VLA-AN: An Efficient and Onboard Vision-Language-Action Framework for Aerial Navigation in Complex Environments
作者: Yuze Wu, Mo Zhu, Xingxing Li, Yuheng Du, Yuxin Fan, Wenjun Li, Zhichao Han, Xin Zhou, Fei Gao
分类: cs.RO, cs.AI
发布日期: 2025-12-17 (更新: 2025-12-19)
💡 一句话要点
VLA-AN:用于复杂环境无人机自主导航的高效、端侧视觉-语言-动作框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无人机导航 视觉-语言-动作 端侧部署 3D高斯溅射 自主导航
📋 核心要点
- 现有空中导航模型存在数据域差距、缺乏时序推理、动作策略安全性不足以及难以端侧部署等问题。
- VLA-AN通过3D-GS构建高保真数据集,采用渐进式三阶段训练,并设计轻量级安全校正动作模块来解决上述问题。
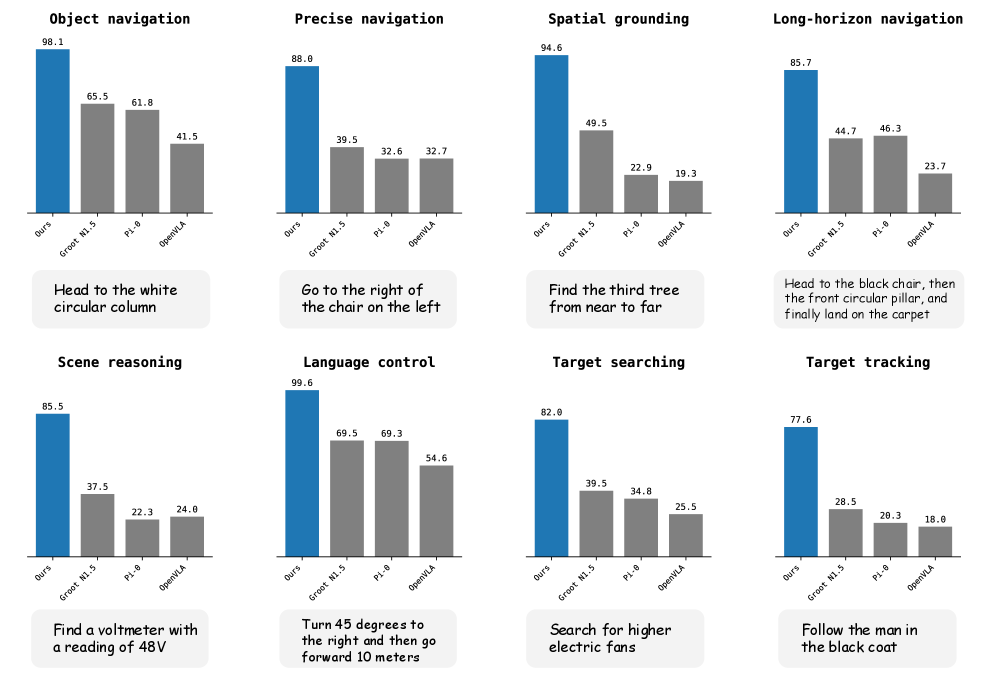
- 实验表明,VLA-AN显著提升了空间定位、场景推理和长时程导航能力,并在端侧实现了8.3倍的推理加速。
📝 摘要(中文)
本文提出了VLA-AN,一个高效的端侧视觉-语言-动作(VLA)框架,专为复杂环境中的无人机自主导航设计。VLA-AN解决了现有大型空中导航模型的四个主要限制:数据域差距、缺乏带推理的时序导航、生成式动作策略的安全问题以及端侧部署约束。首先,我们构建了一个高保真数据集,利用3D高斯溅射(3D-GS)有效地弥合了域差距。其次,我们引入了一个渐进式三阶段训练框架,依次强化场景理解、核心飞行技能和复杂导航能力。第三,我们设计了一个轻量级的实时动作模块,并结合了几何安全校正。该模块确保快速、无碰撞和稳定的指令生成,从而减轻了随机生成策略中固有的安全风险。最后,通过对端侧部署流程的深度优化,VLA-AN在资源受限的无人机上实现了强大的实时推理,吞吐量提高了8.3倍。大量实验表明,VLA-AN显著提高了空间定位、场景推理和长时程导航能力,单任务成功率最高达到98.1%,为轻型空中机器人实现全链闭环自主提供了一种高效、实用的解决方案。
🔬 方法详解
问题定义:现有的大型空中导航模型在实际应用中面临诸多挑战。首先,仿真数据与真实环境存在显著的域差距,导致模型泛化能力不足。其次,模型缺乏对环境的时序理解和推理能力,难以应对复杂导航任务。此外,基于生成式动作策略的模型存在安全隐患,容易产生不稳定的飞行指令。最后,大型模型难以在资源受限的无人机平台上进行端侧部署。
核心思路:VLA-AN的核心思路是构建一个高效、安全且易于部署的视觉-语言-动作框架,以解决复杂环境下的无人机自主导航问题。该框架通过高保真数据生成、渐进式训练和轻量级安全校正动作模块,实现了对环境的准确理解、稳定的飞行控制和高效的端侧推理。
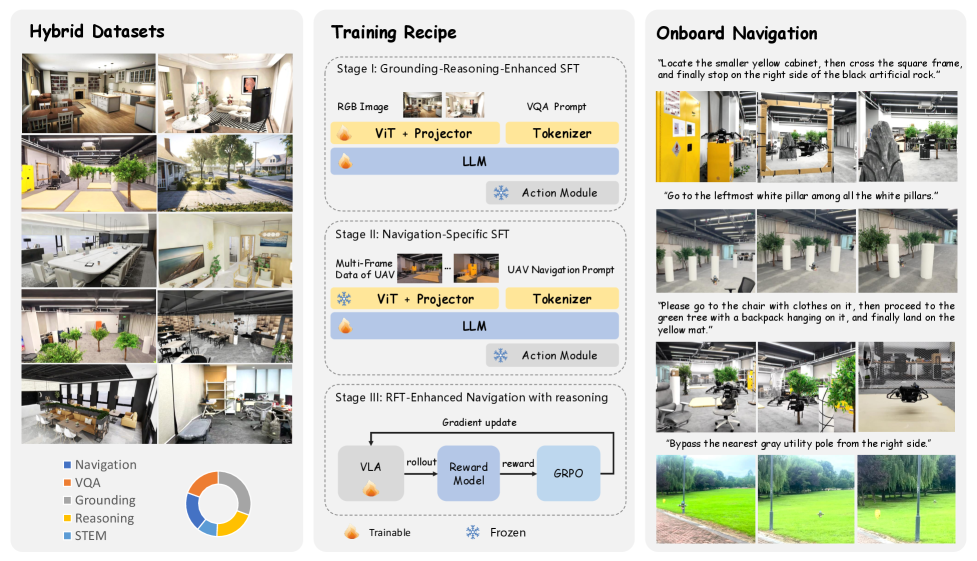
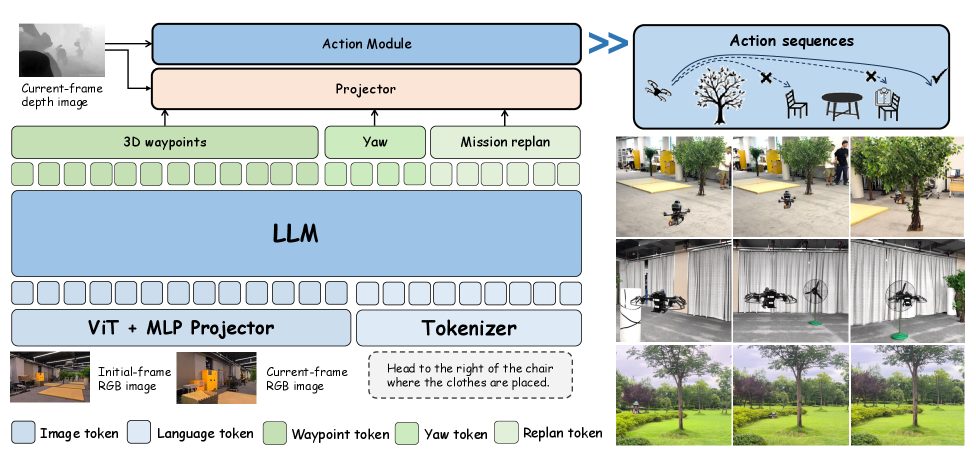
技术框架:VLA-AN框架包含三个主要阶段:数据生成、模型训练和端侧部署。数据生成阶段利用3D高斯溅射(3D-GS)技术构建高保真数据集,弥合了仿真数据与真实环境之间的域差距。模型训练阶段采用渐进式三阶段训练策略,依次强化场景理解、核心飞行技能和复杂导航能力。端侧部署阶段通过深度优化,实现了在资源受限的无人机平台上进行实时推理。
关键创新:VLA-AN的关键创新在于以下几个方面:1) 利用3D-GS技术构建高保真数据集,有效弥合了域差距;2) 提出渐进式三阶段训练框架,提升了模型的导航能力;3) 设计轻量级安全校正动作模块,确保了飞行安全;4) 优化端侧部署流程,实现了实时推理。
关键设计:在数据生成阶段,使用了高质量的3D-GS模型来渲染逼真的场景图像。在模型训练阶段,损失函数包括场景理解损失、飞行技能损失和导航损失。轻量级安全校正动作模块采用几何方法进行碰撞检测和轨迹优化,确保飞行安全。端侧部署阶段使用了模型量化、剪枝等技术来降低模型大小和计算复杂度。
🖼️ 关键图片
📊 实验亮点
VLA-AN在多个导航任务中取得了显著的性能提升,单任务成功率最高达到98.1%。与现有方法相比,VLA-AN在空间定位、场景推理和长时程导航方面均表现出更强的能力。此外,VLA-AN在端侧实现了8.3倍的推理加速,使其能够在资源受限的无人机平台上进行实时部署。
🎯 应用场景
VLA-AN可应用于多种场景,如物流配送、环境监测、灾害救援和农业巡检等。该框架能够提高无人机在复杂环境下的自主导航能力,降低人工干预的需求,从而提高工作效率和安全性。未来,VLA-AN有望成为轻型空中机器人实现全链闭环自主的关键技术。
📄 摘要(原文)
This paper proposes VLA-AN, an efficient and onboard Vision-Language-Action (VLA) framework dedicated to autonomous drone navigation in complex environments. VLA-AN addresses four major limitations of existing large aerial navigation models: the data domain gap, insufficient temporal navigation with reasoning, safety issues with generative action policies, and onboard deployment constraints. First, we construct a high-fidelity dataset utilizing 3D Gaussian Splatting (3D-GS) to effectively bridge the domain gap. Second, we introduce a progressive three-stage training framework that sequentially reinforces scene comprehension, core flight skills, and complex navigation capabilities. Third, we design a lightweight, real-time action module coupled with geometric safety correction. This module ensures fast, collision-free, and stable command generation, mitigating the safety risks inherent in stochastic generative policies. Finally, through deep optimization of the onboard deployment pipeline, VLA-AN achieves a robust real-time 8.3x improvement in inference throughput on resource-constrained UAVs. Extensive experiments demonstrate that VLA-AN significantly improves spatial grounding, scene reasoning, and long-horizon navigation, achieving a maximum single-task success rate of 98.1%, and providing an efficient, practical solution for realizing full-chain closed-loop autonomy in lightweight aerial robots.