Control of a Twin Rotor using Twin Delayed Deep Deterministic Policy Gradient (TD3)
作者: Zeyad Gamal, Youssef Mahran, Ayman El-Badawy
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-12-15
备注: This is the Author Accepted Manuscript version of a paper accepted for publication. The final published version is available via IEEE Xplore
期刊: 2024 28th IEEE International Conference on System Theory, Control and Computing (ICSTCC)
DOI: 10.1109/ICSTCC62912.2024.10744717
💡 一句话要点
提出基于TD3的强化学习框架,用于控制双旋翼飞行器稳定飞行与轨迹跟踪。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 TD3算法 双旋翼飞行器 轨迹跟踪 非线性控制
📋 核心要点
- 传统控制算法难以应对双旋翼飞行器复杂的非线性动力学特性,控制效果不佳。
- 利用TD3算法训练强化学习智能体,无需系统模型即可实现对双旋翼飞行器的精确控制。
- 实验结果表明,该方法在仿真和实际环境中均能有效控制双旋翼飞行器,并具有抗干扰能力。
📝 摘要(中文)
本文提出了一种基于强化学习(RL)的框架,用于控制和稳定双旋翼气动系统(TRAS)在特定的俯仰角和方位角,并跟踪给定的轨迹。TRAS的复杂动力学和非线性特性使得使用传统控制算法对其进行控制具有挑战性。然而,RL的最新发展因其在多旋翼控制中的潜在应用而引起了人们的兴趣。本文采用双延迟深度确定性策略梯度(TD3)算法来训练RL智能体。该算法适用于具有连续状态和动作空间的环境,类似于TRAS,因为它不需要系统模型。仿真结果表明了RL控制方法的有效性。接下来,使用风扰动的形式的外部扰动来测试控制器与传统PID控制器相比的有效性。最后,在实验室装置上进行了实验,以确认控制器在实际应用中的有效性。
🔬 方法详解
问题定义:论文旨在解决双旋翼气动系统(TRAS)的精确控制问题,包括稳定在特定俯仰角和方位角,以及跟踪给定的轨迹。传统控制算法难以应对TRAS的复杂动力学和非线性特性,导致控制性能下降。
核心思路:论文的核心思路是利用强化学习(RL)算法,特别是TD3算法,直接从与环境的交互中学习控制策略,而无需建立精确的系统模型。这种方法能够适应TRAS的非线性特性和不确定性。
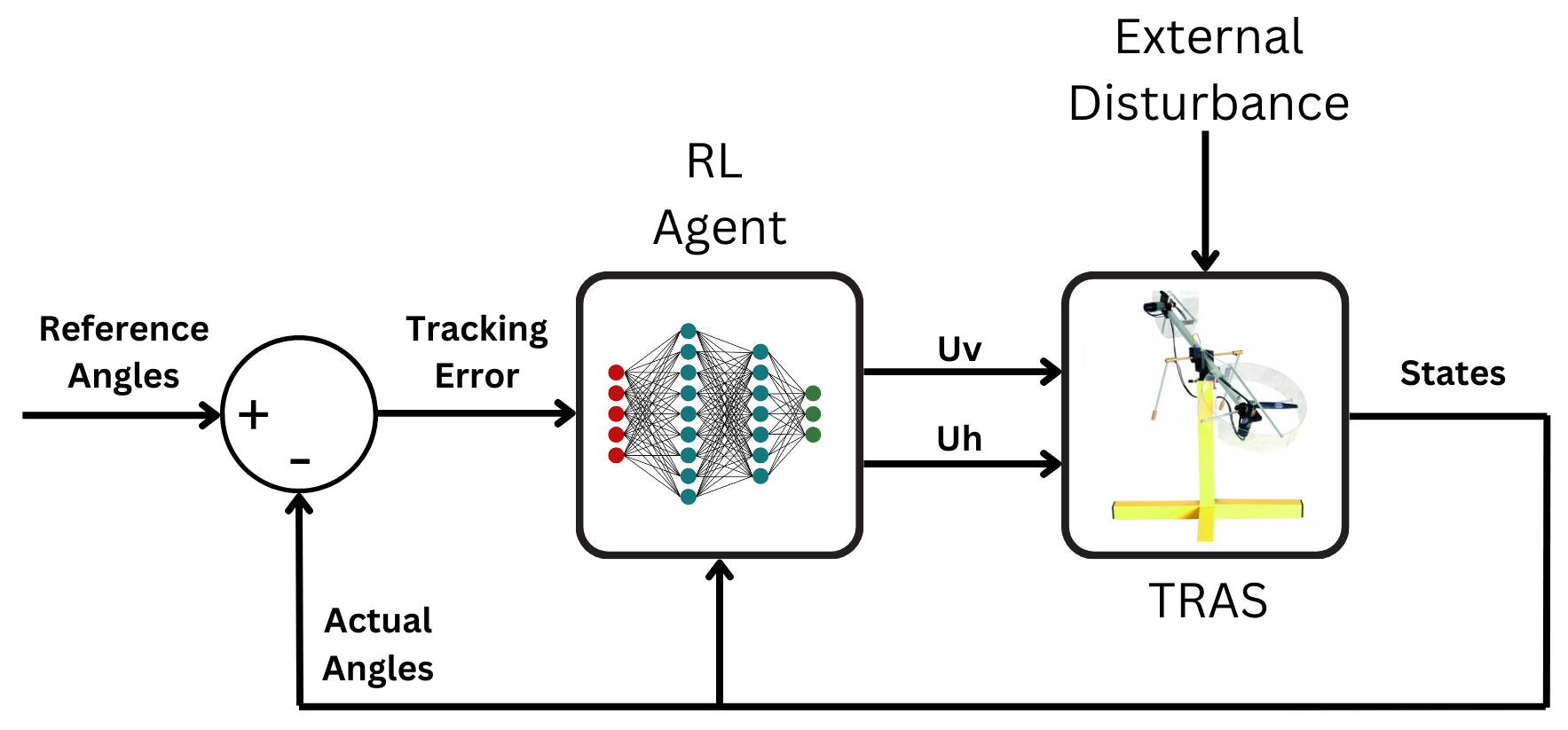
技术框架:整体框架包括一个TD3智能体和一个TRAS环境。智能体通过与环境交互,观察状态(例如,俯仰角和方位角),并采取动作(例如,施加到旋翼的控制信号)。环境根据动作更新状态,并向智能体提供奖励信号。TD3智能体使用奖励信号来更新其策略和价值函数。该过程迭代进行,直到智能体学习到最优控制策略。
关键创新:关键创新在于将TD3算法应用于双旋翼飞行器的控制。TD3算法是一种off-policy的actor-critic算法,通过引入双Q网络和目标策略平滑等机制,有效地缓解了Q函数过估计问题,提高了训练的稳定性和性能。与传统的PID控制相比,该方法无需手动调整参数,能够自动适应系统的非线性特性。
关键设计:TD3智能体包含两个actor网络和两个critic网络,用于估计策略和价值函数。奖励函数的设计至关重要,需要根据控制目标进行调整,例如,可以使用与目标角度的偏差作为负奖励。网络结构的选择需要根据状态和动作空间的维度进行调整。此外,探索噪声的添加也是一个重要的设计,可以帮助智能体探索更广泛的状态空间。
🖼️ 关键图片

📊 实验亮点
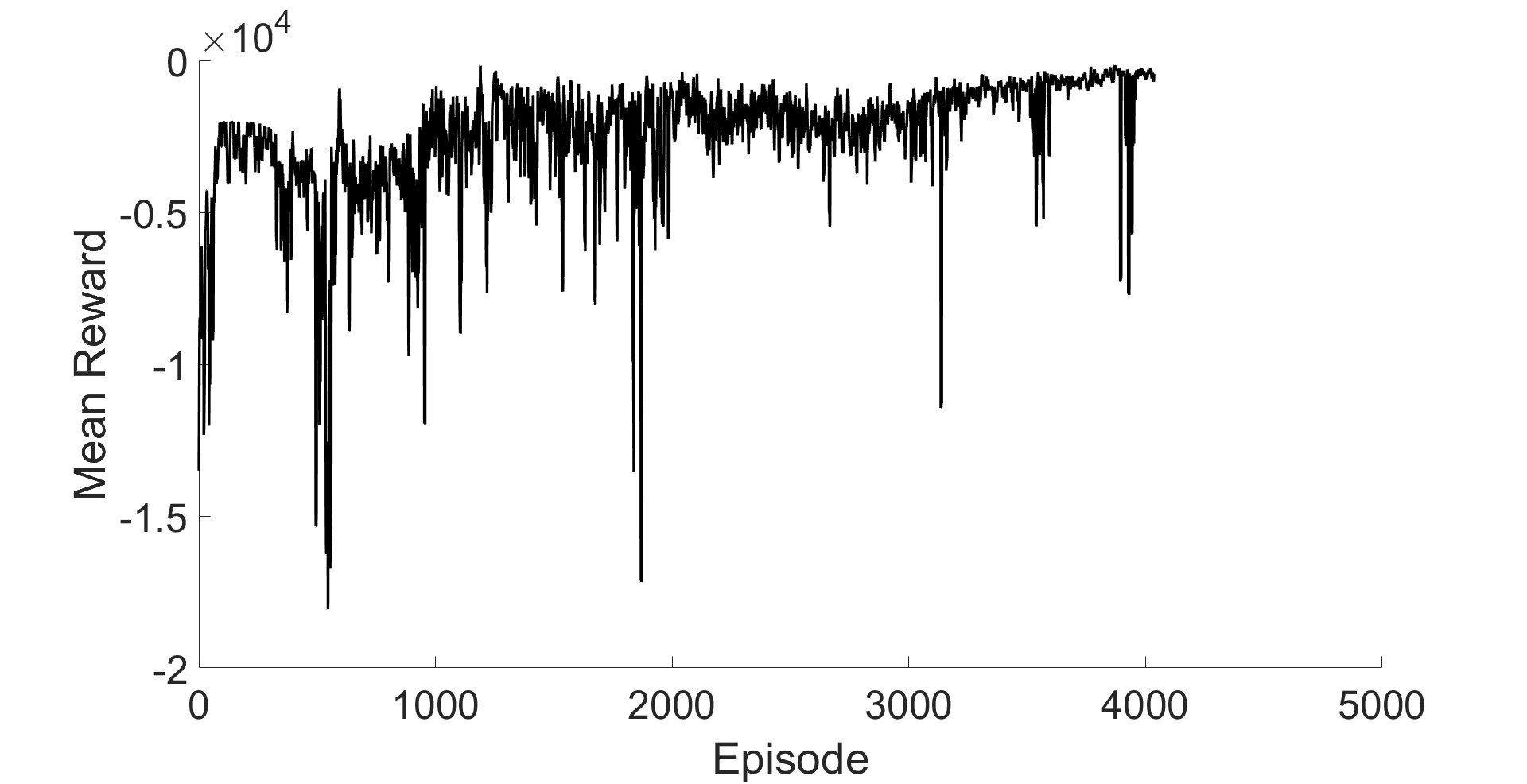
论文通过仿真和实验验证了TD3控制器的有效性。仿真结果表明,TD3控制器能够有效地稳定TRAS在特定角度,并跟踪给定的轨迹。与传统的PID控制器相比,TD3控制器在抗风扰动方面表现出更强的鲁棒性。在实验室装置上的实验结果进一步证实了TD3控制器在实际应用中的可行性。
🎯 应用场景
该研究成果可应用于无人机、飞行机器人等领域,尤其是在需要精确控制和复杂环境适应性的场景下,例如:空中物流、环境监测、灾害救援等。未来,该方法有望扩展到其他类型的多旋翼飞行器和更复杂的控制任务中,实现更智能、更自主的飞行控制。
📄 摘要(原文)
This paper proposes a reinforcement learning (RL) framework for controlling and stabilizing the Twin Rotor Aerodynamic System (TRAS) at specific pitch and azimuth angles and tracking a given trajectory. The complex dynamics and non-linear characteristics of the TRAS make it challenging to control using traditional control algorithms. However, recent developments in RL have attracted interest due to their potential applications in the control of multirotors. The Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm was used in this paper to train the RL agent. This algorithm is used for environments with continuous state and action spaces, similar to the TRAS, as it does not require a model of the system. The simulation results illustrated the effectiveness of the RL control method. Next, external disturbances in the form of wind disturbances were used to test the controller's effectiveness compared to conventional PID controllers. Lastly, experiments on a laboratory setup were carried out to confirm the controller's effectiveness in real-world applications.