PolaRiS: Scalable Real-to-Sim Evaluations for Generalist Robot Policies
作者: Arhan Jain, Mingtong Zhang, Kanav Arora, William Chen, Marcel Torne, Muhammad Zubair Irshad, Sergey Zakharov, Yue Wang, Sergey Levine, Chelsea Finn, Wei-Chiu Ma, Dhruv Shah, Abhishek Gupta, Karl Pertsch
分类: cs.RO, cs.LG
发布日期: 2025-12-18 (更新: 2025-12-30)
备注: Website: https://polaris-evals.github.io/
💡 一句话要点
PolaRiS:用于通用机器人策略的可扩展真实到模拟评估框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 策略评估 真实到模拟 神经重建 仿真环境 通用机器人 领域自适应 数据协同训练
📋 核心要点
- 现有机器人策略评估方法在真实环境中成本高昂且难以复现,仿真环境又存在严重的真实到模拟的领域差距。
- PolaRiS通过神经重建将真实场景转化为交互式仿真环境,并结合数据协同训练,缩小真实与模拟之间的差距。
- 实验表明,PolaRiS评估与真实世界通用策略性能的相关性远高于现有仿真基准,且能快速创建多样化环境。
📝 摘要(中文)
机器人学习研究面临的一个重大挑战是准确测量和比较机器人策略的性能。由于真实环境rollout的随机性、可重复性和耗时性,机器人技术的基准测试历来具有挑战性。对于最近的通用策略,需要在各种场景和任务中进行评估,这使得挑战更加严峻。仿真环境中的评估为真实环境评估提供了一种可扩展的补充,但现有仿真基准与真实世界之间的视觉和物理领域差距使其成为不可靠的策略改进信号。此外,构建逼真且多样化的仿真环境传统上需要大量的人力和专业知识。为了弥合差距,我们引入了仿真环境中的策略评估和环境重建(PolaRiS),这是一个可扩展的真实到模拟框架,用于高保真仿真机器人评估。PolaRiS利用神经重建方法将真实场景的短视频扫描转换为交互式仿真环境。此外,我们开发了一种简单的仿真数据协同训练方法,弥合了剩余的真实到模拟差距,并实现了在未见过的仿真环境中的零样本评估。通过仿真和真实世界之间的广泛配对评估,我们证明PolaRiS评估比现有的仿真基准更能提供与真实世界通用策略性能的更强相关性。它的简单性也使得能够快速创建多样化的仿真环境。因此,这项工作朝着下一代机器人基础模型的分布式和民主化评估迈出了一步。
🔬 方法详解
问题定义:论文旨在解决机器人策略评估中真实环境评估成本高、复现难,以及现有仿真环境与真实世界存在较大领域差距的问题。现有方法难以准确评估通用机器人策略在各种场景和任务中的性能,阻碍了机器人学习研究的进展。
核心思路:论文的核心思路是构建一个可扩展的真实到模拟的评估框架,该框架能够利用神经重建技术将真实世界的场景转化为高保真的仿真环境,并通过数据协同训练来进一步缩小真实与模拟之间的差距。这样可以在仿真环境中进行高效、可重复的策略评估,并使其结果更可靠地反映真实世界的性能。
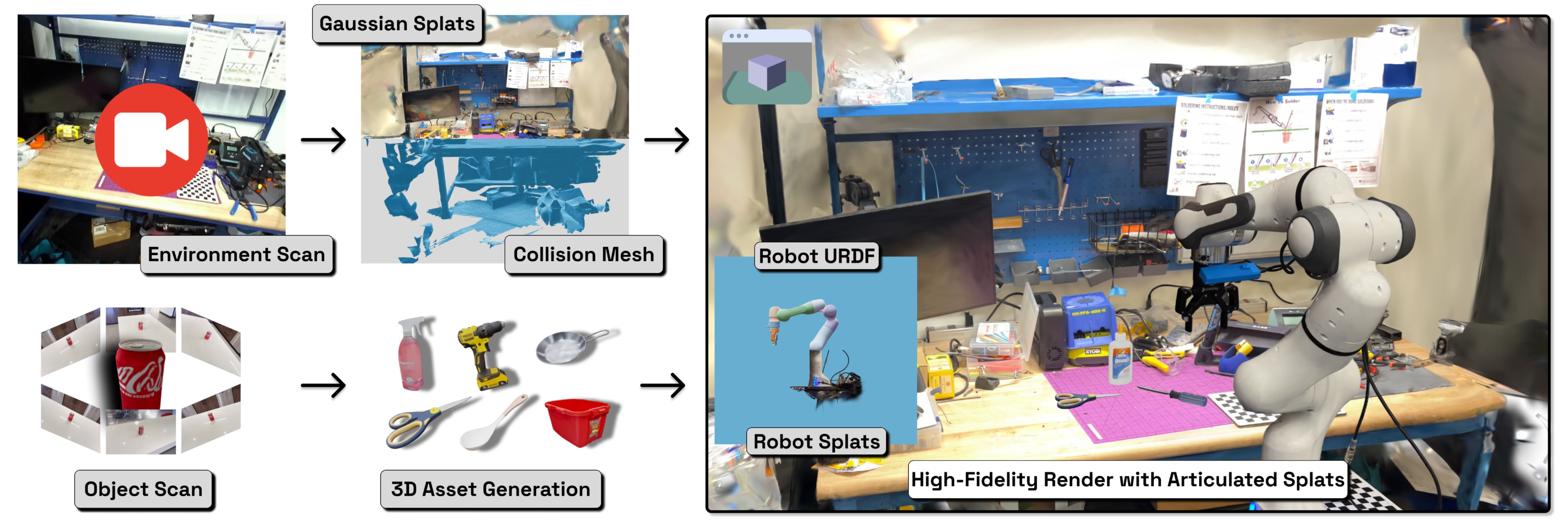
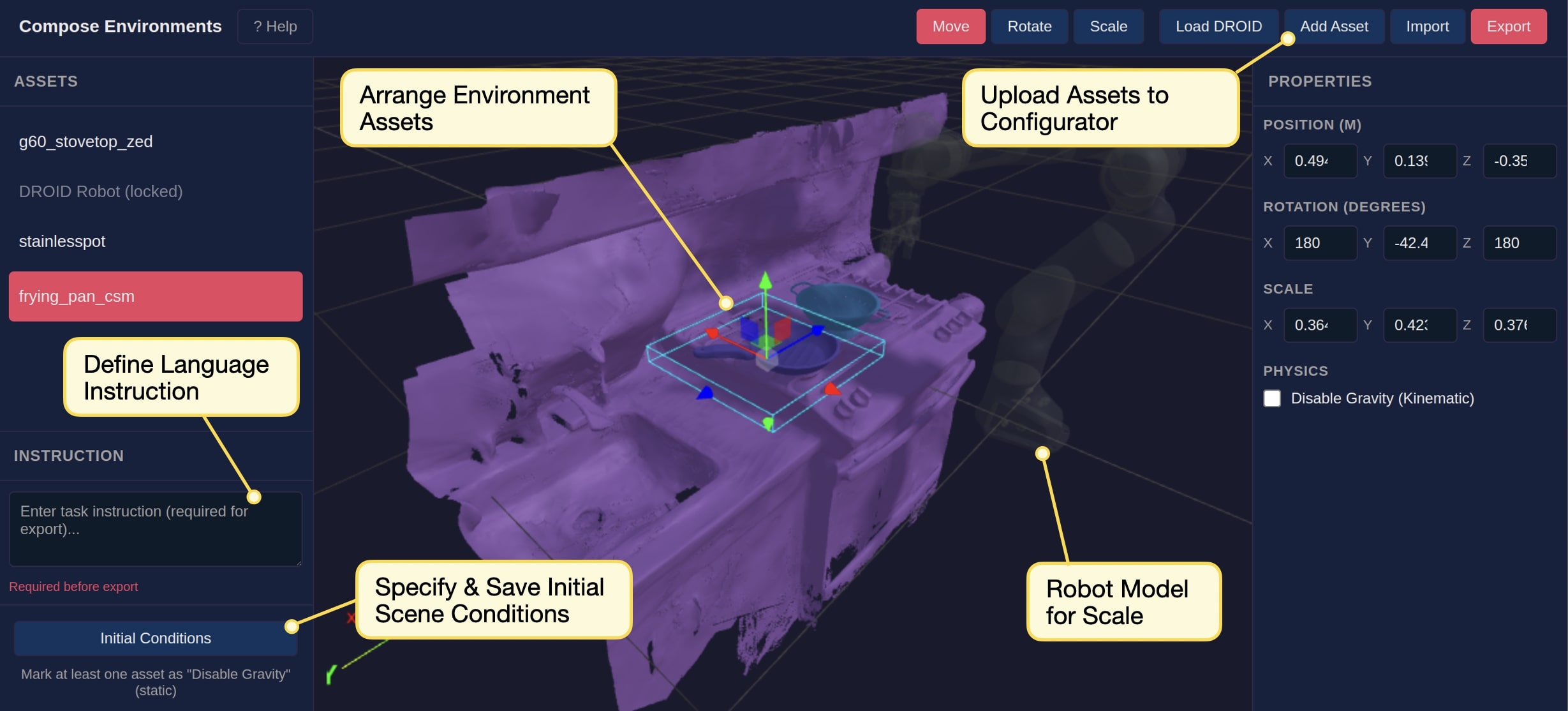
技术框架:PolaRiS框架主要包含以下几个阶段:1) 真实场景扫描:使用短视频扫描真实世界的场景。2) 神经环境重建:利用神经重建方法将扫描的视频转化为交互式的仿真环境。3) 仿真数据协同训练:通过在仿真数据上进行协同训练,进一步缩小真实与模拟之间的差距。4) 策略评估:在重建的仿真环境中评估机器人策略的性能。
关键创新:PolaRiS的关键创新在于其能够利用神经重建技术自动地将真实世界的场景转化为高保真的仿真环境,从而避免了传统仿真环境构建中需要大量人工干预的问题。此外,数据协同训练方法进一步提升了仿真环境的真实性,使得在仿真环境中评估的策略性能更可靠地反映真实世界的性能。
关键设计:论文中使用了特定的神经重建方法(具体方法未知)来将视频转化为仿真环境。数据协同训练的具体实现细节(例如,使用的损失函数、网络结构等)在论文中没有详细描述,属于未知信息。论文强调了PolaRiS的简单性,使其能够快速创建多样化的仿真环境,但具体的技术细节需要参考论文原文。
🖼️ 关键图片

📊 实验亮点
论文通过大量的仿真和真实世界配对评估,证明了PolaRiS评估与真实世界通用策略性能的相关性远高于现有的仿真基准。具体性能数据和提升幅度在摘要中未明确给出,需要查阅论文原文获取更详细的实验结果。
🎯 应用场景
PolaRiS框架可应用于机器人学习研究的各个方面,例如通用机器人策略的开发、评估和改进。它能够加速机器人算法的迭代过程,降低开发成本,并促进机器人技术在各个领域的应用,如家庭服务、工业自动化和医疗保健等。该框架还为机器人基础模型的开发和评估提供了一种可扩展且民主化的方法。
📄 摘要(原文)
A significant challenge for robot learning research is our ability to accurately measure and compare the performance of robot policies. Benchmarking in robotics is historically challenging due to the stochasticity, reproducibility, and time-consuming nature of real-world rollouts. This challenge is exacerbated for recent generalist policies, which has to be evaluated across a wide variety of scenes and tasks. Evaluation in simulation offers a scalable complement to real world evaluations, but the visual and physical domain gap between existing simulation benchmarks and the real world has made them an unreliable signal for policy improvement. Furthermore, building realistic and diverse simulated environments has traditionally required significant human effort and expertise. To bridge the gap, we introduce Policy Evaluation and Environment Reconstruction in Simulation (PolaRiS), a scalable real-to-sim framework for high-fidelity simulated robot evaluation. PolaRiS utilizes neural reconstruction methods to turn short video scans of real-world scenes into interactive simulation environments. Additionally, we develop a simple simulation data co-training recipe that bridges remaining real-to-sim gaps and enables zero-shot evaluation in unseen simulation environments. Through extensive paired evaluations between simulation and the real world, we demonstrate that PolaRiS evaluations provide a much stronger correlation to real world generalist policy performance than existing simulated benchmarks. Its simplicity also enables rapid creation of diverse simulated environments. As such, this work takes a step towards distributed and democratized evaluation for the next generation of robotic foundation models.