BLURR: A Boosted Low-Resource Inference for Vision-Language-Action Models
作者: Xiaoyu Ma, Zhengqing Yuan, Zheyuan Zhang, Kaiwen Shi, Lichao Sun, Yanfang Ye
分类: cs.RO
发布日期: 2025-12-12
备注: 10 pages, 3 figures. Code and integration scripts will be released at this http URL: https://github.com/JijiKing-Sam/BLURR-A-Boosted-Low-Resource-Inference-for-Vision-Language-Action-Model
💡 一句话要点
BLURR:一种加速VLA模型低资源推理的轻量级封装器
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 低资源推理 模型加速 机器人控制 混合精度
📋 核心要点
- 现有VLA模型推理计算量大,难以在算力受限的设备上部署,限制了其应用场景。
- BLURR通过指令前缀缓存、混合精度和单步展开等技术,在不重训练模型的前提下加速推理。
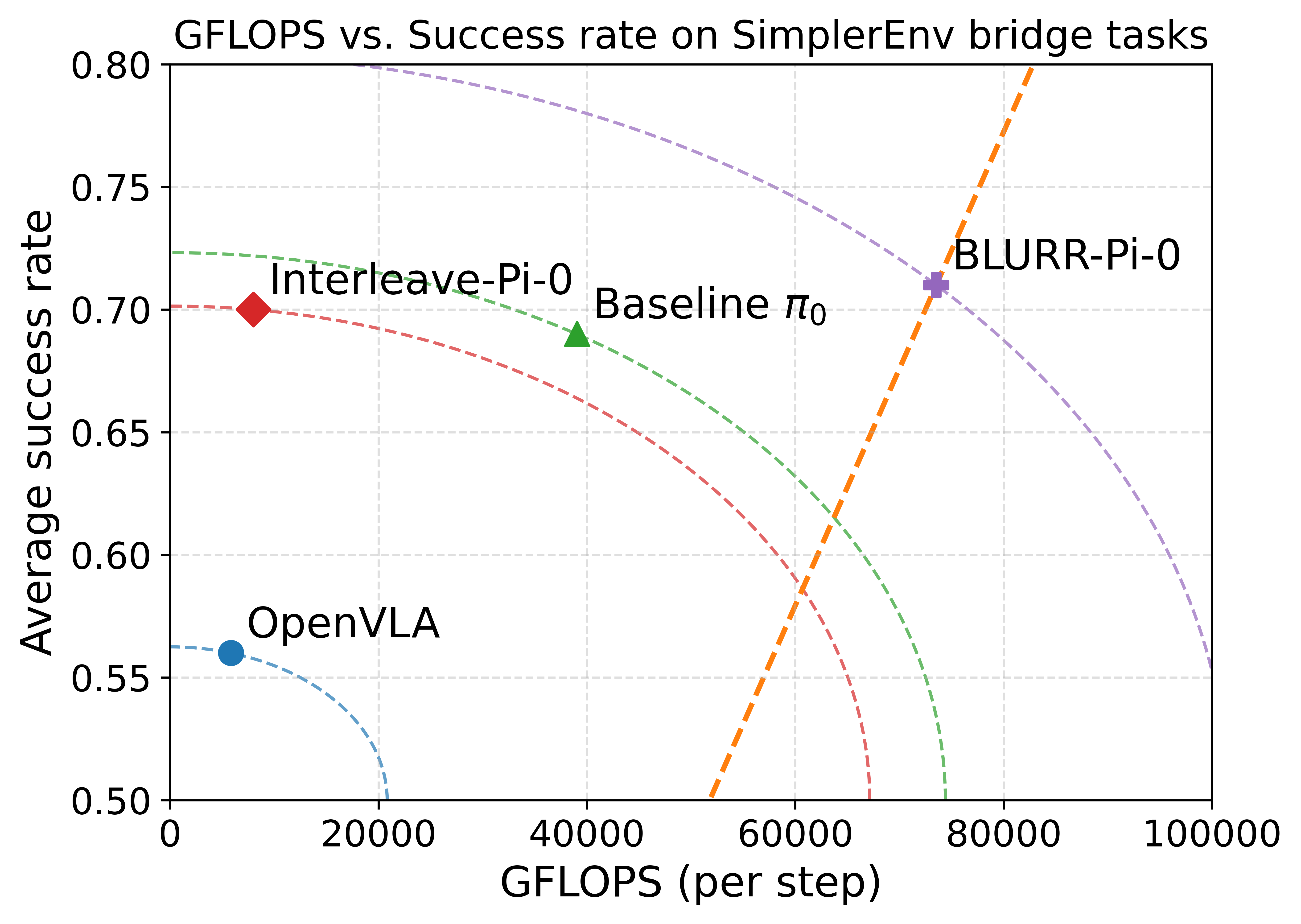
- 实验表明,BLURR在保持任务成功率的同时,显著降低了计算量和延迟,并支持实时Web演示。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在零样本操作方面表现出色,但其推理过程通常过于繁重,难以在消费级GPU上实现响应式Web演示或高频机器人控制。我们提出了BLURR,一个轻量级的推理封装器,可以插入到现有的VLA控制器中,而无需重新训练或更改模型检查点。在pi-zero VLA控制器上实例化后,BLURR保持了原始的观察接口,并通过结合指令前缀键值缓存、混合精度执行和减少每步计算的单步展开策略来加速控制。在基于SimplerEnv的评估中,BLURR保持了与原始控制器相当的任务成功率,同时显著降低了有效FLOPs和实际延迟。我们还构建了一个交互式Web演示,允许用户在观看操作过程时实时切换控制器和切换推理选项。这突出了BLURR作为在紧张的计算预算下部署现代VLA策略的一种实用方法。
🔬 方法详解
问题定义:VLA模型虽然在机器人操作等任务上展现了强大的零样本泛化能力,但其庞大的计算需求使得它们难以在资源受限的设备上部署,例如低功耗机器人或实时Web应用。现有方法通常需要大量的计算资源,导致延迟高,无法满足实时性要求。
核心思路:BLURR的核心思路是在不改变VLA模型本身的前提下,通过优化推理过程来降低计算成本。它利用了VLA模型在处理序列任务时的冗余性,并结合多种优化技术,以减少每一步的计算量和内存占用。
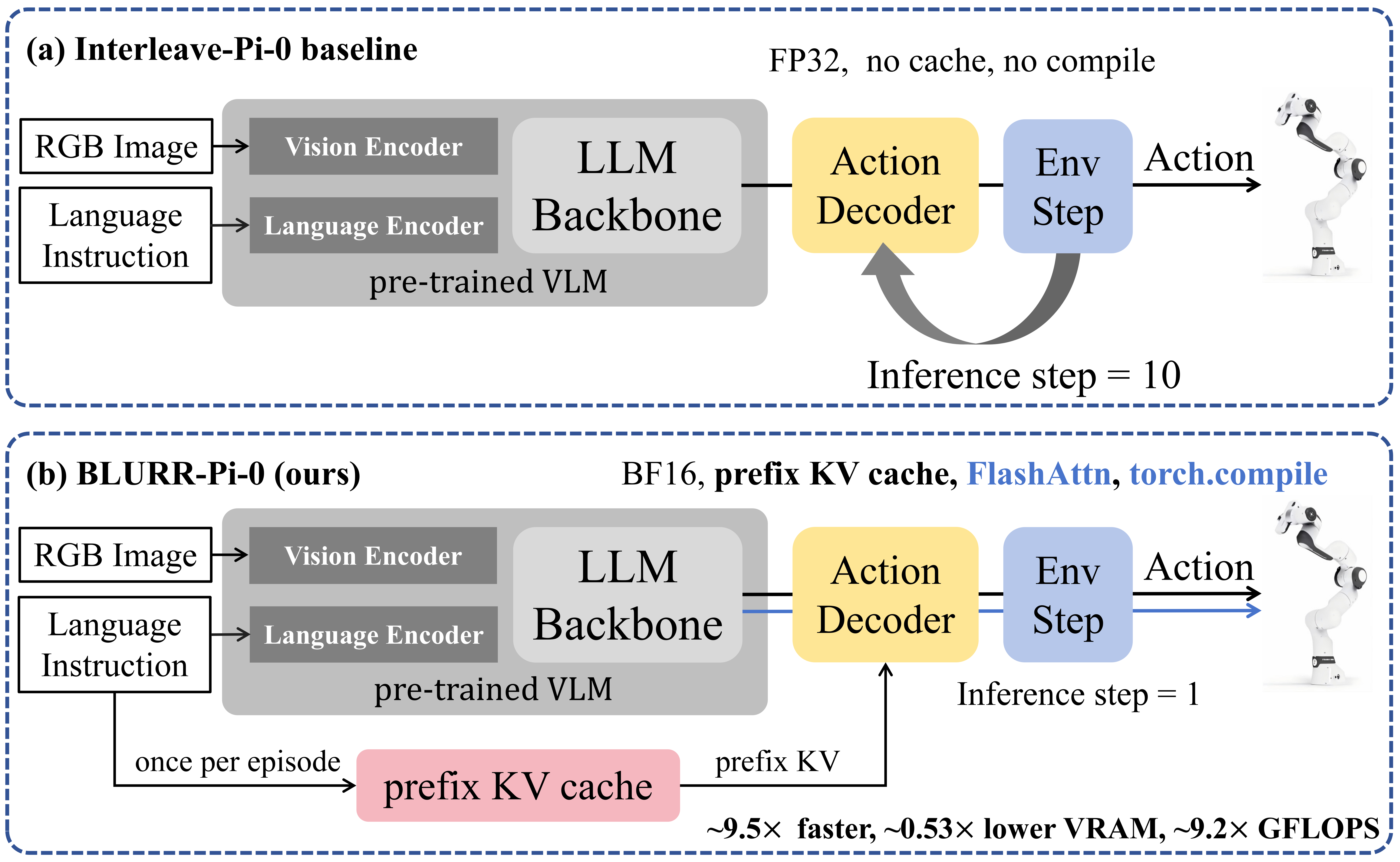
技术框架:BLURR作为一个轻量级的推理封装器,可以无缝集成到现有的VLA控制系统中。其主要包含三个核心模块:1) 指令前缀键值缓存:缓存指令前缀的计算结果,避免重复计算;2) 混合精度执行:使用半精度浮点数进行计算,降低内存占用和计算量;3) 单步展开策略:减少每一步的计算依赖,降低延迟。整体流程是,接收环境观测和用户指令,利用缓存加速计算,进行混合精度推理,输出动作指令。
关键创新:BLURR的关键创新在于其轻量级和即插即用的特性。它不需要重新训练VLA模型,而是通过优化推理过程来实现加速。指令前缀键值缓存充分利用了指令的重复性,混合精度执行降低了计算复杂度,单步展开策略减少了计算依赖。这些优化策略的组合使得BLURR能够在资源受限的环境下高效地运行VLA模型。
关键设计:指令前缀键值缓存的设计需要考虑缓存大小和命中率之间的平衡。混合精度执行需要仔细选择哪些层使用半精度,以避免精度损失。单步展开策略需要调整展开的步数,以在计算量和性能之间取得平衡。具体参数设置取决于VLA模型的结构和任务的特点。
🖼️ 关键图片

📊 实验亮点
实验结果表明,BLURR在SimplerEnv环境中,能够在保持与原始控制器相当的任务成功率的同时,显著降低有效FLOPs和实际延迟。具体而言,BLURR在pi-zero VLA控制器上实现了显著的加速,使得原本难以实时运行的VLA模型能够在Web浏览器中进行交互式演示。用户可以实时切换控制器和推理选项,体验不同配置下的性能表现。
🎯 应用场景
BLURR具有广泛的应用前景,尤其是在需要低延迟和低功耗的机器人控制、移动设备上的AI应用以及实时Web演示等领域。它可以帮助开发者在资源受限的平台上部署复杂的VLA模型,从而实现更智能、更高效的应用。未来,BLURR可以进一步扩展到其他类型的AI模型,并与其他优化技术相结合,以实现更强大的性能。
📄 摘要(原文)
Vision-language-action (VLA) models enable impressive zero shot manipulation, but their inference stacks are often too heavy for responsive web demos or high frequency robot control on commodity GPUs. We present BLURR, a lightweight inference wrapper that can be plugged into existing VLA controllers without retraining or changing model checkpoints. Instantiated on the pi-zero VLA controller, BLURR keeps the original observation interfaces and accelerates control by combining an instruction prefix key value cache, mixed precision execution, and a single step rollout schedule that reduces per step computation. In our SimplerEnv based evaluation, BLURR maintains task success rates comparable to the original controller while significantly lowering effective FLOPs and wall clock latency. We also build an interactive web demo that allows users to switch between controllers and toggle inference options in real time while watching manipulation episodes. This highlights BLURR as a practical approach for deploying modern VLA policies under tight compute budgets.