RoboTracer: Mastering Spatial Trace with Reasoning in Vision-Language Models for Robotics
作者: Enshen Zhou, Cheng Chi, Yibo Li, Jingkun An, Jiayuan Zhang, Shanyu Rong, Yi Han, Yuheng Ji, Mengzhen Liu, Pengwei Wang, Zhongyuan Wang, Lu Sheng, Shanghang Zhang
分类: cs.RO, cs.CV
发布日期: 2025-12-15 (更新: 2026-01-06)
备注: Project page: https://zhoues.github.io/RoboTracer
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
RoboTracer:利用视觉-语言模型中的推理能力,掌握机器人空间轨迹跟踪
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人 空间轨迹跟踪 视觉-语言模型 强化学习 3D感知 多步推理 具身智能 度量学习
📋 核心要点
- 现有方法在机器人空间轨迹跟踪任务中,难以进行多步度量基础推理和处理复杂的空间指代。
- RoboTracer通过通用空间编码器和回归监督解码器,增强尺度感知,并利用强化学习进行多步推理。
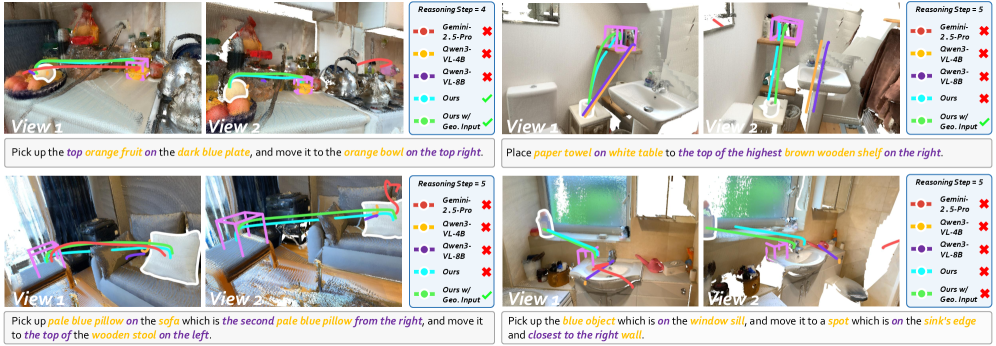
- RoboTracer在TraceSpatial-Bench上大幅超越Gemini-2.5-Pro,并在真实机器人上成功执行长时程动态任务。
📝 摘要(中文)
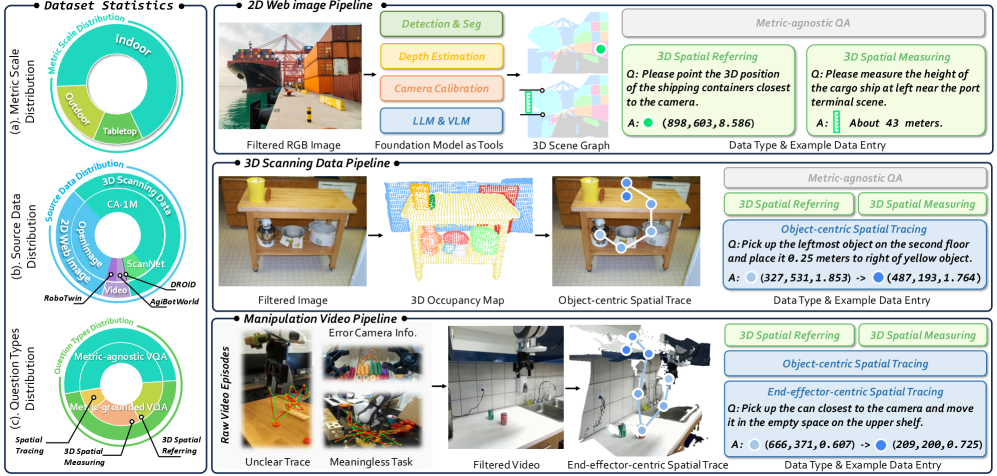
空间轨迹跟踪是机器人的一项基本具身交互能力,它具有内在的挑战性,因为它需要多步度量基础推理,以及复杂的空间指代和真实世界的度量测量。然而,现有的方法难以应对这种组合任务。为此,我们提出了RoboTracer,一个3D感知的VLM,它首先通过一个通用的空间编码器和一个回归监督的解码器来实现3D空间指代和测量,以增强监督微调(SFT)期间的尺度感知。此外,RoboTracer通过强化微调(RFT)和度量敏感的过程奖励来推进多步度量基础推理,监督关键的中间感知线索,以准确地生成空间轨迹。为了支持SFT和RFT训练,我们引入了TraceSpatial,一个包含3000万个QA对的大规模数据集,跨越室外/室内/桌面场景,并支持复杂的推理过程(最多9步)。我们进一步提出了TraceSpatial-Bench,一个具有挑战性的基准,填补了评估空间轨迹跟踪的空白。实验结果表明,RoboTracer在空间理解、测量和指代方面优于基线,平均成功率为79.1%,并且在TraceSpatial-Bench上取得了SOTA性能,大幅超过Gemini-2.5-Pro 36%的准确率。值得注意的是,RoboTracer可以与各种控制策略集成,以在杂乱的真实世界场景中执行各种机器人(UR5、G1人形机器人)上的长时程动态任务。
🔬 方法详解
问题定义:论文旨在解决机器人空间轨迹跟踪问题,即让机器人在复杂环境中,根据指令进行精确的空间定位和移动。现有方法难以有效处理多步推理、空间指代和真实尺度测量,导致轨迹跟踪精度不足。
核心思路:论文的核心思路是构建一个3D感知的视觉-语言模型(VLM),该模型能够理解空间关系、进行精确测量,并通过强化学习进行多步推理,从而生成准确的空间轨迹。通过监督学习和强化学习相结合的方式,提升模型在真实场景中的泛化能力。
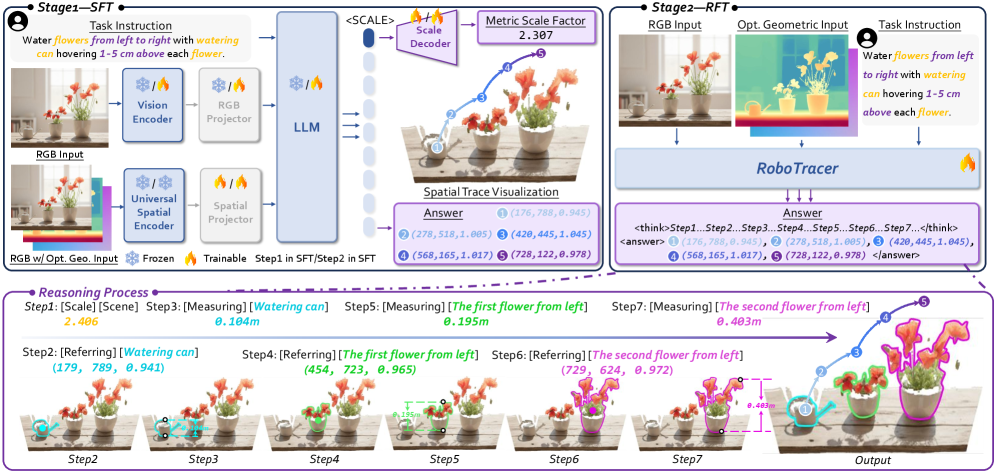
技术框架:RoboTracer的技术框架主要包含以下几个模块:1) 通用空间编码器:用于提取场景的3D空间特征。2) 回归监督解码器:用于进行空间指代和测量,增强尺度感知。3) 强化学习模块:利用度量敏感的过程奖励,进行多步推理,生成空间轨迹。整个流程包括数据收集与标注、模型预训练、监督微调(SFT)和强化微调(RFT)四个阶段。
关键创新:RoboTracer的关键创新在于:1) 提出了一个通用的空间编码器,能够有效提取3D空间特征。2) 引入了回归监督解码器,增强了模型对尺度的感知能力。3) 利用强化学习,通过度量敏感的过程奖励,实现了多步推理。4) 构建了大规模数据集TraceSpatial和基准TraceSpatial-Bench,为模型训练和评估提供了支持。
关键设计:在数据方面,构建了包含3000万QA对的大规模数据集TraceSpatial,覆盖多种场景和复杂的推理过程。在模型训练方面,采用了监督微调(SFT)和强化微调(RFT)相结合的方式,其中RFT使用了度量敏感的过程奖励,以监督关键的中间感知线索。具体网络结构和损失函数细节未知。
🖼️ 关键图片
📊 实验亮点
RoboTracer在TraceSpatial-Bench上取得了显著的性能提升,平均成功率达到79.1%,超越Gemini-2.5-Pro 36%的准确率。此外,RoboTracer还成功地集成到UR5和G1人形机器人上,并在真实的、杂乱的场景中执行了长时程动态任务,验证了其在实际应用中的有效性。
🎯 应用场景
RoboTracer在机器人导航、智能家居、工业自动化等领域具有广泛的应用前景。它可以帮助机器人在复杂环境中进行精确的定位和移动,从而实现更智能、更高效的自动化任务。例如,在仓库中,机器人可以根据指令准确地找到目标物品并进行搬运;在智能家居中,机器人可以根据用户的语音指令进行室内导航和物品交互。
📄 摘要(原文)
Spatial tracing, as a fundamental embodied interaction ability for robots, is inherently challenging as it requires multi-step metric-grounded reasoning compounded with complex spatial referring and real-world metric measurement. However, existing methods struggle with this compositional task. To this end, we propose RoboTracer, a 3D-aware VLM that first achieves both 3D spatial referring and measuring via a universal spatial encoder and a regression-supervised decoder to enhance scale awareness during supervised fine-tuning (SFT). Moreover, RoboTracer advances multi-step metric-grounded reasoning via reinforcement fine-tuning (RFT) with metric-sensitive process rewards, supervising key intermediate perceptual cues to accurately generate spatial traces. To support SFT and RFT training, we introduce TraceSpatial, a large-scale dataset of 30M QA pairs, spanning outdoor/indoor/tabletop scenes and supporting complex reasoning processes (up to 9 steps). We further present TraceSpatial-Bench, a challenging benchmark filling the gap to evaluate spatial tracing. Experimental results show that RoboTracer surpasses baselines in spatial understanding, measuring, and referring, with an average success rate of 79.1%, and also achieves SOTA performance on TraceSpatial-Bench by a large margin, exceeding Gemini-2.5-Pro by 36% accuracy. Notably, RoboTracer can be integrated with various control policies to execute long-horizon, dynamic tasks across diverse robots (UR5, G1 humanoid) in cluttered real-world scenes. See the project page at https://zhoues.github.io/RoboTracer.