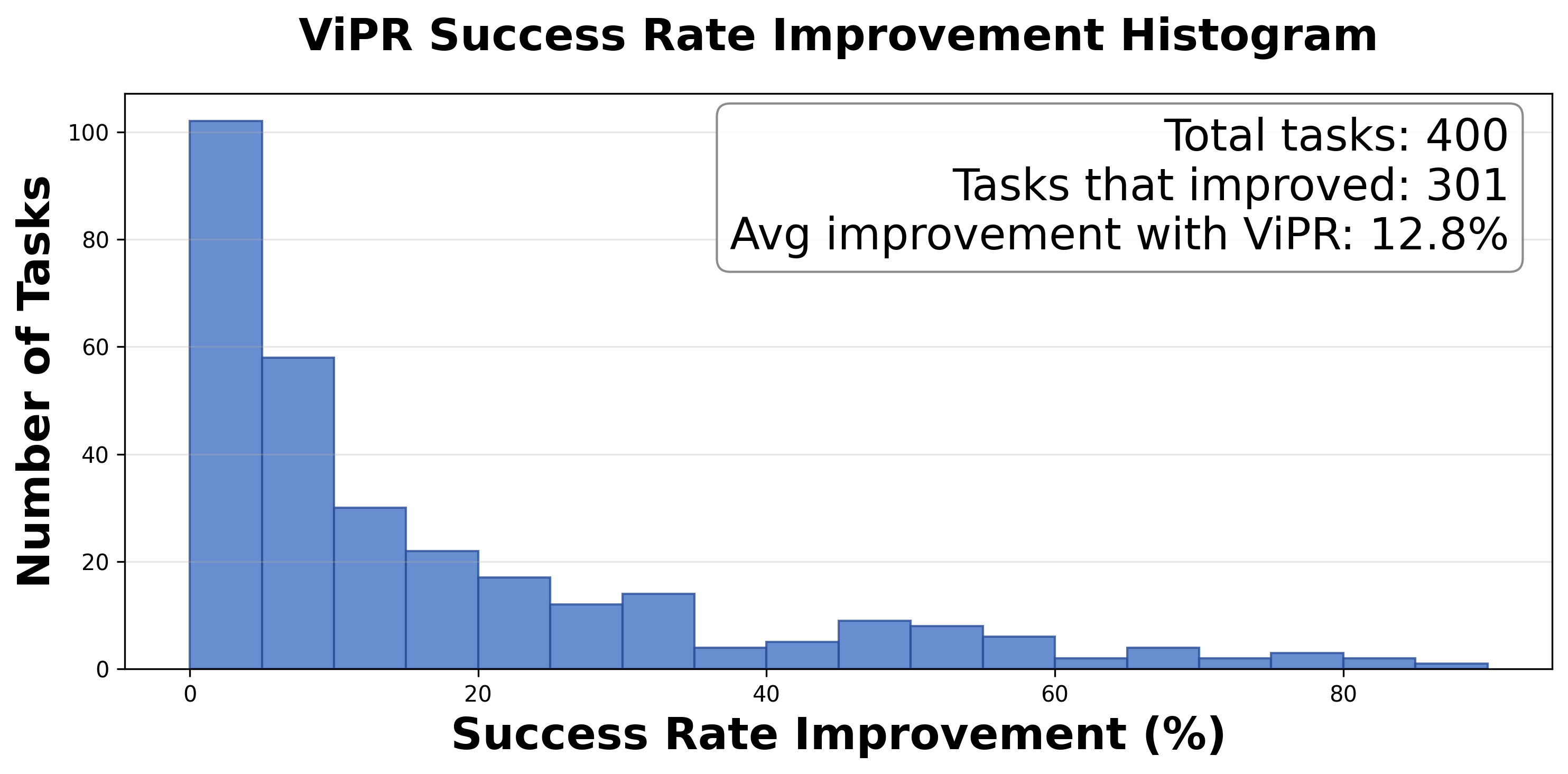
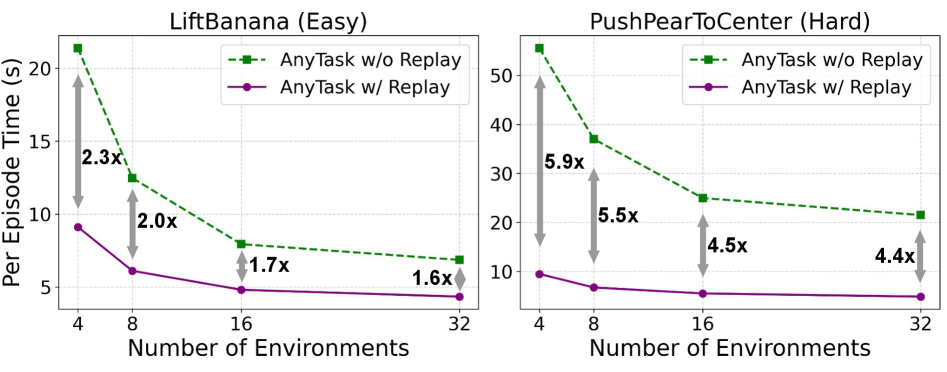
实验结果表明,使用AnyTask框架生成的数据训练的策略,在真实世界的抓取放置、抽屉打开、富接触推以及长时程操作任务中实现了44%的平均成功率。该策略能够泛化到新的物体姿势,证明了AnyTask框架的有效性和泛化能力。相较于传统方法,AnyTask显著降低了人工干预,提高了数据生成效率。
🎯 应用场景
AnyTask框架可应用于各种机器人操作任务,例如工业自动化、家庭服务机器人和医疗机器人等。通过自动化生成训练数据,可以降低机器人学习的成本,加速机器人在复杂环境中的部署。该框架还可用于探索新的机器人任务和技能,推动机器人技术的进步。
📄 摘要(原文)
Generalist robot learning remains constrained by data: large-scale, diverse, and high-quality interaction data are expensive to collect in the real world. While simulation has become a promising way for scaling up data collection, the related tasks, including simulation task design, task-aware scene generation, expert demonstration synthesis, and sim-to-real transfer, still demand substantial human effort. We present AnyTask, an automated framework that pairs massively parallel GPU simulation with foundation models to design diverse manipulation tasks and synthesize robot data. We introduce three AnyTask agents for generating expert demonstrations aiming to solve as many tasks as possible: 1) ViPR, a novel task and motion planning agent with VLM-in-the-loop Parallel Refinement; 2) ViPR-Eureka, a reinforcement learning agent with generated dense rewards and LLM-guided contact sampling; 3) ViPR-RL, a hybrid planning and learning approach that jointly produces high-quality demonstrations with only sparse rewards. We train behavior cloning policies on generated data, validate them in simulation, and deploy them directly on real robot hardware. The policies generalize to novel object poses, achieving 44% average success across a suite of real-world pick-and-place, drawer opening, contact-rich pushing, and long-horizon manipulation tasks. Our project website is at https://anytask.rai-inst.com .