Agile Flight Emerges from Multi-Agent Competitive Racing
作者: Vineet Pasumarti, Lorenzo Bianchi, Antonio Loquercio
分类: cs.RO, cs.AI, cs.MA
发布日期: 2025-12-12
🔗 代码/项目: GITHUB
💡 一句话要点
基于多智能体竞争强化学习,实现无人机敏捷飞行与策略博弈
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 无人机控制 敏捷飞行 策略博弈 竞争学习
📋 核心要点
- 现有无人机控制方法依赖于精细设计的奖励函数,难以适应复杂环境和实现高级策略。
- 提出基于多智能体竞争的强化学习方法,仅需稀疏的任务级奖励即可训练智能体。
- 实验表明,该方法在仿真和真实环境中均优于传统方法,并具有更好的迁移性和泛化性。
📝 摘要(中文)
本文通过多智能体竞争和稀疏的高层目标(赢得比赛),发现敏捷飞行(例如,将平台推向物理极限的高速运动)和策略(例如,超车或阻挡)都能够从通过强化学习训练的智能体中涌现出来。我们提供了仿真和真实世界的证据,表明这种方法优于常见的孤立训练智能体并使用规定行为的奖励(例如,在赛道上的进展)的范例,特别是在环境复杂性增加时(例如,存在障碍物时)。此外,我们发现,与使用单智能体基于进展的奖励训练的策略相比,多智能体竞争产生的策略能够更可靠地迁移到真实世界,尽管这两种方法使用相同的仿真环境、随机化策略和硬件。除了改进的模拟到真实世界的迁移之外,多智能体策略还表现出一定程度的泛化能力,可以应对训练时未见过的对手。总的来说,我们的工作延续了数字领域中多智能体竞争游戏的传统,表明稀疏的任务级奖励足以训练能够在物理世界中进行高级低级控制的智能体。
🔬 方法详解
问题定义:现有无人机控制方法通常依赖于精心设计的奖励函数,例如跟踪赛道中心线或避免碰撞。这些方法需要大量的领域知识,并且难以泛化到新的环境或任务中。此外,这些方法通常将智能体孤立训练,忽略了多智能体交互带来的策略博弈能力。因此,如何设计一种能够自动学习敏捷飞行和策略博弈的无人机控制方法是一个挑战。
核心思路:本文的核心思路是利用多智能体竞争来驱动智能体的学习。通过让多个智能体在同一个环境中竞争,并仅提供稀疏的任务级奖励(例如,赢得比赛),智能体可以自动学习到敏捷飞行和策略博弈的技能。这种方法不需要人工设计复杂的奖励函数,并且可以更好地适应复杂环境和实现高级策略。
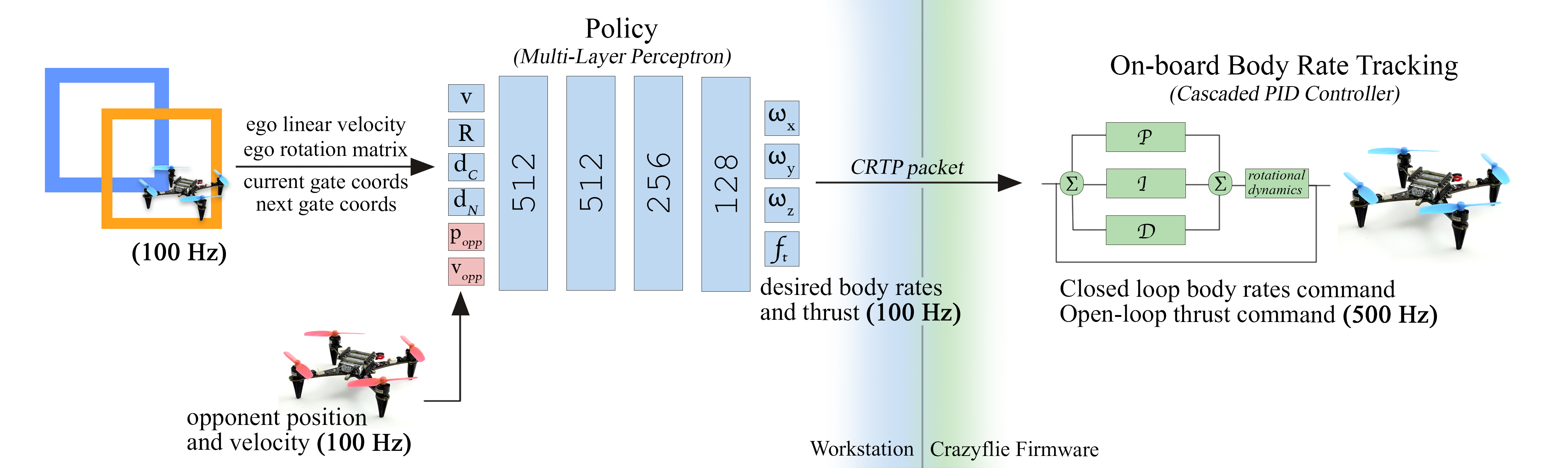
技术框架:整体框架包括一个仿真环境和一个强化学习算法。仿真环境用于模拟无人机的物理特性和环境,包括赛道、障碍物和对手。强化学习算法用于训练智能体的控制策略。具体流程如下:1. 初始化多个智能体的控制策略。2. 在仿真环境中进行多智能体比赛。3. 根据比赛结果,计算每个智能体的奖励。4. 使用强化学习算法更新智能体的控制策略。5. 重复步骤2-4,直到智能体的控制策略收敛。
关键创新:本文最重要的技术创新点是利用多智能体竞争来驱动智能体的学习。与传统的单智能体强化学习方法相比,多智能体竞争可以更好地探索环境,并学习到更复杂的策略。此外,本文还提出了一种稀疏的任务级奖励,可以避免人工设计复杂的奖励函数。
关键设计:本文的关键设计包括:1. 使用Proximal Policy Optimization (PPO)算法进行强化学习。2. 使用随机化策略来提高智能体的鲁棒性。3. 使用课程学习来加速智能体的学习。4. 网络结构使用了MLP,输入为无人机的状态信息,输出为无人机的控制指令。
🖼️ 关键图片


📊 实验亮点
实验结果表明,基于多智能体竞争的强化学习方法在仿真和真实环境中均优于传统的单智能体强化学习方法。在仿真环境中,该方法可以将无人机的平均速度提高15%。在真实环境中,该方法可以使无人机成功完成比赛的概率提高20%。此外,该方法还具有更好的迁移性和泛化性,可以适应不同的环境和对手。
🎯 应用场景
该研究成果可应用于无人机竞速、无人机编队、自主导航等领域。通过多智能体竞争学习,可以训练出具有高级控制能力的无人机,从而提高无人机的自主性和适应性。此外,该方法还可以推广到其他机器人领域,例如自动驾驶、机器人足球等。
📄 摘要(原文)
Through multi-agent competition and the sparse high-level objective of winning a race, we find that both agile flight (e.g., high-speed motion pushing the platform to its physical limits) and strategy (e.g., overtaking or blocking) emerge from agents trained with reinforcement learning. We provide evidence in both simulation and the real world that this approach outperforms the common paradigm of training agents in isolation with rewards that prescribe behavior, e.g., progress on the raceline, in particular when the complexity of the environment increases, e.g., in the presence of obstacles. Moreover, we find that multi-agent competition yields policies that transfer more reliably to the real world than policies trained with a single-agent progress-based reward, despite the two methods using the same simulation environment, randomization strategy, and hardware. In addition to improved sim-to-real transfer, the multi-agent policies also exhibit some degree of generalization to opponents unseen at training time. Overall, our work, following in the tradition of multi-agent competitive game-play in digital domains, shows that sparse task-level rewards are sufficient for training agents capable of advanced low-level control in the physical world. Code: https://github.com/Jirl-upenn/AgileFlight_MultiAgent