OXE-AugE: A Large-Scale Robot Augmentation of OXE for Scaling Cross-Embodiment Policy Learning
作者: Guanhua Ji, Harsha Polavaram, Lawrence Yunliang Chen, Sandeep Bajamahal, Zehan Ma, Simeon Adebola, Chenfeng Xu, Ken Goldberg
分类: cs.RO, cs.AI
发布日期: 2025-12-15
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出OXE-AugE,通过大规模机器人增强扩展OXE数据集,提升跨具身策略学习能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 跨具身学习 数据增强 机器人泛化 模仿学习
📋 核心要点
- 现有OXE数据集存在数据不平衡问题,少数机器人类型占据了大部分数据,导致模型容易过拟合。
- 论文提出AugE-Toolkit,用于可扩展的机器人增强,并构建了OXE-AugE数据集,包含更多样化的机器人形态。
- 实验表明,在OXE-AugE上微调通用策略,可以显著提升在未见过的机器人上的性能,成功率提升24-45%。
📝 摘要(中文)
为了训练能够控制各种机器人形态(机械臂和夹爪组合)的通用机器人策略,需要大规模且多样化的数据集。由于为每个新的硬件平台重新收集演示数据和重新训练成本过高,本文提出可以通过增强现有机器人数据来实现迁移和泛化。Open X-Embodiment (OXE)数据集汇集了来自60多个机器人数据集的演示数据,被广泛用作训练通用策略的基础。然而,OXE数据集高度不平衡,前四种机器人类型占据了超过85%的真实数据,这可能导致对机器人-场景组合的过拟合。本文提出了AugE-Toolkit,一个可扩展的机器人增强流水线,以及OXE-AugE,一个高质量的开源数据集,通过9种不同的机器人形态增强了OXE。OXE-AugE提供了超过440万条轨迹,是原始OXE数据集的三倍多。本文系统地研究了扩展机器人增强如何影响跨具身学习。结果表明,使用不同的机械臂和夹爪增强数据集不仅提高了增强机器人的策略性能,而且提高了未见过的机器人甚至原始机器人在分布偏移下的策略性能。在物理实验中,证明了OpenVLA和$π_0$等最先进的通用策略可以通过在OXE-AugE上进行微调来受益,在四个真实世界的操作任务中,先前未见过的机器人-夹爪组合的成功率提高了24-45%。
🔬 方法详解
问题定义:现有Open X-Embodiment (OXE)数据集虽然规模较大,但存在严重的数据不平衡问题,少数几种机器人占据了绝大部分数据,导致训练出的策略容易过拟合到这些常见的机器人-场景组合上,泛化能力受限。重新为每种新的机器人硬件收集数据成本高昂,因此需要一种方法来利用现有数据进行迁移和泛化。
核心思路:论文的核心思路是通过机器人增强来扩展OXE数据集,增加机器人形态的多样性,从而缓解数据不平衡问题,提高训练出的策略在不同机器人上的泛化能力。通过AugE-Toolkit,可以高效地生成各种机器人形态的增强数据,并将其添加到原始OXE数据集中。
技术框架:整体框架包括以下几个主要步骤:1) 使用AugE-Toolkit生成新的机器人形态的增强数据。AugE-Toolkit是一个可扩展的机器人增强流水线,可以模拟不同的机械臂和夹爪组合。2) 将生成的增强数据与原始OXE数据集合并,形成OXE-AugE数据集。3) 在OXE-AugE数据集上训练或微调通用机器人策略。4) 在真实机器人上评估训练好的策略的性能。
关键创新:最重要的技术创新点在于AugE-Toolkit,它提供了一种可扩展的、高效的机器人增强方法。与以往的机器人增强方法相比,AugE-Toolkit能够生成更多样化的机器人形态,并且可以轻松地集成到现有的机器人学习流程中。此外,OXE-AugE数据集本身也是一个重要的贡献,它为跨具身策略学习提供了一个新的基准。
关键设计:AugE-Toolkit的关键设计包括:1) 参数化的机器人模型,允许灵活地配置机械臂和夹爪的几何形状和运动学参数。2) 基于物理引擎的模拟环境,用于生成真实的机器人交互数据。3) 自动化的数据生成流程,可以高效地生成大规模的增强数据。在训练策略时,可以使用各种现有的机器人学习算法,例如模仿学习、强化学习等。论文中使用了OpenVLA和$π_0$等最先进的通用策略,并在OXE-AugE数据集上进行了微调。
🖼️ 关键图片

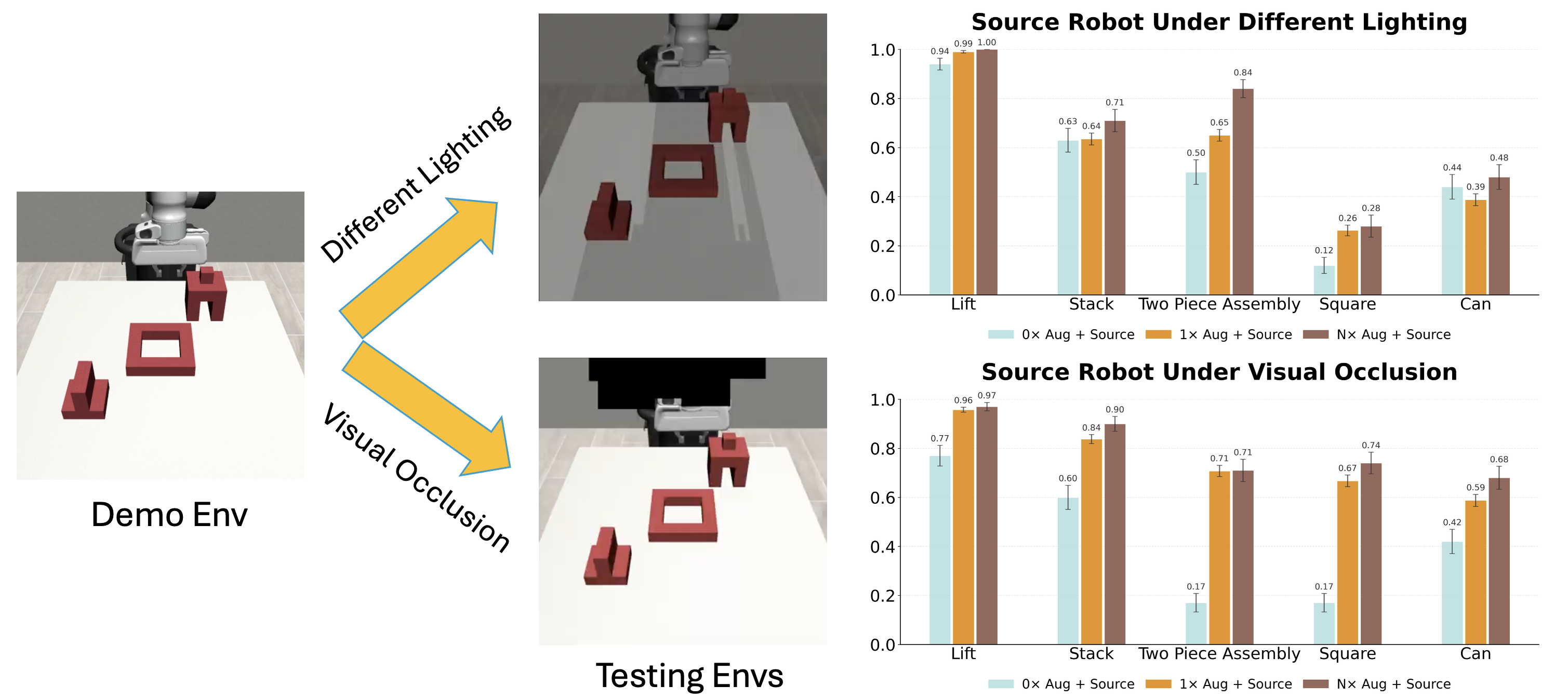
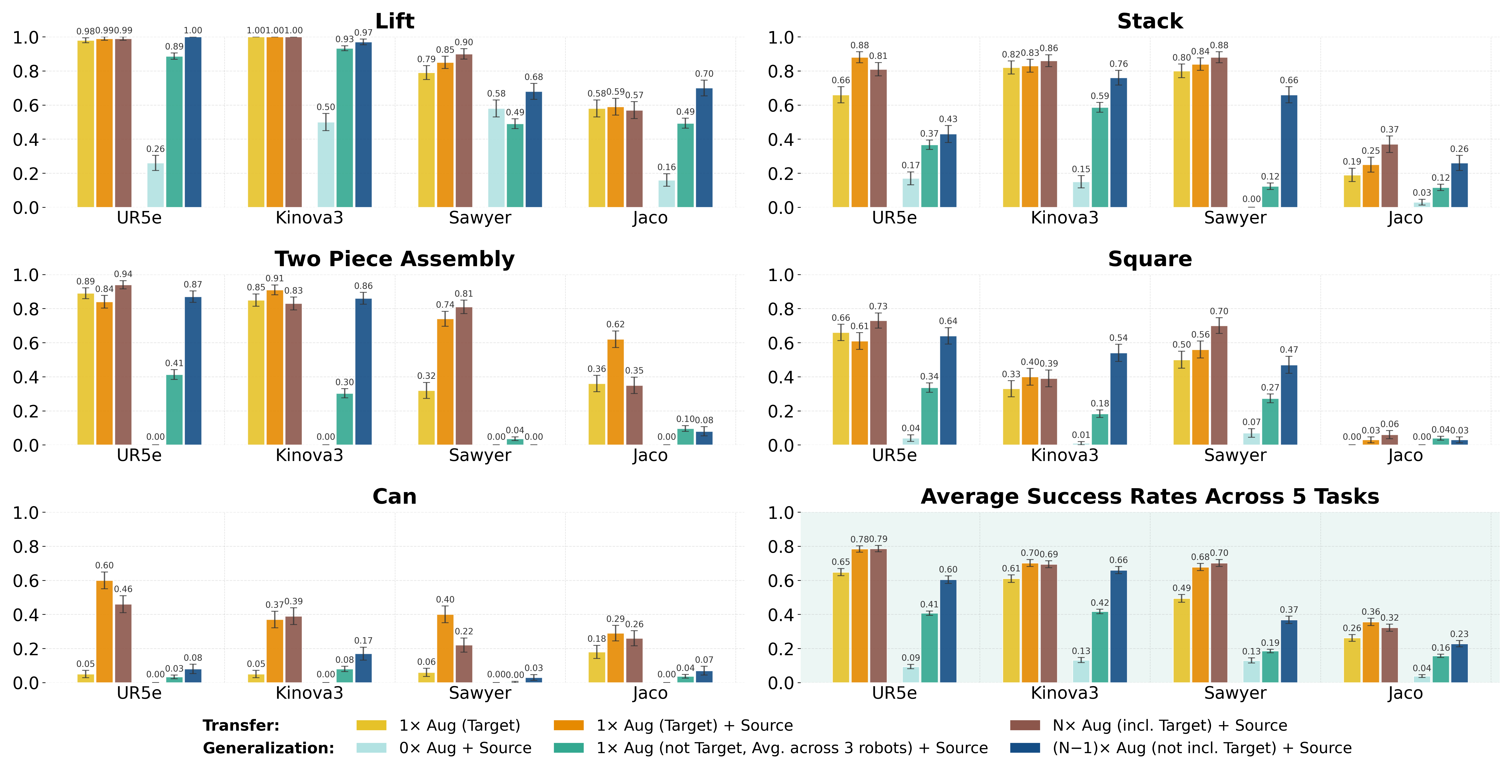
📊 实验亮点
实验结果表明,在OXE-AugE数据集上微调通用策略可以显著提升在未见过的机器人上的性能。具体来说,在四个真实世界的操作任务中,使用OXE-AugE微调后的OpenVLA和$π_0$策略在先前未见过的机器人-夹爪组合上的成功率提高了24-45%。这表明,通过机器人增强来扩展数据集可以有效地提高跨具身策略学习的泛化能力。
🎯 应用场景
该研究成果可广泛应用于机器人自动化领域,尤其是在需要控制多种不同机器人形态的场景中。例如,在柔性制造系统中,可以使用该方法训练一个通用的机器人策略,使其能够适应不同的生产任务和不同的机器人硬件。此外,该方法还可以用于机器人教育和研究,为学生和研究人员提供一个方便的平台来探索跨具身策略学习。
📄 摘要(原文)
Large and diverse datasets are needed for training generalist robot policies that have potential to control a variety of robot embodiments -- robot arm and gripper combinations -- across diverse tasks and environments. As re-collecting demonstrations and retraining for each new hardware platform are prohibitively costly, we show that existing robot data can be augmented for transfer and generalization. The Open X-Embodiment (OXE) dataset, which aggregates demonstrations from over 60 robot datasets, has been widely used as the foundation for training generalist policies. However, it is highly imbalanced: the top four robot types account for over 85\% of its real data, which risks overfitting to robot-scene combinations. We present AugE-Toolkit, a scalable robot augmentation pipeline, and OXE-AugE, a high-quality open-source dataset that augments OXE with 9 different robot embodiments. OXE-AugE provides over 4.4 million trajectories, more than triple the size of the original OXE. We conduct a systematic study of how scaling robot augmentation impacts cross-embodiment learning. Results suggest that augmenting datasets with diverse arms and grippers improves policy performance not only on the augmented robots, but also on unseen robots and even the original robots under distribution shifts. In physical experiments, we demonstrate that state-of-the-art generalist policies such as OpenVLA and $π_0$ benefit from fine-tuning on OXE-AugE, improving success rates by 24-45% on previously unseen robot-gripper combinations across four real-world manipulation tasks. Project website: https://OXE-AugE.github.io/.