Learning Terrain Aware Bipedal Locomotion via Reduced Dimensional Perceptual Representations
作者: Guillermo A. Castillo, Himanshu Lodha, Ayonga Hereid
分类: cs.RO
发布日期: 2025-12-15
💡 一句话要点
提出一种基于降维感知表示的地形感知双足运动学习方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 双足运动 强化学习 地形感知 降维表示 变分自编码器
📋 核心要点
- 现有端到端方法在地形感知双足运动学习中面临状态空间维度过高、学习效率低下的挑战。
- 该论文提出利用卷积变分自编码器(CNN-VAE)进行地形降维编码,结合降阶机器人动力学,优化运动决策。
- 实验表明,该方法在Agility Robotics模拟器中具有良好的鲁棒性和适应性,并进行了初步的硬件验证。
📝 摘要(中文)
本文提出了一种地形感知的双足运动分层策略,该策略集成了降维感知表示,以增强基于强化学习(RL)的高级策略,从而实现实时步态生成。与端到端方法不同,我们的框架利用卷积变分自编码器(CNN-VAE)进行潜在地形编码,并结合降阶机器人动力学,从而以紧凑的状态优化运动决策过程。我们系统地分析了潜在空间维度对学习效率和策略鲁棒性的影响。此外,我们将该方法扩展为具有历史感知能力,将最近的地形观测序列纳入潜在表示中,以提高鲁棒性。为了解决实际可行性问题,我们引入了一种蒸馏方法,可以直接从深度相机图像中学习潜在表示,并通过比较模拟和真实传感器数据来提供初步的硬件验证。我们还使用高保真Agility Robotics(AR)模拟器验证了我们的框架,该模拟器结合了真实的传感器噪声、状态估计和执行器动力学。结果证实了我们方法的鲁棒性和适应性,突显了其在硬件部署方面的潜力。
🔬 方法详解
问题定义:现有的端到端双足运动学习方法,尤其是地形感知的场景下,通常需要处理高维度的状态空间,包括机器人自身的状态以及周围环境的信息。直接在高维空间中进行强化学习会导致样本效率低下,难以训练出鲁棒的策略。此外,真实世界的传感器噪声和状态估计误差也会进一步加剧学习的难度。
核心思路:该论文的核心思路是利用降维的感知表示来简化强化学习的状态空间。具体而言,使用卷积变分自编码器(CNN-VAE)将原始地形信息(例如深度图像)编码到低维的潜在空间中。这样,强化学习策略只需要基于这个低维的潜在表示进行决策,从而降低了学习的难度,提高了样本效率。同时,通过引入历史信息,增强策略的鲁棒性。
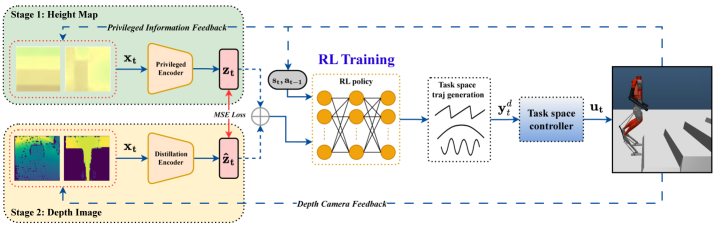
技术框架:整体框架包含以下几个主要模块:1) 感知模块:使用深度相机获取地形信息;2) 编码模块:使用CNN-VAE将地形信息编码为低维潜在向量;3) 强化学习模块:使用强化学习算法(例如PPO)训练一个策略,该策略以低维潜在向量和机器人状态作为输入,输出控制指令;4) 运动控制模块:将控制指令转化为机器人关节的实际运动。此外,还包含一个蒸馏模块,用于将学习到的潜在表示迁移到真实世界的深度相机数据上。
关键创新:该论文的关键创新在于将降维感知表示与强化学习相结合,用于地形感知的双足运动控制。与传统的端到端方法相比,该方法能够显著降低状态空间的维度,提高学习效率和策略的鲁棒性。此外,通过引入历史信息和蒸馏方法,进一步增强了策略的实用性。
关键设计:CNN-VAE的网络结构需要根据具体的地形信息进行设计,例如输入图像的大小和通道数。潜在空间的维度需要根据实验进行调整,以平衡学习效率和策略的表达能力。强化学习算法可以选择PPO或其他合适的算法,奖励函数需要根据具体的任务进行设计,例如鼓励机器人前进、保持平衡等。蒸馏模块的目标是最小化模拟和真实数据之间的潜在表示差异,可以使用KL散度或其他合适的损失函数。
🖼️ 关键图片

📊 实验亮点
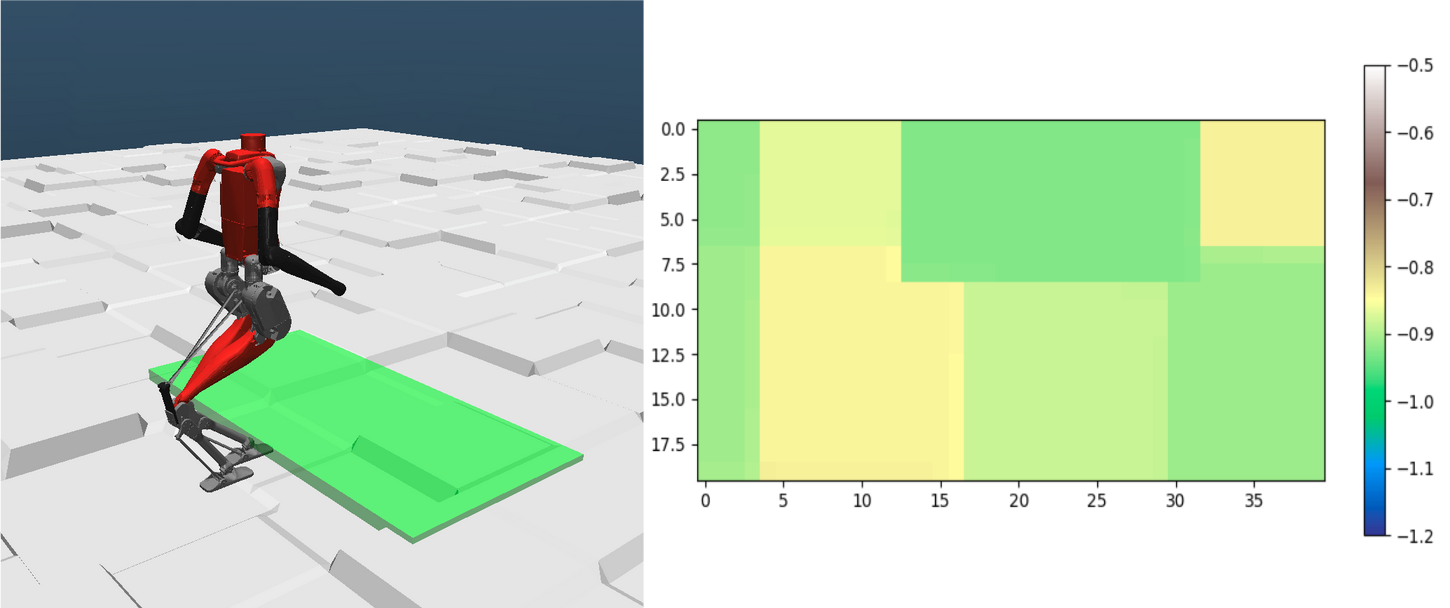
论文在高保真Agility Robotics模拟器中进行了验证,结果表明该方法能够有效地学习地形感知的运动策略。通过对比不同潜在空间维度和是否引入历史信息,验证了该方法的有效性和鲁棒性。初步的硬件验证表明,该方法具有实际部署的潜力。
🎯 应用场景
该研究成果可应用于复杂地形下的双足机器人导航、搜索救援、物流运输等领域。通过降低对环境感知的计算需求,有望提升机器人在资源受限环境下的自主作业能力。未来,该技术可进一步扩展到其他类型的机器人和运动模式,例如四足机器人、人形机器人等。
📄 摘要(原文)
This work introduces a hierarchical strategy for terrain-aware bipedal locomotion that integrates reduced-dimensional perceptual representations to enhance reinforcement learning (RL)-based high-level (HL) policies for real-time gait generation. Unlike end-to-end approaches, our framework leverages latent terrain encodings via a Convolutional Variational Autoencoder (CNN-VAE) alongside reduced-order robot dynamics, optimizing the locomotion decision process with a compact state. We systematically analyze the impact of latent space dimensionality on learning efficiency and policy robustness. Additionally, we extend our method to be history-aware, incorporating sequences of recent terrain observations into the latent representation to improve robustness. To address real-world feasibility, we introduce a distillation method to learn the latent representation directly from depth camera images and provide preliminary hardware validation by comparing simulated and real sensor data. We further validate our framework using the high-fidelity Agility Robotics (AR) simulator, incorporating realistic sensor noise, state estimation, and actuator dynamics. The results confirm the robustness and adaptability of our method, underscoring its potential for hardware deployment.