Vision-Language-Action Models for Autonomous Driving: Past, Present, and Future
作者: Tianshuai Hu, Xiaolu Liu, Song Wang, Yiyao Zhu, Ao Liang, Lingdong Kong, Guoyang Zhao, Zeying Gong, Jun Cen, Zhiyu Huang, Xiaoshuai Hao, Linfeng Li, Hang Song, Xiangtai Li, Jun Ma, Shaojie Shen, Jianke Zhu, Dacheng Tao, Ziwei Liu, Junwei Liang
分类: cs.RO
发布日期: 2025-12-18 (更新: 2026-01-04)
备注: Survey; 47 pages, 7 figures, 9 tables; GitHub Repo at https://github.com/worldbench/awesome-vla-for-ad
💡 一句话要点
综述性论文:面向自动驾驶的视觉-语言-动作模型研究进展与未来展望
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 视觉语言动作模型 多模态学习 大型语言模型 端到端学习
📋 核心要点
- 传统自动驾驶依赖“感知-决策-行动”流程,但手工设计组件在复杂场景失效,且感知误差会向下游传播。
- 视觉-语言-动作(VLA)模型通过整合视觉理解、语言推理和可执行动作,实现更通用和可解释的驾驶策略。
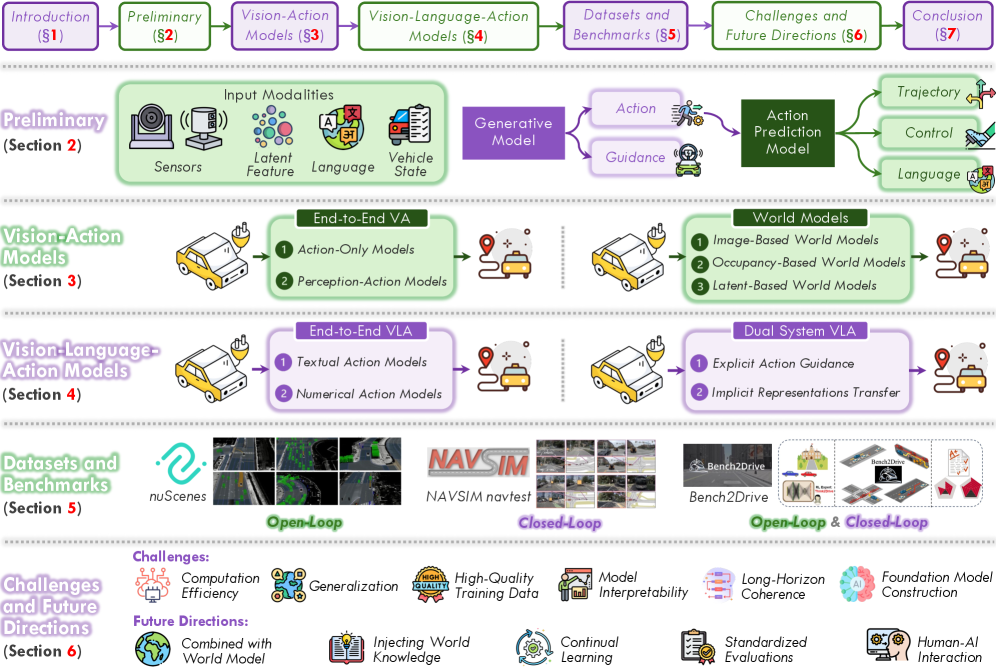
- 论文综述了VLA在自动驾驶中的应用,分析了端到端和双系统两种范例,并探讨了数据集、挑战和未来方向。
📝 摘要(中文)
自动驾驶长期以来依赖于模块化的“感知-决策-行动”流程,但手工设计的接口和基于规则的组件在复杂或长尾场景中经常失效。其级联设计进一步传播感知误差,降低下游规划和控制的性能。视觉-动作(VA)模型通过学习从视觉输入到动作的直接映射来解决一些局限性,但它们仍然不透明,对分布偏移敏感,并且缺乏结构化推理或指令遵循能力。大型语言模型(LLM)和多模态学习的最新进展推动了视觉-语言-动作(VLA)框架的出现,该框架将感知与基于语言的决策相结合。通过统一视觉理解、语言推理和可执行的输出,VLA为更可解释、更通用和更符合人类习惯的驾驶策略提供了一条途径。本文对新兴的自动驾驶VLA领域进行了结构化描述,追溯了从早期VA方法到现代VLA框架的演变,并将现有方法组织成两种主要范例:端到端VLA,它在单个模型中集成了感知、推理和规划;双系统VLA,它将慢速审议(通过VLM)与快速、安全关键的执行(通过规划器)分开。在这些范例中,我们进一步区分了文本与数值动作生成器以及显式与隐式指导机制等子类。我们还总结了用于评估基于VLA的驾驶系统的代表性数据集和基准,并强调了关键挑战和开放方向,包括鲁棒性、可解释性和指令保真度。总的来说,这项工作旨在为推进与人类兼容的自动驾驶系统奠定连贯的基础。
🔬 方法详解
问题定义:现有自动驾驶系统依赖模块化的“感知-决策-行动”流程,存在手工设计组件在复杂场景失效、感知误差向下游传播、以及缺乏可解释性和通用性等问题。视觉-动作(VA)模型虽然能直接从视觉输入映射到动作,但依然存在不透明、对分布偏移敏感等缺点。
核心思路:论文的核心思路是利用大型语言模型(LLM)和多模态学习的最新进展,将视觉、语言和动作结合起来,构建视觉-语言-动作(VLA)框架。通过语言作为桥梁,VLA模型能够进行更高级的推理和决策,从而提高自动驾驶系统的可解释性、通用性和安全性。
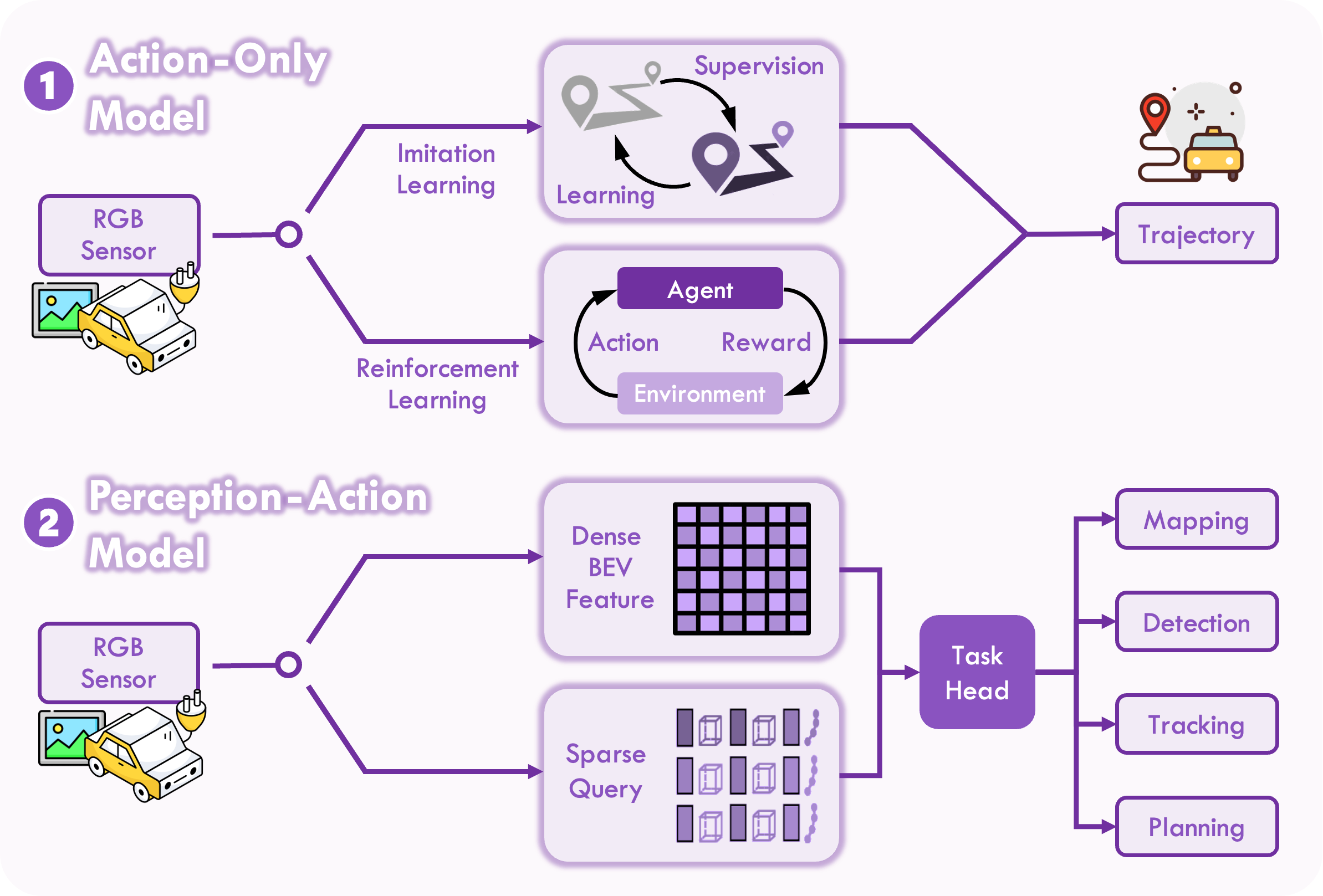
技术框架:论文将现有的VLA方法组织成两种主要范例:端到端VLA和双系统VLA。端到端VLA将感知、推理和规划集成在一个模型中,直接从视觉输入生成动作。双系统VLA则将慢速审议(通过视觉语言模型VLM)与快速、安全关键的执行(通过规划器)分开,实现更稳健的控制。
关键创新:论文的主要创新在于对自动驾驶领域的VLA模型进行了系统性的综述和分类,提出了端到端和双系统两种VLA范例,并对各种VLA方法的优缺点进行了分析。此外,论文还总结了用于评估VLA模型的代表性数据集和基准,并指出了该领域面临的关键挑战和未来发展方向。
关键设计:论文中讨论的关键设计包括:文本与数值动作生成器的选择、显式与隐式指导机制的设计、以及如何有效地利用大型语言模型进行推理和决策。此外,论文还强调了数据集的选择和构建对于VLA模型性能的重要性。
🖼️ 关键图片

📊 实验亮点
本文是一篇综述性论文,没有具体的实验结果。但论文总结了现有VLA模型在自动驾驶领域的应用,并指出了该领域面临的挑战和未来发展方向。通过对现有方法的分析和比较,论文为研究人员提供了一个全面的视角,有助于推动VLA技术在自动驾驶领域的进一步发展。
🎯 应用场景
该研究成果可应用于各种自动驾驶场景,例如城市道路、高速公路和越野环境。VLA模型有望提高自动驾驶系统的安全性、可靠性和用户体验,并促进自动驾驶技术的商业化落地。此外,该研究还可以为其他机器人应用提供借鉴,例如无人机、服务机器人和工业机器人。
📄 摘要(原文)
Autonomous driving has long relied on modular "Perception-Decision-Action" pipelines, where hand-crafted interfaces and rule-based components often break down in complex or long-tailed scenarios. Their cascaded design further propagates perception errors, degrading downstream planning and control. Vision-Action (VA) models address some limitations by learning direct mappings from visual inputs to actions, but they remain opaque, sensitive to distribution shifts, and lack structured reasoning or instruction-following capabilities. Recent progress in Large Language Models (LLMs) and multimodal learning has motivated the emergence of Vision-Language-Action (VLA) frameworks, which integrate perception with language-grounded decision making. By unifying visual understanding, linguistic reasoning, and actionable outputs, VLAs offer a pathway toward more interpretable, generalizable, and human-aligned driving policies. This work provides a structured characterization of the emerging VLA landscape for autonomous driving. We trace the evolution from early VA approaches to modern VLA frameworks and organize existing methods into two principal paradigms: End-to-End VLA, which integrates perception, reasoning, and planning within a single model, and Dual-System VLA, which separates slow deliberation (via VLMs) from fast, safety-critical execution (via planners). Within these paradigms, we further distinguish subclasses such as textual vs. numerical action generators and explicit vs. implicit guidance mechanisms. We also summarize representative datasets and benchmarks for evaluating VLA-based driving systems and highlight key challenges and open directions, including robustness, interpretability, and instruction fidelity. Overall, this work aims to establish a coherent foundation for advancing human-compatible autonomous driving systems.