PvP: Data-Efficient Humanoid Robot Learning with Proprioceptive-Privileged Contrastive Representations
作者: Mingqi Yuan, Tao Yu, Haolin Song, Bo Li, Xin Jin, Hua Chen, Wenjun Zeng
分类: cs.RO, cs.LG
发布日期: 2025-12-15
备注: 13 pages, 12 figures
💡 一句话要点
提出PvP框架,利用本体感受特权对比学习提升人形机器人数据效率
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 强化学习 对比学习 状态表示学习 本体感受 特权学习 全身控制
📋 核心要点
- 人形机器人全身控制面临样本效率挑战,现有强化学习方法难以有效应对复杂动力学和部分可观测性。
- PvP框架利用本体感受和特权状态的互补性,通过对比学习获得紧凑的任务相关潜在表示,无需手动数据增强。
- 实验表明,PvP在速度跟踪和运动模仿任务中显著提升了样本效率和最终性能,并构建了统一的评估框架SRL4Humanoid。
📝 摘要(中文)
本文提出了一种名为PvP的本体感受特权对比学习框架,旨在提高人形机器人全身控制(WBC)的学习效率和鲁棒性。针对人形机器人复杂动力学和部分可观测性导致的强化学习样本效率低下的问题,PvP利用本体感受和特权状态之间的内在互补性,学习紧凑且与任务相关的潜在表示,无需手动设计数据增强,从而实现更快、更稳定的策略学习。为了支持系统评估,作者开发了SRL4Humanoid,这是一个统一且模块化的框架,提供代表人形机器人学习的状态表示学习(SRL)方法的高质量实现。在LimX Oli机器人上的速度跟踪和运动模仿任务的实验表明,与基线SRL方法相比,PvP显著提高了样本效率和最终性能。该研究还为将SRL与RL集成以进行人形机器人WBC提供了实践见解,为数据高效的人形机器人学习提供了有价值的指导。
🔬 方法详解
问题定义:人形机器人的全身控制(WBC)需要高效且鲁棒的学习方法。然而,由于人形机器人复杂的动力学特性和环境的部分可观测性,传统的强化学习方法往往面临样本效率低下的问题,难以在实际应用中快速部署。现有方法通常需要大量的数据或手动设计的数据增强,限制了其泛化能力和适应性。
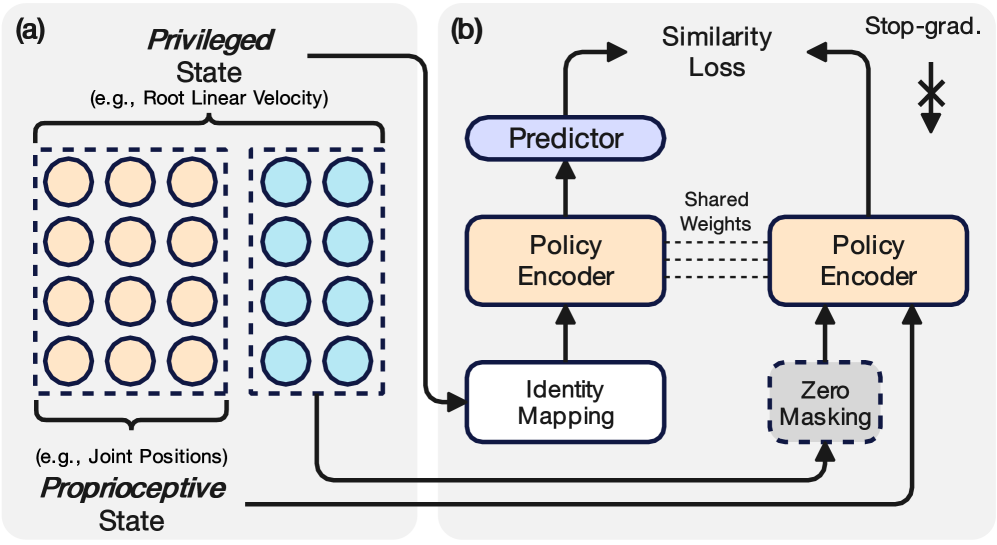
核心思路:PvP的核心思路是利用人形机器人自身的本体感受信息(如关节角度、速度等)以及在训练阶段可获得的特权状态信息(如环境的完整状态),通过对比学习的方式,学习到一种既能反映机器人自身状态,又能感知环境信息的紧凑潜在表示。这种潜在表示能够帮助机器人更好地理解当前状态,从而更有效地进行策略学习。
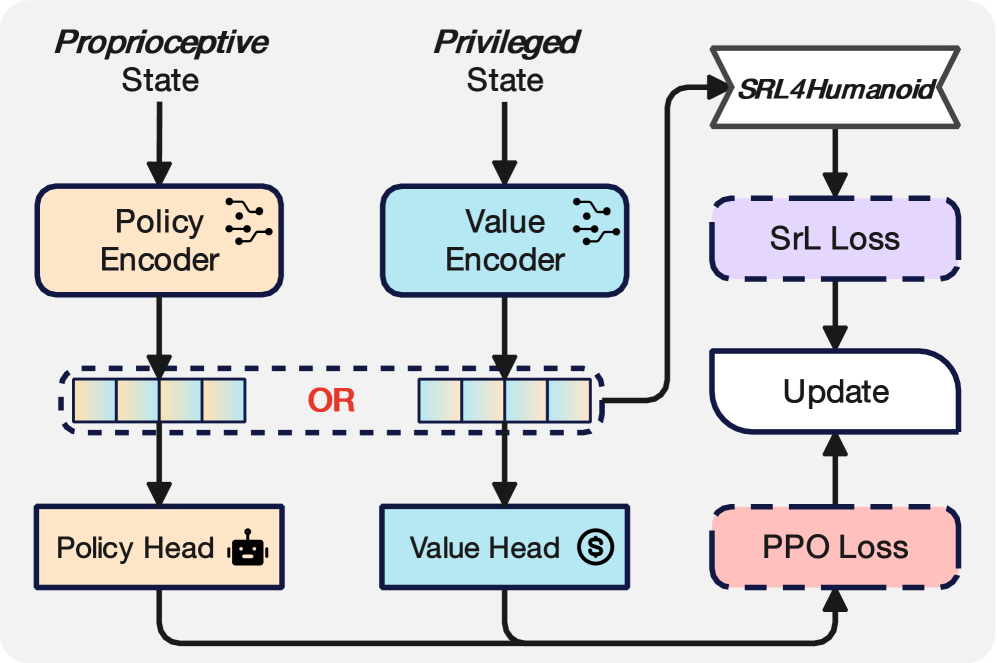
技术框架:PvP框架主要包含两个模块:状态编码器和策略学习模块。状态编码器负责将本体感受信息和特权状态信息编码成潜在表示。策略学习模块则利用这些潜在表示进行强化学习,学习控制策略。整个框架通过对比学习的方式,使得状态编码器能够学习到更具判别性的潜在表示,从而提高策略学习的效率。
关键创新:PvP的关键创新在于其利用了本体感受和特权状态之间的内在互补性,通过对比学习的方式,学习到一种既能反映机器人自身状态,又能感知环境信息的紧凑潜在表示。与现有方法相比,PvP无需手动设计数据增强,能够更有效地利用数据,提高学习效率。此外,SRL4Humanoid框架的提出,为人形机器人状态表示学习提供了一个统一的评估平台。
关键设计:PvP框架的关键设计包括:1) 使用对比损失函数来训练状态编码器,使得相似状态的潜在表示更加接近,不同状态的潜在表示更加远离;2) 设计了一种特殊的网络结构,能够有效地融合本体感受信息和特权状态信息;3) 在策略学习模块中,使用了Actor-Critic算法,并对奖励函数进行了精心设计,以提高学习的稳定性和效率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PvP框架在速度跟踪和运动模仿任务中,与基线SRL方法相比,显著提高了样本效率和最终性能。具体而言,PvP在相同训练时间内,能够达到更高的速度跟踪精度和更逼真的运动模仿效果。此外,PvP还表现出更强的鲁棒性,能够在不同的环境和任务中稳定运行。
🎯 应用场景
PvP框架在人形机器人控制领域具有广泛的应用前景,可用于提升机器人在复杂环境中的运动能力和适应性。例如,可应用于灾难救援、医疗辅助、工业制造等场景,使人形机器人能够更安全、高效地完成各种任务。此外,该研究提出的SRL4Humanoid框架,为人形机器人状态表示学习提供了一个统一的评估平台,有助于推动该领域的发展。
📄 摘要(原文)
Achieving efficient and robust whole-body control (WBC) is essential for enabling humanoid robots to perform complex tasks in dynamic environments. Despite the success of reinforcement learning (RL) in this domain, its sample inefficiency remains a significant challenge due to the intricate dynamics and partial observability of humanoid robots. To address this limitation, we propose PvP, a Proprioceptive-Privileged contrastive learning framework that leverages the intrinsic complementarity between proprioceptive and privileged states. PvP learns compact and task-relevant latent representations without requiring hand-crafted data augmentations, enabling faster and more stable policy learning. To support systematic evaluation, we develop SRL4Humanoid, the first unified and modular framework that provides high-quality implementations of representative state representation learning (SRL) methods for humanoid robot learning. Extensive experiments on the LimX Oli robot across velocity tracking and motion imitation tasks demonstrate that PvP significantly improves sample efficiency and final performance compared to baseline SRL methods. Our study further provides practical insights into integrating SRL with RL for humanoid WBC, offering valuable guidance for data-efficient humanoid robot learning.