mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
作者: Jonas Pai, Liam Achenbach, Victoriano Montesinos, Benedek Forrai, Oier Mees, Elvis Nava
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-12-17 (更新: 2025-12-19)
备注: Revised Introduction, Related Work, and Appendix. Additional minor notational and grammatical fixes
💡 一句话要点
提出mimic-video,一种基于视频的动作模型,提升机器人控制的泛化性和样本效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人控制 视频动作模型 逆动力学模型 流匹配 视觉动态
📋 核心要点
- 现有VLA模型依赖大量专家数据,难以学习物理动力学和时间依赖性。
- mimic-video利用视频预训练捕获语义和视觉动态,降低对专家数据的依赖。
- 实验表明,mimic-video在机器人操作任务中,样本效率提升10倍,收敛速度提升2倍。
📝 摘要(中文)
现有的机器人操作视觉-语言-动作模型(VLA)依赖于在大型但分散的静态网络数据上预训练的视觉-语言骨干网络。尽管语义泛化能力有所提高,但策略必须仅从机器人轨迹中隐式地推断复杂的物理动力学和时间依赖性。这种依赖性造成了不可持续的数据负担,需要持续的大规模专家数据收集,以弥补缺乏内在物理理解的不足。我们认为,虽然视觉-语言预训练有效地捕获了语义先验,但它仍然对物理因果关系视而不见。一种更有效的范例是利用视频在预训练期间共同捕获语义和视觉动态,从而隔离剩余的低级控制任务。为此,我们引入了mimic-video,一种新颖的视频-动作模型(VAM),它将预训练的互联网规模视频模型与基于流匹配的动作解码器配对,该解码器以其潜在表示为条件。解码器充当逆动力学模型(IDM),从视频空间动作计划的潜在表示生成低级机器人动作。我们广泛的评估表明,我们的方法在模拟和真实世界的机器人操作任务上实现了最先进的性能,与传统的VLA架构相比,样本效率提高了10倍,收敛速度提高了2倍。
🔬 方法详解
问题定义:现有视觉-语言-动作模型(VLA)在机器人控制任务中,依赖于大规模静态图像数据进行预训练,缺乏对物理世界动态的理解。这导致模型需要从大量的机器人轨迹数据中学习复杂的物理规律,数据需求量大,泛化能力受限。现有方法的痛点在于无法有效利用视频数据中蕴含的物理因果关系。
核心思路:论文的核心思路是利用视频数据进行预训练,从而让模型能够同时学习语义信息和视觉动态信息。通过这种方式,模型可以更好地理解物理世界的规律,从而降低对机器人轨迹数据的依赖,提高样本效率和泛化能力。作者认为,视觉-语言预训练虽然能捕获语义信息,但忽略了物理因果关系,而视频数据恰好可以弥补这一缺陷。
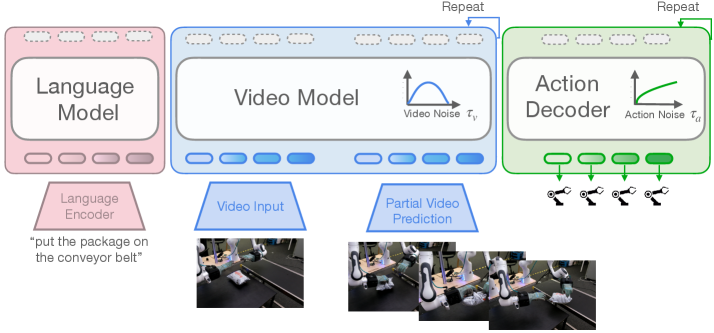
技术框架:mimic-video模型主要包含两个模块:预训练的互联网规模视频模型和基于流匹配的动作解码器。视频模型负责提取视频的潜在表示,动作解码器则根据这些潜在表示生成低级机器人动作。整个流程可以看作是:视频 -> 潜在表示 -> 机器人动作。动作解码器充当逆动力学模型(IDM),将视频空间的动作计划转化为实际的机器人控制指令。
关键创新:该论文的关键创新在于提出了视频-动作模型(VAM)的概念,并将其应用于机器人控制领域。VAM通过视频预训练的方式,让模型能够学习到物理世界的动态信息,从而提高了样本效率和泛化能力。与传统的VLA模型相比,VAM更加注重利用视频数据中蕴含的物理因果关系。
关键设计:论文使用了预训练的互联网规模视频模型,例如,可能是基于Transformer的视频模型。动作解码器采用了基于流匹配的方法,这是一种生成模型,可以学习从视频潜在空间到动作空间的映射。具体的损失函数可能包括流匹配损失和动作预测损失。网络结构细节和超参数设置在论文中应该有更详细的描述,但摘要中未明确提及。
🖼️ 关键图片
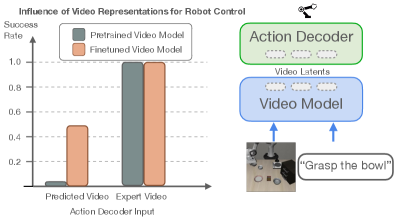

📊 实验亮点
实验结果表明,mimic-video在模拟和真实世界的机器人操作任务上均取得了state-of-the-art的性能。与传统的VLA架构相比,mimic-video的样本效率提高了10倍,收敛速度提高了2倍。这些数据表明,基于视频的动作模型在机器人控制领域具有显著的优势。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如自动化装配、物流分拣、家庭服务机器人等。通过提高样本效率和泛化能力,可以降低机器人部署的成本和难度,加速机器人在实际场景中的应用。未来,该方法有望扩展到更复杂的机器人任务,例如多机器人协作、自主导航等。
📄 摘要(原文)
Prevailing Vision-Language-Action Models (VLAs) for robotic manipulation are built upon vision-language backbones pretrained on large-scale, but disconnected static web data. As a result, despite improved semantic generalization, the policy must implicitly infer complex physical dynamics and temporal dependencies solely from robot trajectories. This reliance creates an unsustainable data burden, necessitating continuous, large-scale expert data collection to compensate for the lack of innate physical understanding. We contend that while vision-language pretraining effectively captures semantic priors, it remains blind to physical causality. A more effective paradigm leverages video to jointly capture semantics and visual dynamics during pretraining, thereby isolating the remaining task of low-level control. To this end, we introduce mimic-video, a novel Video-Action Model (VAM) that pairs a pretrained Internet-scale video model with a flow matching-based action decoder conditioned on its latent representations. The decoder serves as an Inverse Dynamics Model (IDM), generating low-level robot actions from the latent representation of video-space action plans. Our extensive evaluation shows that our approach achieves state-of-the-art performance on simulated and real-world robotic manipulation tasks, improving sample efficiency by 10x and convergence speed by 2x compared to traditional VLA architectures.