ImagineNav++: Prompting Vision-Language Models as Embodied Navigator through Scene Imagination
作者: Teng Wang, Xinxin Zhao, Wenzhe Cai, Changyin Sun
分类: cs.RO
发布日期: 2025-12-19 (更新: 2026-01-08)
备注: 17 pages, 10 figures. arXiv admin note: text overlap with arXiv:2410.09874
💡 一句话要点
ImagineNav++:通过场景想象,将视觉-语言模型用作具身导航器
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉导航 视觉-语言模型 场景想象 具身智能 无地图导航
📋 核心要点
- 现有基于LLM的导航方法依赖文本表示,难以充分捕捉空间信息,限制了导航决策。
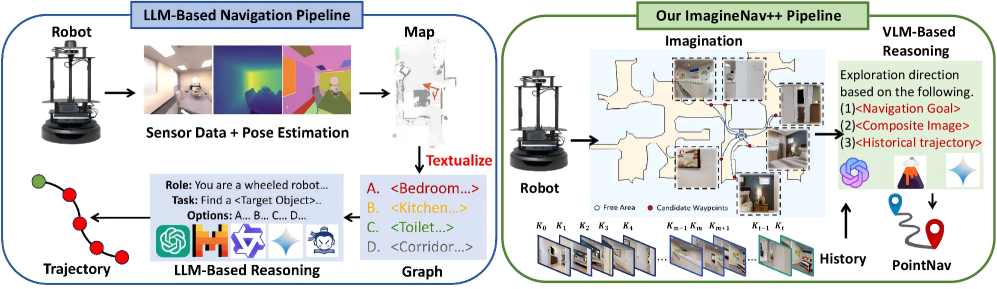
- ImagineNav++通过想象未来视图,将导航规划转化为VLM的最佳视图选择问题,利用VLM的空间感知能力。
- 实验表明,ImagineNav++在无地图导航中达到SOTA,甚至超越多数基于地图的方法,验证了场景想象和记忆的重要性。
📝 摘要(中文)
视觉导航是自主家庭辅助机器人的基本能力,能够实现诸如物体搜索之类的长时程任务。尽管最近的方法利用大型语言模型(LLM)来整合常识推理并提高探索效率,但它们的规划仍然受到文本表示的限制,文本表示无法充分捕捉空间占用或场景几何结构——这是导航决策的关键因素。我们探索了视觉-语言模型(VLM)是否仅使用板载RGB/RGB-D流来实现无地图视觉导航,从而释放它们在空间感知和规划方面的潜力。我们通过一个由想象驱动的导航框架ImagineNav++来实现这一点,该框架从候选机器人视图中想象未来的观察图像,并将导航规划转化为VLM的最佳视图图像选择问题。首先,未来视图想象模块提炼人类导航偏好,以生成具有高探索潜力的语义上有意义的视点。然后,这些想象的视图作为VLM的视觉提示,以识别信息量最大的视点。为了保持空间一致性,我们开发了一种选择性中央凹记忆机制,该机制通过稀疏到密集框架分层整合关键帧观察,构建一个紧凑而全面的记忆,用于长期空间推理。这种方法将面向目标的导航转化为一系列易于处理的点目标导航任务。在开放词汇对象和实例导航基准上的大量实验表明,ImagineNav++在无地图设置中实现了SOTA性能,甚至超过了大多数基于地图的方法,突出了场景想象和记忆在基于VLM的空间推理中的重要性。
🔬 方法详解
问题定义:现有基于大型语言模型(LLM)的视觉导航方法,虽然能够利用常识推理,但其规划过程依赖于文本表示,无法充分捕捉场景的空间占用和几何信息。这导致导航决策受限,尤其是在需要精细空间理解的任务中。现有方法的痛点在于缺乏对空间信息的有效利用,以及对长期空间推理能力的不足。
核心思路:ImagineNav++的核心思路是利用视觉-语言模型(VLM)的视觉感知能力,通过“场景想象”来弥补传统方法在空间理解上的不足。具体来说,该方法通过想象未来可能的观察图像,并将导航规划问题转化为一个最佳视图选择问题,从而让VLM能够基于视觉信息进行决策。这种方法将复杂的导航任务分解为一系列更易于处理的子任务,并利用VLM的强大视觉推理能力。
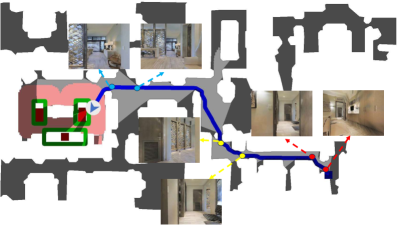
技术框架:ImagineNav++的整体框架包含以下几个主要模块:1) 未来视图想象模块:该模块负责根据当前状态和候选动作,生成未来可能的观察图像。它通过学习人类导航偏好,生成具有高探索潜力的语义视点。2) 视觉-语言模型(VLM):VLM接收想象的未来视图作为视觉提示,并根据目标和当前状态,选择信息量最大的视点。3) 选择性中央凹记忆机制:该机制用于维护一个长期空间记忆,通过分层整合关键帧观察,构建一个紧凑而全面的空间表示。它采用稀疏到密集的方式,逐步完善对环境的理解。
关键创新:ImagineNav++的关键创新在于将场景想象引入视觉导航,并将其与VLM相结合。与传统方法相比,它不再依赖于显式的地图构建或文本表示,而是直接利用VLM的视觉感知能力进行空间推理。此外,选择性中央凹记忆机制能够有效地管理长期空间信息,提高导航的鲁棒性和效率。
关键设计:未来视图想象模块的设计需要考虑如何生成具有语义意义和探索价值的视点。选择性中央凹记忆机制的关键在于如何选择关键帧,以及如何有效地融合不同尺度的信息。VLM的选择和提示方式也至关重要,需要根据具体的导航任务进行调整。损失函数的设计需要能够引导模型学习到人类的导航偏好,并生成高质量的未来视图。
🖼️ 关键图片
📊 实验亮点
ImagineNav++在开放词汇对象和实例导航基准测试中取得了显著成果,在无地图设置下实现了SOTA性能,甚至超越了大多数基于地图的方法。这表明了场景想象和记忆在基于VLM的空间推理中的重要性。具体的性能数据需要在论文中查找,但总体而言,该方法在导航成功率和路径效率方面均有显著提升。
🎯 应用场景
ImagineNav++具有广泛的应用前景,可用于家庭服务机器人、物流机器人、自动驾驶等领域。该技术能够使机器人在未知环境中进行自主导航和物体搜索,提高机器人的智能化水平和服务能力。未来,该研究可以进一步扩展到更复杂的环境和任务中,例如灾难救援、医疗辅助等。
📄 摘要(原文)
Visual navigation is a fundamental capability for autonomous home-assistance robots, enabling long-horizon tasks such as object search. While recent methods have leveraged Large Language Models (LLMs) to incorporate commonsense reasoning and improve exploration efficiency, their planning remains constrained by textual representations, which cannot adequately capture spatial occupancy or scene geometry--critical factors for navigation decisions. We explore whether Vision-Language Models (VLMs) can achieve mapless visual navigation using only onboard RGB/RGB-D streams, unlocking their potential for spatial perception and planning. We achieve this through an imagination-powered navigation framework, ImagineNav++, which imagines future observation images from candidate robot views and translates navigation planning into a simple best-view image selection problem for VLMs. First, a future-view imagination module distills human navigation preferences to generate semantically meaningful viewpoints with high exploration potential. These imagined views then serve as visual prompts for the VLM to identify the most informative viewpoint. To maintain spatial consistency, we develop a selective foveation memory mechanism, which hierarchically integrates keyframe observations via a sparse-to-dense framework, constructing a compact yet comprehensive memory for long-term spatial reasoning. This approach transforms goal-oriented navigation into a series of tractable point-goal navigation tasks. Extensive experiments on open-vocabulary object and instance navigation benchmarks show that ImagineNav++ achieves SOTA performance in mapless settings, even surpassing most map-based methods, highlighting the importance of scene imagination and memory in VLM-based spatial reasoning.