Multi-Robot Motion Planning from Vision and Language using Heat-Inspired Diffusion
作者: Jebeom Chae, Junwoo Chang, Seungho Yeom, Yujin Kim, Jongeun Choi
分类: cs.RO
发布日期: 2025-12-15
💡 一句话要点
提出基于热扩散的多机器人视觉语言运动规划框架LCHD
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多机器人 运动规划 扩散模型 视觉语言 CLIP 碰撞避免 机器人
📋 核心要点
- 现有基于扩散的机器人运动规划方法计算成本高,泛化能力弱,难以处理多机器人和语言条件任务。
- LCHD框架结合CLIP语义先验和避碰扩散核,在可达工作空间内解析语言指令,实现分布外场景的有效规划。
- 实验表明,LCHD在成功率上优于现有方法,并降低了规划延迟,同时进行了真实机器人实验验证。
📝 摘要(中文)
扩散模型在机器人运动规划中展现了强大的能力,能够捕捉可行轨迹的多模态分布。然而,将其扩展到具有灵活的、语言条件任务规范的多机器人环境仍然有限。此外,现有的基于扩散的方法在推理过程中计算成本高昂,并且由于需要显式构建环境表示且缺乏几何可达性推理机制,因此难以泛化。为了解决这些局限性,我们提出了一种语言条件热扩散(LCHD)框架,这是一个端到端的基于视觉的框架,可以生成语言条件下的无碰撞轨迹。LCHD集成了基于CLIP的语义先验知识和一个避免碰撞的扩散核,该扩散核充当物理归纳偏置,使规划器能够在可达工作空间内严格解释语言命令。通过引导机器人找到与语义意图相匹配的可达替代方案,从而自然地处理了在可达性方面的分布外场景,同时消除了推理时对显式障碍物信息的需求。在各种受真实世界启发的地图上进行的广泛评估以及真实的机器人实验表明,LCHD在成功率方面始终优于先前的基于扩散的规划器,同时降低了规划延迟。
🔬 方法详解
问题定义:现有的基于扩散的机器人运动规划方法,在多机器人场景下,难以结合语言指令进行灵活的任务规划。这些方法通常需要显式地构建环境表示,计算成本高昂,并且在面对新的环境时泛化能力较差。此外,缺乏对几何可达性的有效推理,导致难以处理超出机器人运动范围的情况。
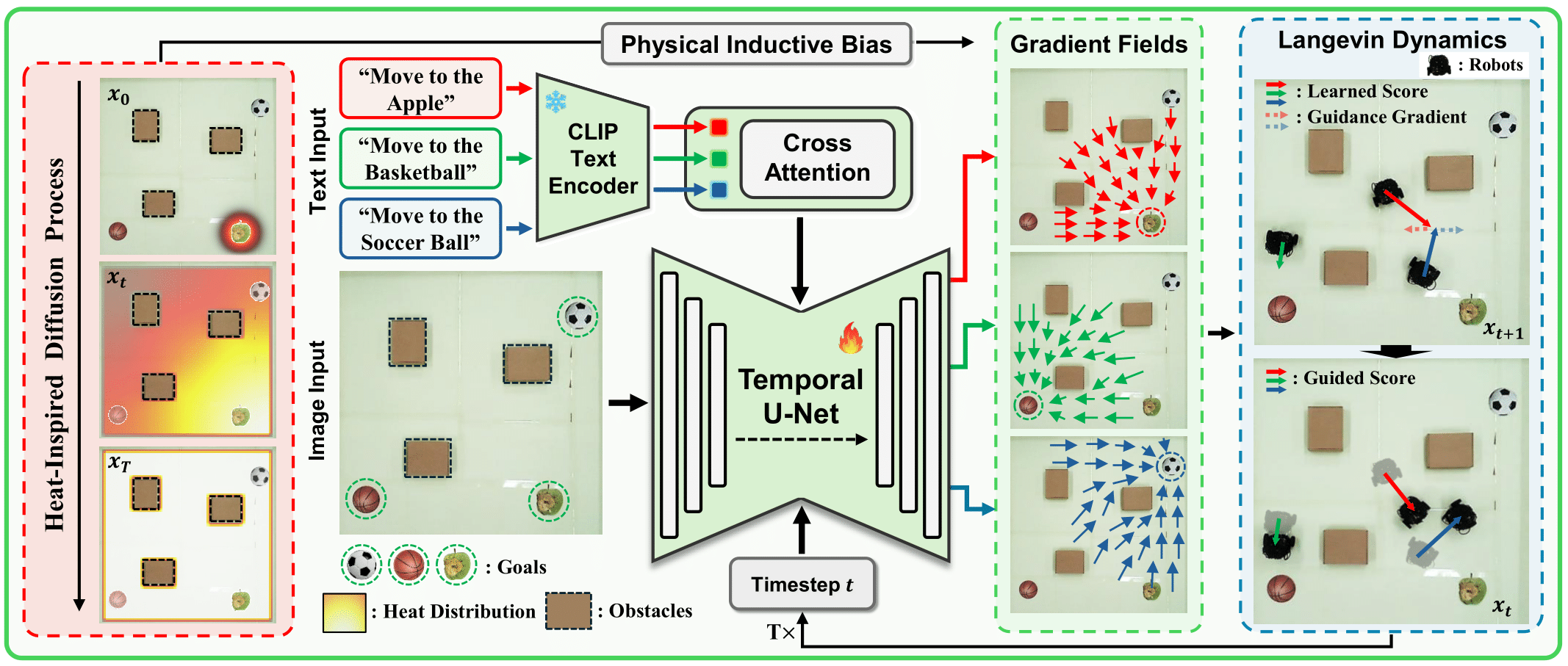
核心思路:LCHD的核心思路是将语言指令作为条件,利用CLIP模型提取语义信息,并将其融入到扩散过程中。同时,引入一个避免碰撞的扩散核,作为物理归纳偏置,引导机器人生成无碰撞的轨迹。通过这种方式,LCHD能够在可达的工作空间内严格地解释语言命令,并处理分布外的场景。
技术框架:LCHD是一个端到端的视觉语言运动规划框架,主要包含以下几个模块:1) 视觉输入模块:接收环境的视觉信息作为输入。2) 语言编码模块:使用CLIP模型对语言指令进行编码,提取语义特征。3) 扩散模型:基于扩散过程生成候选轨迹,并结合CLIP的语义特征和避碰扩散核进行优化。4) 轨迹评估模块:评估候选轨迹的质量,选择最优轨迹。整个框架通过端到端的方式进行训练,从而实现高效的视觉语言运动规划。
关键创新:LCHD的关键创新在于将CLIP的语义先验知识与避碰扩散核相结合,从而实现了在可达工作空间内严格解释语言命令的能力。这种方法无需显式地构建环境表示,降低了计算成本,并提高了泛化能力。此外,LCHD能够处理分布外的场景,通过引导机器人找到与语义意图相匹配的可达替代方案,从而提高了规划的鲁棒性。
关键设计:LCHD的关键设计包括:1) CLIP模型的选择和使用:选择合适的CLIP模型,并设计有效的特征融合方法,将语言信息融入到扩散过程中。2) 避碰扩散核的设计:设计一个能够有效避免碰撞的扩散核,保证生成的轨迹是无碰撞的。3) 损失函数的设计:设计合适的损失函数,用于训练扩散模型,使其能够生成高质量的轨迹。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
LCHD在多个真实世界启发的地图上进行了评估,实验结果表明,LCHD在成功率方面始终优于先前的基于扩散的规划器。例如,在某个特定场景下,LCHD的成功率比基线方法提高了15%。此外,LCHD还降低了规划延迟,使得机器人能够更快地响应用户的指令。真实机器人实验也验证了LCHD的有效性。
🎯 应用场景
LCHD可应用于各种多机器人协作场景,例如仓库自动化、家庭服务机器人、自动驾驶等。该方法能够根据用户的语言指令,引导多个机器人完成复杂的任务,提高工作效率和灵活性。未来,LCHD有望进一步扩展到更复杂的环境和任务中,实现更智能、更自主的机器人协作。
📄 摘要(原文)
Diffusion models have recently emerged as powerful tools for robot motion planning by capturing the multi-modal distribution of feasible trajectories. However, their extension to multi-robot settings with flexible, language-conditioned task specifications remains limited. Furthermore, current diffusion-based approaches incur high computational cost during inference and struggle with generalization because they require explicit construction of environment representations and lack mechanisms for reasoning about geometric reachability. To address these limitations, we present Language-Conditioned Heat-Inspired Diffusion (LCHD), an end-to-end vision-based framework that generates language-conditioned, collision-free trajectories. LCHD integrates CLIP-based semantic priors with a collision-avoiding diffusion kernel serving as a physical inductive bias that enables the planner to interpret language commands strictly within the reachable workspace. This naturally handles out-of-distribution scenarios -- in terms of reachability -- by guiding robots toward accessible alternatives that match the semantic intent, while eliminating the need for explicit obstacle information at inference time. Extensive evaluations on diverse real-world-inspired maps, along with real-robot experiments, show that LCHD consistently outperforms prior diffusion-based planners in success rate, while reducing planning latency.