PhysBrain: Human Egocentric Data as a Bridge from Vision Language Models to Physical Intelligence
作者: Xiaopeng Lin, Shijie Lian, Bin Yu, Ruoqi Yang, Zhaolong Shen, Changti Wu, Yuzhuo Miao, Yurun Jin, Yukun Shi, Jiyan He, Cong Huang, Bojun Cheng, Kai Chen
分类: cs.RO
发布日期: 2025-12-18 (更新: 2026-02-04)
备注: 21 pages, 8 figures
💡 一句话要点
提出PhysBrain,利用人类第一视角数据提升机器人物理智能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人控制 物理智能 第一视角视觉 具身智能 视觉语言模型
📋 核心要点
- 现有VLA系统依赖第三人称数据训练的VLM,导致机器人第一视角理解能力不足,限制了其物理智能。
- 论文提出Egocentric2Embodiment翻译流程,将人类第一视角视频转化为具身监督,构建大规模E2E-3M数据集。
- PhysBrain通过E2E-3M训练,显著提升了机器人第一视角理解和规划能力,并实现了高效的VLA微调。
📝 摘要(中文)
机器人泛化依赖于物理智能,即在第一视角感知和动作下,推理状态变化、富接触交互和长时程规划的能力。视觉语言模型(VLMs)对视觉-语言-动作(VLA)系统至关重要,但对第三人称训练数据的依赖造成了人型机器人的视角差距。收集大规模机器人中心数据是理想的解决方案,但由于成本和多样性限制并不现实。相反,人类第一视角视频提供了具有丰富交互上下文的高度可扩展数据源,但具身差异阻碍了直接应用。为了弥合这一差距,我们提出了一种Egocentric2Embodiment翻译流程,将原始人类第一视角视频转换为多层次、模式驱动的具身监督,并强制执行证据基础和时间一致性,从而大规模构建Egocentric2Embodiment数据集(E2E-3M)。通过在E2E-3M数据集上训练,获得了一个以第一视角为中心的具身大脑,称为PhysBrain。PhysBrain在第一视角理解方面表现出显著提升,尤其是在规划方面。它提供了一个以第一视角为中心的初始化,能够实现更高效的VLA微调和更高的成功率,证明了从人类第一视角监督到下游机器人控制的有效迁移。
🔬 方法详解
问题定义:现有VLA系统依赖于视觉语言模型(VLM),而这些VLM通常在第三人称视角的数据上进行训练。这导致机器人难以理解和推理其自身第一视角下的环境和交互,从而限制了其在复杂物理任务中的泛化能力。直接收集机器人第一视角数据成本高昂且难以保证数据多样性。
核心思路:论文的核心思路是利用人类第一视角视频作为桥梁,将人类的丰富交互经验迁移到机器人身上。通过将人类第一视角视频转换为机器人可理解的具身监督信号,从而训练机器人具备更强的物理智能。这种方法避免了直接收集大量机器人数据的难题,并充分利用了人类数据的可扩展性和多样性。
技术框架:整体框架包含两个主要部分:Egocentric2Embodiment翻译流程和PhysBrain的训练。Egocentric2Embodiment翻译流程负责将原始人类第一视角视频转换为多层次、模式驱动的具身监督,包括状态变化、接触交互和长时程规划等信息。该流程强制执行证据基础和时间一致性,以保证数据的质量。然后,利用E2E-3M数据集训练PhysBrain,使其具备第一视角理解和规划能力。最后,将PhysBrain作为VLA系统的初始化,进行微调以适应具体的机器人控制任务。
关键创新:该论文的关键创新在于提出了Egocentric2Embodiment翻译流程,它能够有效地将人类第一视角视频转换为机器人可用的具身监督信号。这种方法打破了传统VLA系统对第三人称数据的依赖,并为机器人学习物理智能提供了一种新的数据来源。此外,PhysBrain的训练也充分利用了E2E-3M数据集的优势,使其在第一视角理解方面表现出显著提升。
关键设计:Egocentric2Embodiment翻译流程的关键设计包括多层次的具身监督模式,例如状态变化、接触交互和长时程规划。这些模式能够捕捉人类交互的丰富信息,并将其转换为机器人可学习的表示。此外,证据基础和时间一致性的强制执行也保证了数据的质量和可靠性。PhysBrain的网络结构和损失函数的设计也需要针对第一视角理解和规划任务进行优化,具体的细节在论文中可能有所描述。
🖼️ 关键图片
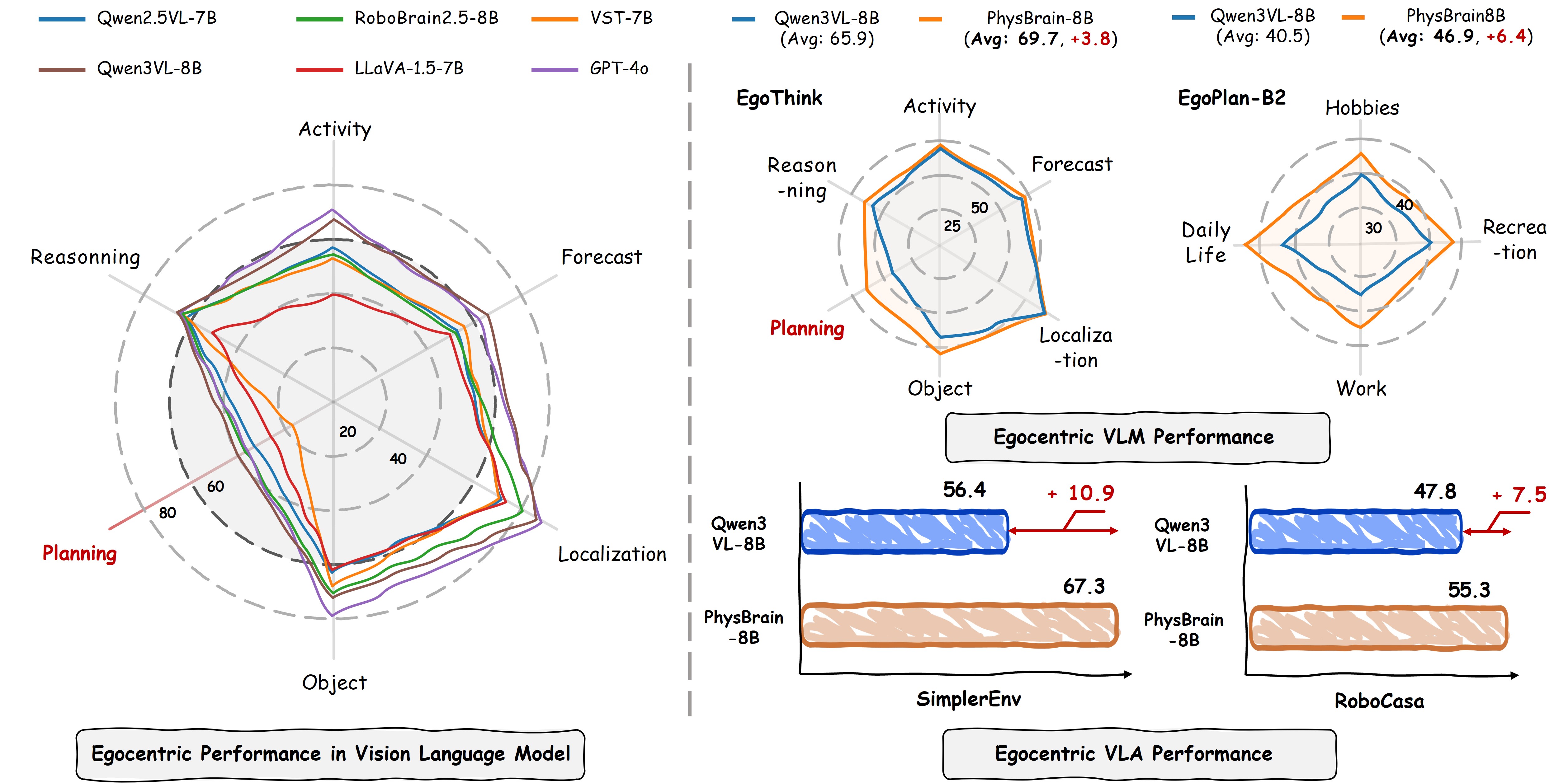
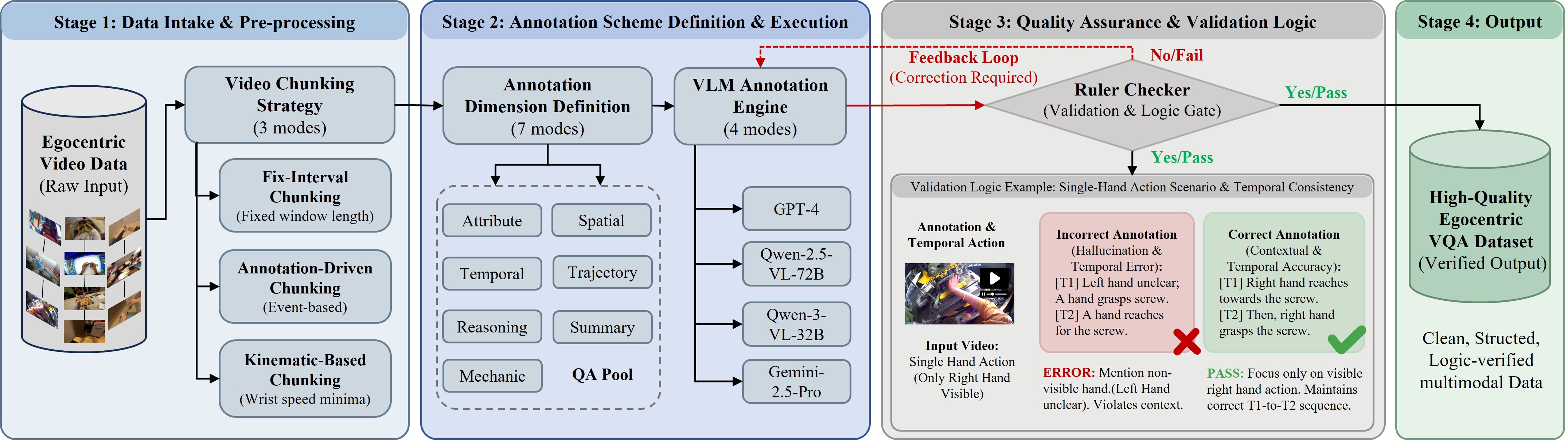
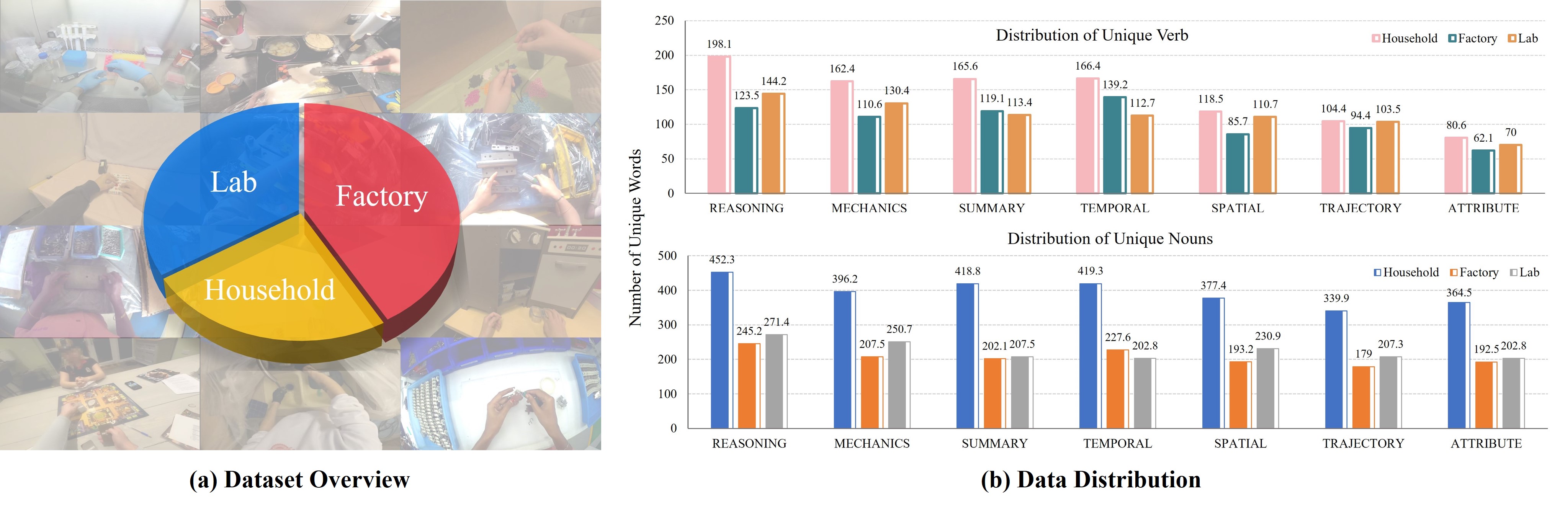
📊 实验亮点
PhysBrain在第一视角理解方面表现出显著提升,尤其是在规划方面。通过在E2E-3M数据集上训练,PhysBrain能够提供一个以第一视角为中心的初始化,从而实现更高效的VLA微调和更高的成功率。实验结果表明,该方法能够有效地将人类第一视角监督迁移到下游机器人控制任务中,提升机器人的物理智能。
🎯 应用场景
该研究成果可应用于各种机器人控制任务,尤其是在需要机器人具备高度物理智能的场景中,例如家庭服务机器人、工业自动化机器人和医疗辅助机器人。通过利用人类第一视角数据,可以显著降低机器人学习的成本,并提高其在复杂环境中的适应性和泛化能力。未来,该方法有望推动机器人技术在更多领域的应用。
📄 摘要(原文)
Robotic generalization relies on physical intelligence: the ability to reason about state changes, contact-rich interactions, and long-horizon planning under egocentric perception and action. Vision Language Models (VLMs) are essential to Vision-Language-Action (VLA) systems, but the reliance on third-person training data creates a viewpoint gap for humanoid robots. Collecting massive robot-centric data is an ideal but impractical solution due to cost and diversity constraints. Conversely, human egocentric videos offer a highly scalable data source with rich interaction context, yet the embodiment mismatch prevents the direct application. To bridge this gap, we propose an Egocentric2Embodiment Translation Pipeline that transforms raw human egocentric videos into multi-level, schema-driven embodiment supervision with enforced evidence grounding and temporal consistency, enabling the construction of the Egocentric2Embodiment dataset (E2E-3M) at scale. An egocentric-aware embodied brain, termed PhysBrain, is obtained by training on the E2E-3M dataset. PhysBrain exhibits substantially improved egocentric understanding, particularly for planning. It provides an egocentric-aware initialization that enables more sample-efficient VLA fine-tuning and higher success rates, demonstrating effective transfer from human egocentric supervision to downstream robot control.