UniBYD: A Unified Framework for Learning Robotic Manipulation Across Embodiments Beyond Imitation of Human Demonstrations
作者: Tingyu Yuan, Biaoliang Guan, Wen Ye, Ziyan Tian, Yi Yang, Weijie Zhou, Yan Huang, Peng Wang, Chaoyang Zhao, Jinqiao Wang
分类: cs.RO
发布日期: 2025-12-12
🔗 代码/项目: GITHUB
💡 一句话要点
UniBYD:统一框架,超越模仿人类演示,学习跨形态机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 机器人操作 强化学习 形态差异 统一形态表示 模仿学习 具身智能 动态PPO
📋 核心要点
- 现有方法难以弥合人手与机器人手之间的形态差异,导致机器人操作学习受限于模仿人类,性能提升有限。
- UniBYD 提出统一的形态表示(UMR),并结合动态强化学习算法,使机器人能够探索适应自身形态的操作策略。
- UniBYD 在 UniManip 基准测试中,相比现有技术,成功率提升了 67.90%,展示了其优越的性能。
📝 摘要(中文)
在具身智能领域,机器人和人类手之间的形态差异给从人类演示中学习带来了重大挑战。尽管一些研究试图通过强化学习来弥合这一差距,但它们仍然局限于重现人类操作,导致任务性能受限。本文提出了UniBYD,一个统一的框架,它使用动态强化学习算法来发现与机器人物理特性对齐的操作策略。为了实现跨不同机器人手部形态的一致建模,UniBYD 结合了统一的形态表示(UMR)。基于 UMR,我们设计了一个具有退火奖励计划的动态 PPO,使强化学习能够从模仿人类演示过渡到探索更适合不同机器人形态的策略,从而超越了对人类手的简单模仿。为了解决早期训练阶段学习人类先验知识时频繁出现的失败问题,我们设计了一个基于混合马尔可夫的影子引擎,使强化学习能够以细粒度的方式模仿人类操作。为了全面评估 UniBYD,我们提出了 UniManip,这是第一个包含跨多种手部形态的机器人操作任务的基准。实验表明,成功率比当前最先进水平提高了 67.90%。论文被接受后,我们将在 https://github.com/zhanheng-creator/UniBYD 上发布我们的代码和基准。
🔬 方法详解
问题定义:现有机器人操作学习方法主要依赖于模仿学习,直接复制人类的动作。然而,由于机器人手与人类手在形态和运动学上的差异,简单模仿往往无法取得最佳性能。现有基于强化学习的方法虽然可以进行优化,但仍然难以摆脱人类演示的束缚,无法充分利用机器人自身的优势。因此,如何让机器人超越模仿,学习到适应自身形态的操作策略,是一个亟待解决的问题。
核心思路:UniBYD 的核心思路是利用统一的形态表示(UMR)来建模不同机器人手的形态,并结合动态强化学习算法,使机器人能够探索适应自身形态的操作策略。通过 UMR,可以将不同形态的机器人手映射到统一的特征空间,从而实现跨形态的知识迁移和泛化。动态强化学习算法则允许机器人从模仿人类演示开始,逐步探索更优的策略,最终超越模仿,实现更好的操作性能。
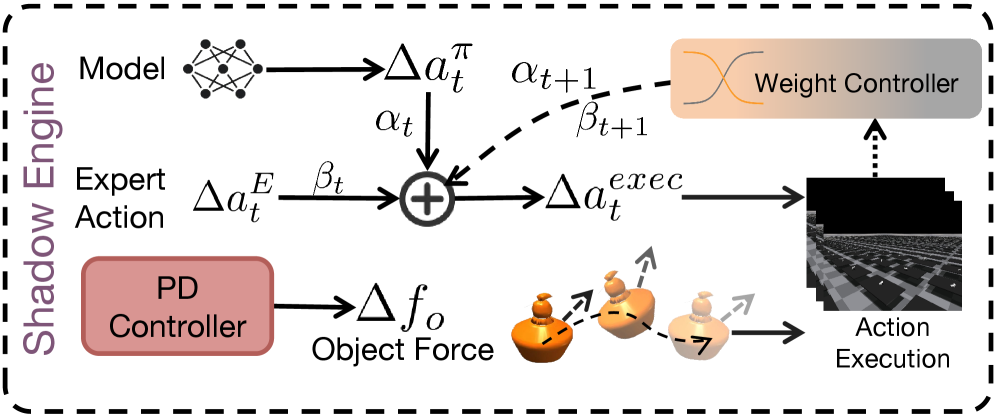
技术框架:UniBYD 的整体框架包含三个主要模块:统一形态表示(UMR)、动态 PPO 强化学习算法和混合马尔可夫影子引擎。首先,UMR 将不同机器人手的形态信息编码成统一的特征向量。然后,动态 PPO 算法利用这些特征向量来学习操作策略,并通过退火奖励计划,逐步从模仿人类演示过渡到探索更优策略。最后,混合马尔可夫影子引擎用于在早期训练阶段辅助强化学习,通过细粒度的模仿学习,避免因人类先验知识的偏差而导致的训练失败。
关键创新:UniBYD 的关键创新在于以下几点:1) 提出了统一的形态表示(UMR),实现了跨不同机器人手形态的知识迁移和泛化。2) 设计了动态 PPO 强化学习算法,通过退火奖励计划,使机器人能够从模仿人类演示过渡到探索更优策略。3) 提出了混合马尔可夫影子引擎,用于在早期训练阶段辅助强化学习,避免了因人类先验知识的偏差而导致的训练失败。
关键设计:UMR 的具体实现方式未知,但可以推测其目标是提取机器人手的关键形态参数,例如手指长度、关节角度范围等,并将这些参数编码成统一的特征向量。动态 PPO 算法的关键在于退火奖励计划,该计划通过逐渐降低模仿人类演示的奖励权重,并增加探索自身优势的奖励权重,引导机器人逐步摆脱模仿的束缚。混合马尔可夫影子引擎的具体实现方式也未知,但可以推测其利用马尔可夫模型来建模人类操作的细粒度动作序列,并利用这些序列来指导强化学习的探索。
🖼️ 关键图片


📊 实验亮点
UniBYD 在 UniManip 基准测试中取得了显著的性能提升,成功率比当前最先进水平提高了 67.90%。这一结果表明,UniBYD 能够有效地学习适应机器人自身形态的操作策略,并超越了对人类演示的简单模仿。UniManip 基准测试涵盖了多种机器人手部形态和操作任务,进一步验证了 UniBYD 的泛化能力和鲁棒性。
🎯 应用场景
UniBYD 的潜在应用领域包括工业自动化、医疗机器人、家庭服务机器人等。该研究可以帮助机器人更好地适应不同的操作环境和任务需求,提高操作的灵活性和效率。通过学习适应自身形态的操作策略,机器人可以完成更加复杂和精细的操作任务,例如装配、抓取、手术等。未来,UniBYD 有望推动机器人操作技术的进步,使机器人能够更好地服务于人类。
📄 摘要(原文)
In embodied intelligence, the embodiment gap between robotic and human hands brings significant challenges for learning from human demonstrations. Although some studies have attempted to bridge this gap using reinforcement learning, they remain confined to merely reproducing human manipulation, resulting in limited task performance. In this paper, we propose UniBYD, a unified framework that uses a dynamic reinforcement learning algorithm to discover manipulation policies aligned with the robot's physical characteristics. To enable consistent modeling across diverse robotic hand morphologies, UniBYD incorporates a unified morphological representation (UMR). Building on UMR, we design a dynamic PPO with an annealed reward schedule, enabling reinforcement learning to transition from imitation of human demonstrations to explore policies adapted to diverse robotic morphologies better, thereby going beyond mere imitation of human hands. To address the frequent failures of learning human priors in the early training stage, we design a hybrid Markov-based shadow engine that enables reinforcement learning to imitate human manipulations in a fine-grained manner. To evaluate UniBYD comprehensively, we propose UniManip, the first benchmark encompassing robotic manipulation tasks spanning multiple hand morphologies. Experiments demonstrate a 67.90% improvement in success rate over the current state-of-the-art. Upon acceptance of the paper, we will release our code and benchmark at https://github.com/zhanheng-creator/UniBYD.