Tackling Snow-Induced Challenges: Safe Autonomous Lane-Keeping with Robust Reinforcement Learning
作者: Amin Jalal Aghdasian, Farzaneh Abdollahi, Ali Kamali Iglie
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-12-15
💡 一句话要点
提出两种基于鲁棒强化学习的车道保持算法,解决雪地自动驾驶难题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 自动驾驶 车道保持 雪地环境 动作鲁棒性 注意力机制 循环神经网络
📋 核心要点
- 现有车道保持系统在雪地等复杂环境下,由于路面滑移和感知不确定性,难以保证自动驾驶车辆的安全。
- 论文提出动作鲁棒的深度强化学习算法,通过学习在不确定性下的最优策略,提升车道保持系统的稳定性和安全性。
- 实验表明,所提出的AR-CADPG算法在雪地场景下具有更高的路径跟踪精度和鲁棒性,验证了算法的有效性。
📝 摘要(中文)
本文提出了两种新的车道保持系统(LKS)算法,用于在雪地条件下运行的自动驾驶车辆(AV)。这些算法利用深度强化学习(DRL)来处理不确定性和滑移。它们包括动作鲁棒循环深度确定性策略梯度(AR-RDPG)和端到端动作鲁棒卷积神经网络注意力确定性策略梯度(AR-CADPG),这两种动作鲁棒的决策方法。在AR-RDPG方法中,在感知层内,首先使用多尺度神经网络对相机图像进行去噪。然后,通过预训练的深度卷积神经网络(DCNN)提取中心线系数。这些系数与驾驶特性连接,作为控制层的输入。AR-CADPG方法提出了一种端到端的方法,其中卷积神经网络(CNN)和注意力机制被集成到DRL框架中。两种方法首先在CARLA模拟器中进行训练,并在各种雪地场景下进行验证。在基于Jetson Nano的自动驾驶车辆上的真实实验证实了学习策略的可行性和稳定性。在两种模型中,AR-CADPG方法表现出卓越的路径跟踪精度和鲁棒性,突出了在自动驾驶车辆中结合时间记忆、对抗弹性和注意力机制的有效性。
🔬 方法详解
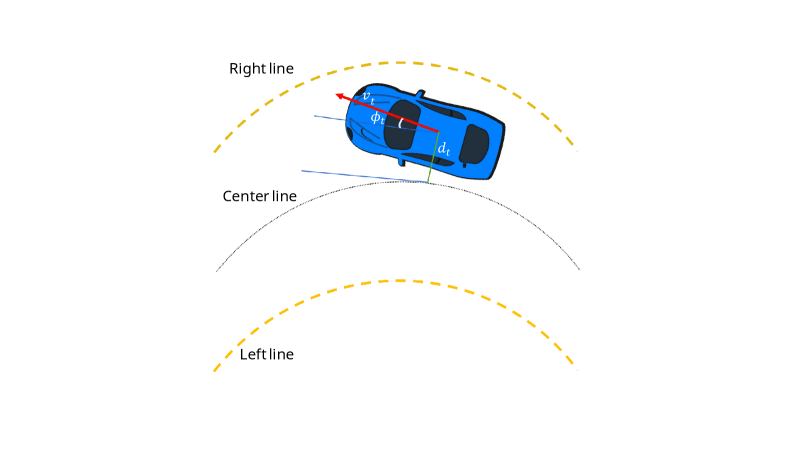
问题定义:论文旨在解决雪地环境下自动驾驶车辆车道保持系统面临的挑战。现有方法难以有效应对雪地带来的路面滑移、感知噪声等问题,导致车辆行驶不稳定甚至发生危险。因此,需要一种能够在不确定性条件下做出鲁棒决策的车道保持系统。
核心思路:论文的核心思路是利用深度强化学习(DRL)学习在雪地环境下的最优车道保持策略。通过引入动作鲁棒性,使智能体能够适应环境的不确定性,从而提高系统的稳定性和安全性。同时,结合注意力机制和循环神经网络,增强模型对时序信息的处理能力和对关键特征的关注。
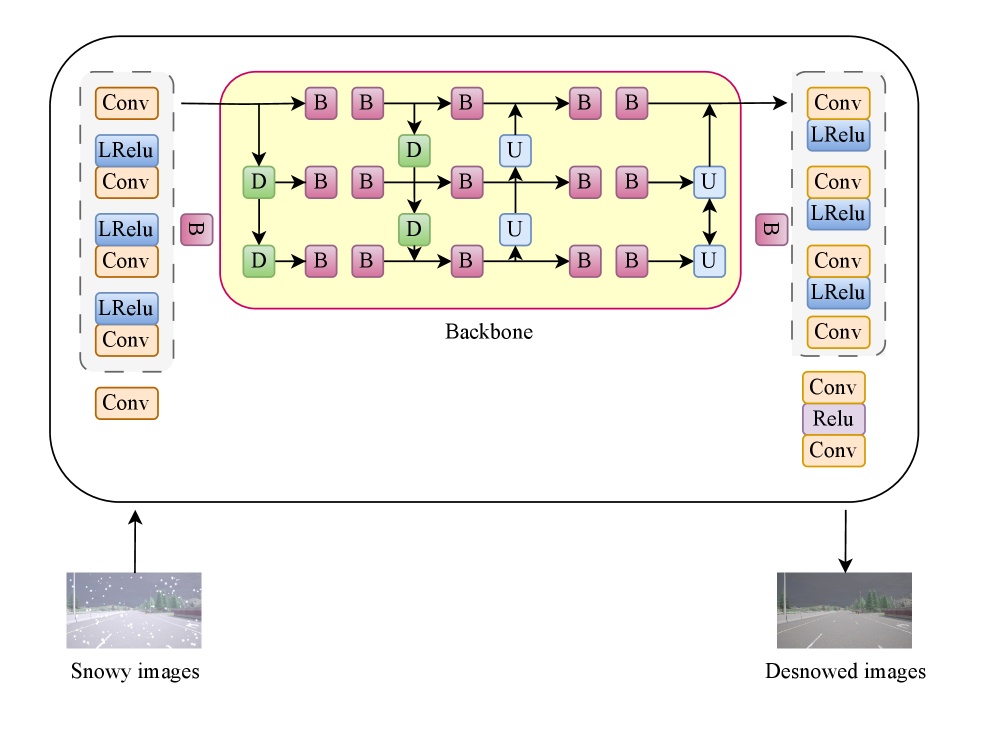
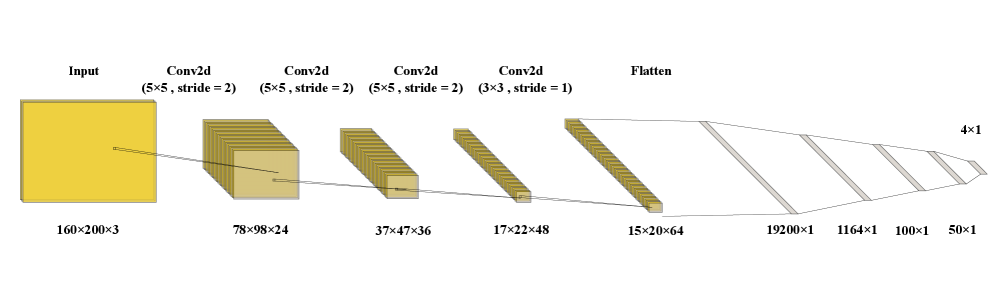
技术框架:论文提出了两种算法:AR-RDPG和AR-CADPG。AR-RDPG首先使用多尺度神经网络进行图像去噪,然后通过预训练的DCNN提取中心线系数,最后将这些系数与驾驶特性结合作为控制层的输入。AR-CADPG则采用端到端的结构,将CNN和注意力机制集成到DRL框架中,直接从图像输入学习控制策略。
关键创新:论文的关键创新在于将动作鲁棒性引入到深度强化学习中,并将其应用于自动驾驶车道保持任务。此外,AR-CADPG算法的端到端结构和注意力机制的引入,使得模型能够更好地处理图像信息和时序信息,从而提高了系统的性能。
关键设计:AR-RDPG的关键设计包括多尺度去噪网络和预训练的中心线提取DCNN。AR-CADPG的关键设计包括CNN的结构、注意力机制的类型和位置、以及强化学习的奖励函数设计。具体参数设置和损失函数细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AR-CADPG算法在雪地场景下表现出卓越的路径跟踪精度和鲁棒性。与AR-RDPG相比,AR-CADPG能够更好地适应雪地环境带来的不确定性,实现更稳定的车道保持。具体的性能提升数据未在摘要中给出,属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要在复杂环境(如雪地、雨天、雾天等)下运行的自动驾驶车辆,提高其安全性和可靠性。此外,该方法也可推广到其他机器人控制任务中,例如无人机、水下机器人等,具有广泛的应用前景。
📄 摘要(原文)
This paper proposes two new algorithms for the lane keeping system (LKS) in autonomous vehicles (AVs) operating under snowy road conditions. These algorithms use deep reinforcement learning (DRL) to handle uncertainties and slippage. They include Action-Robust Recurrent Deep Deterministic Policy Gradient (AR-RDPG) and end-to-end Action-Robust convolutional neural network Attention Deterministic Policy Gradient (AR-CADPG), two action-robust approaches for decision-making. In the AR-RDPG method, within the perception layer, camera images are first denoised using multi-scale neural networks. Then, the centerline coefficients are extracted by a pre-trained deep convolutional neural network (DCNN). These coefficients, concatenated with the driving characteristics, are used as input to the control layer. The AR-CADPG method presents an end-to-end approach in which a convolutional neural network (CNN) and an attention mechanism are integrated within a DRL framework. Both methods are first trained in the CARLA simulator and validated under various snowy scenarios. Real-world experiments on a Jetson Nano-based autonomous vehicle confirm the feasibility and stability of the learned policies. Among the two models, the AR-CADPG approach demonstrates superior path-tracking accuracy and robustness, highlighting the effectiveness of combining temporal memory, adversarial resilience, and attention mechanisms in AVs.