Context Representation via Action-Free Transformer encoder-decoder for Meta Reinforcement Learning
作者: Amir M. Soufi Enayati, Homayoun Honari, Homayoun Najjaran
分类: cs.RO
发布日期: 2025-12-16 (更新: 2025-12-17)
💡 一句话要点
提出CRAFT:一种基于无动作Transformer的元强化学习上下文表示方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 元强化学习 上下文表示 Transformer 无动作学习 机器人控制
📋 核心要点
- 传统元强化学习方法依赖动作信息进行任务推断,导致任务推断与特定策略绑定,泛化能力受限。
- CRAFT通过无动作Transformer编码器-解码器,仅从状态和奖励序列推断任务表示,解耦任务推断与策略优化。
- 实验表明,CRAFT在MetaWorld ML-10基准测试中,相比现有方法,实现了更快的适应、更好的泛化和更有效的探索。
📝 摘要(中文)
强化学习(RL)使机器人能够在不确定环境中运行,但标准方法通常难以泛化到未见过的任务。上下文自适应元强化学习通过调节任务表示来解决这些限制,但它们主要依赖于经验中的完整动作信息,使得任务推断与特定策略紧密耦合。本文介绍了一种通过无动作Transformer编码器-解码器(CRAFT)实现的上下文表示方法,这是一种仅从状态和奖励序列推断任务表示的信念模型。通过消除对动作的依赖,CRAFT将任务推断与策略优化解耦,支持模块化训练,并利用摊销变分推断进行可扩展的信念更新。该模型建立在具有旋转位置嵌入的Transformer编码器-解码器之上,可以捕获长程时间依赖性,并稳健地编码参数和非参数任务变化。在MetaWorld ML-10机器人操作基准上的实验表明,与上下文自适应元强化学习基线相比,CRAFT实现了更快的适应、改进的泛化和更有效的探索。这些发现突出了无动作推断作为机器人控制中可扩展RL的基础的潜力。
🔬 方法详解
问题定义:现有元强化学习方法在进行任务表征学习时,通常需要依赖完整的动作信息。这使得任务推断过程与特定的策略紧密耦合,限制了模型的泛化能力,尤其是在面对未知的任务时。此外,这种耦合也使得模型的训练和优化变得复杂,难以进行模块化设计。
核心思路:CRAFT的核心思路是通过去除对动作的依赖,仅利用状态和奖励序列来推断任务表征。这种无动作的推断方式将任务推断与策略优化解耦,从而提高了模型的泛化能力和训练效率。通过学习一个与策略无关的任务表征,CRAFT可以更好地适应新的任务,并支持模块化的训练。
技术框架:CRAFT采用Transformer编码器-解码器结构,其中编码器负责从状态和奖励序列中提取特征,解码器则基于这些特征生成任务表征。整个框架采用摊销变分推断进行训练,以实现可扩展的信念更新。具体来说,模型首先使用编码器将状态和奖励序列编码成一个潜在的任务表征,然后使用解码器从该潜在表征中重构状态和奖励序列。通过最小化重构误差,模型可以学习到能够有效表征任务信息的潜在空间。
关键创新:CRAFT最重要的创新点在于其无动作的任务推断方法。与传统的元强化学习方法不同,CRAFT不需要依赖动作信息,而是仅通过状态和奖励序列来学习任务表征。这种方法解耦了任务推断与策略优化,使得模型可以更好地泛化到新的任务,并支持模块化的训练。此外,CRAFT还采用了Transformer编码器-解码器结构,可以有效地捕获长程时间依赖性,从而更好地理解任务的动态变化。
关键设计:CRAFT的关键设计包括:1) 使用旋转位置嵌入(Rotary Positional Embeddings)来编码状态和奖励序列中的时间信息;2) 采用Transformer编码器-解码器结构来捕获长程时间依赖性;3) 使用摊销变分推断来训练模型,并进行可扩展的信念更新;4) 设计合适的损失函数,包括重构损失和KL散度损失,以保证模型能够学习到有效的任务表征。
🖼️ 关键图片
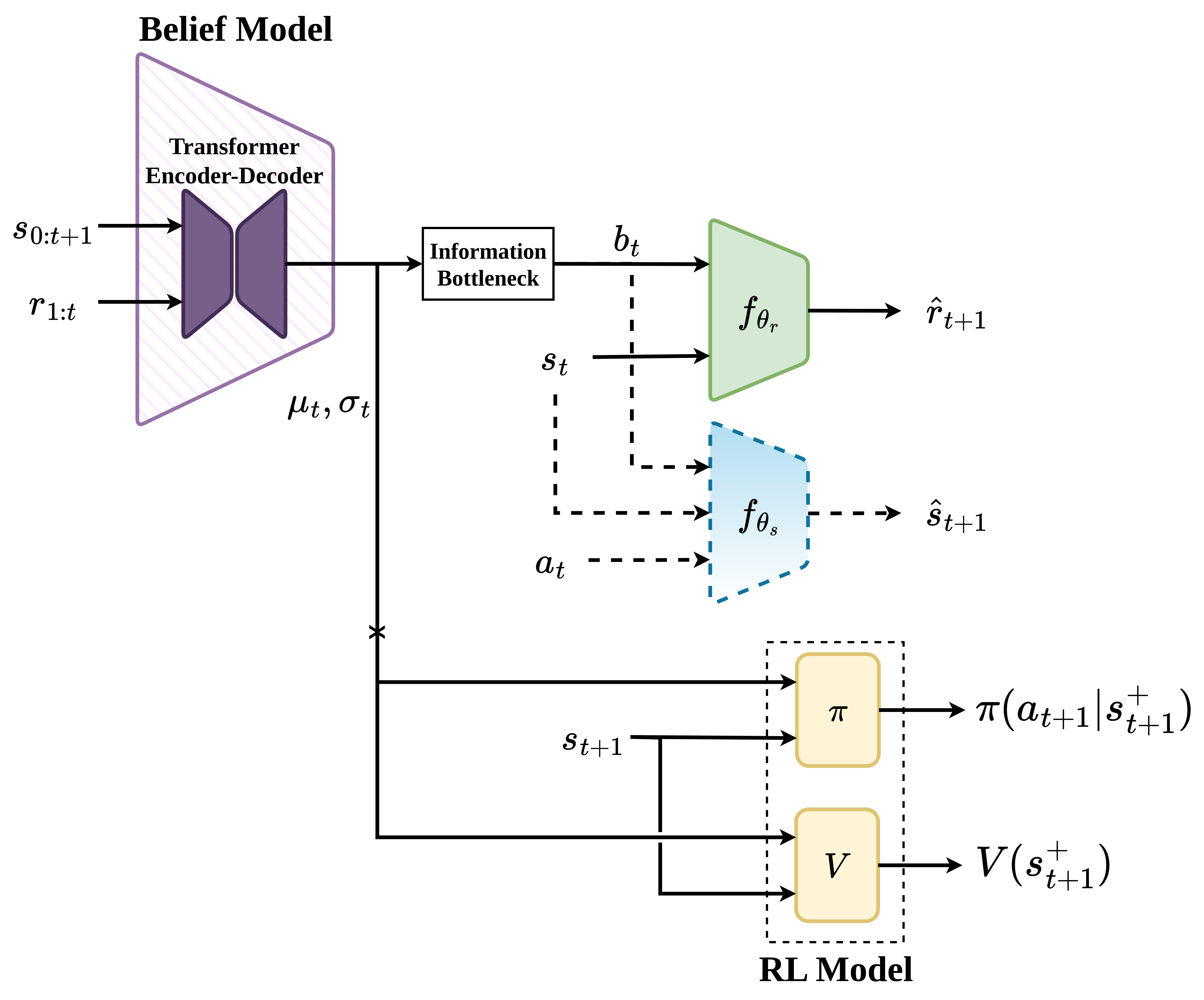
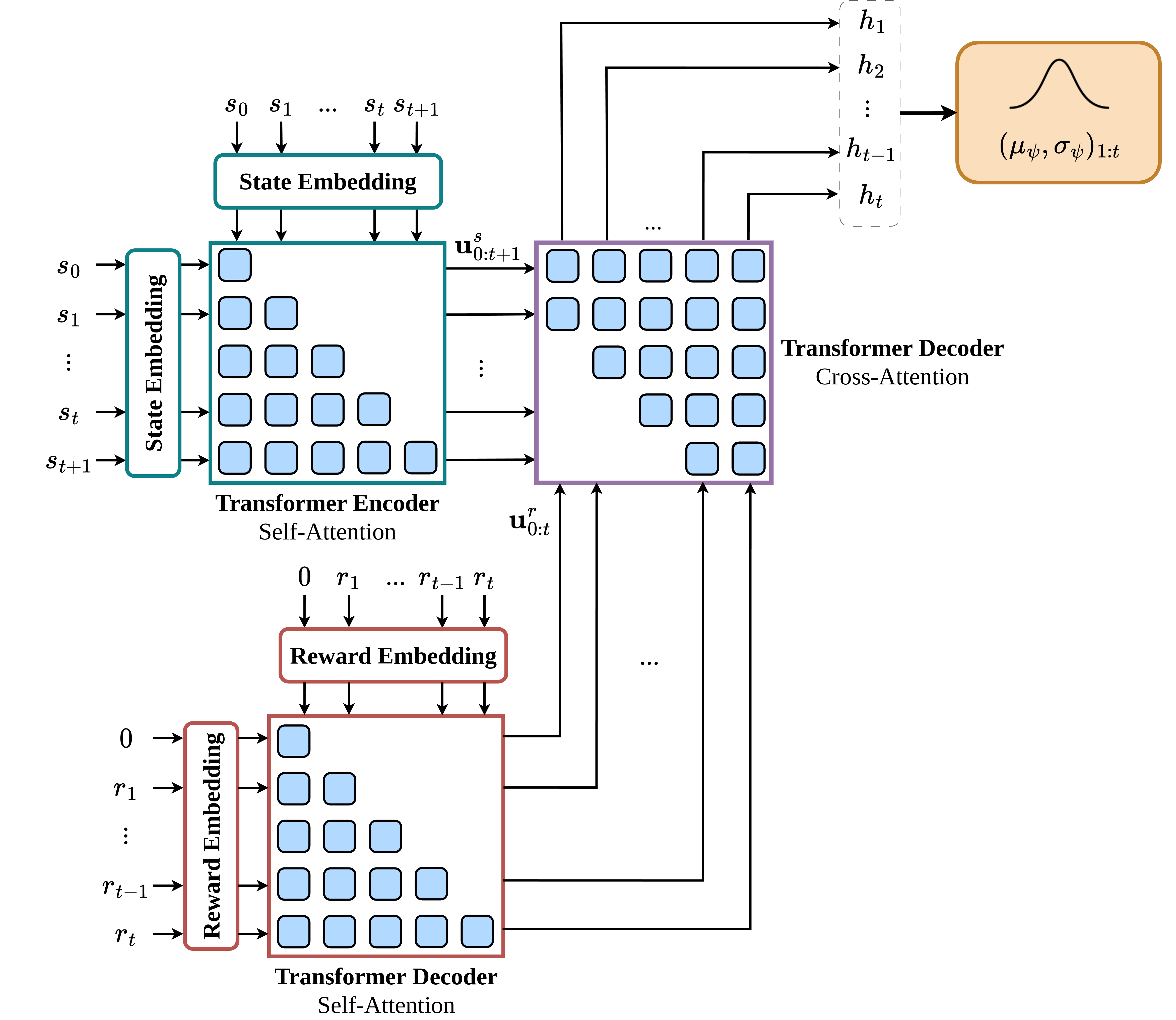
📊 实验亮点
CRAFT在MetaWorld ML-10机器人操作基准测试中取得了显著的成果。实验结果表明,与现有的上下文自适应元强化学习基线相比,CRAFT实现了更快的适应速度、更好的泛化能力和更有效的探索策略。具体来说,CRAFT在多个任务上的性能都超过了基线方法,并且在面对未见过的任务时,其性能下降幅度也明显小于基线方法。
🎯 应用场景
CRAFT的潜在应用领域包括机器人控制、游戏AI、自动驾驶等。通过学习与策略无关的任务表征,CRAFT可以使智能体更好地适应新的环境和任务,从而提高其在复杂和不确定环境中的表现。此外,CRAFT的模块化设计也使其易于集成到现有的强化学习系统中,从而加速了强化学习技术在实际应用中的部署。
📄 摘要(原文)
Reinforcement learning (RL) enables robots to operate in uncertain environments, but standard approaches often struggle with poor generalization to unseen tasks. Context-adaptive meta reinforcement learning addresses these limitations by conditioning on the task representation, yet they mostly rely on complete action information in the experience making task inference tightly coupled to a specific policy. This paper introduces Context Representation via Action Free Transformer encoder decoder (CRAFT), a belief model that infers task representations solely from sequences of states and rewards. By removing the dependence on actions, CRAFT decouples task inference from policy optimization, supports modular training, and leverages amortized variational inference for scalable belief updates. Built on a transformer encoder decoder with rotary positional embeddings, the model captures long range temporal dependencies and robustly encodes both parametric and non-parametric task variations. Experiments on the MetaWorld ML-10 robotic manipulation benchmark show that CRAFT achieves faster adaptation, improved generalization, and more effective exploration compared to context adaptive meta--RL baselines. These findings highlight the potential of action-free inference as a foundation for scalable RL in robotic control.