An Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
作者: Chao Xu, Suyu Zhang, Yang Liu, Baigui Sun, Weihong Chen, Bo Xu, Qi Liu, Juncheng Wang, Shujun Wang, Shan Luo, Jan Peters, Athanasios V. Vasilakos, Stefanos Zafeiriou, Jiankang Deng
分类: cs.RO
发布日期: 2025-12-12 (更新: 2025-12-19)
备注: project page: https://suyuz1.github.io/VLA-Survey-Anatomy/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
对视觉-语言-动作模型进行解剖,剖析模块、里程碑与挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人 具身智能 综述 深度学习
📋 核心要点
- VLA模型发展迅速,但缺乏系统性的梳理,研究人员难以快速掌握领域全貌和发展脉络。
- 本文从模块、里程碑和挑战三个维度,系统性地分析了VLA模型,为研究人员提供清晰的VLA领域指南。
- 文章深入探讨了VLA模型在表示、执行、泛化、安全以及数据集和评估五个方面的挑战,并展望了未来研究方向。
📝 摘要(中文)
视觉-语言-动作(VLA)模型正在推动机器人领域的革命,使机器能够理解指令并与物理世界交互。这个领域涌现出大量的新模型和数据集,这既令人兴奋又充满挑战。本文提供了一个清晰且结构化的VLA领域指南。文章按照研究人员的自然学习路径进行设计:从任何VLA模型的基本模块开始,追溯关键里程碑的历史,然后深入研究定义最新研究前沿的核心挑战。主要贡献是对以下五个最大挑战的详细分解:(1)表示,(2)执行,(3)泛化,(4)安全,以及(5)数据集和评估。这种结构反映了通用智能体的开发路线图:建立基本的感知-动作循环,跨不同的具身和环境扩展能力,最后确保可信的部署——所有这些都由必要的数据基础设施支持。针对每个挑战,回顾了现有方法并强调了未来的机会。本文定位为新手的基本指南和经验丰富的研究人员的战略路线图,旨在加速学习并激发具身智能的新想法。该调查的实时版本将在项目页面上持续更新。
🔬 方法详解
问题定义:视觉-语言-动作(VLA)模型旨在使机器人能够理解人类指令并与物理世界交互。然而,该领域发展迅速,模型和数据集不断涌现,研究人员难以快速掌握领域全貌,并且在表示、执行、泛化、安全和数据集等方面面临诸多挑战。现有方法在这些方面仍存在不足,例如,如何有效地表示多模态信息,如何保证执行的准确性和安全性,如何提高模型的泛化能力等。
核心思路:本文的核心思路是对VLA模型进行系统性的解剖,从模块、里程碑和挑战三个维度进行分析。通过梳理VLA模型的发展历程,总结现有方法的优缺点,并指出未来研究方向,为研究人员提供一个清晰的VLA领域指南。文章重点关注VLA模型在表示、执行、泛化、安全以及数据集和评估五个方面的挑战,并对每个挑战进行了深入分析。
技术框架:本文的框架主要包括三个部分:模块、里程碑和挑战。首先,文章介绍了VLA模型的基本模块,包括视觉感知模块、语言理解模块和动作执行模块。然后,文章回顾了VLA模型的发展历程,总结了关键里程碑事件。最后,文章深入探讨了VLA模型在表示、执行、泛化、安全以及数据集和评估五个方面的挑战。对于每个挑战,文章都回顾了现有方法,并指出了未来研究方向。
关键创新:本文的创新之处在于对VLA模型进行了系统性的解剖,从模块、里程碑和挑战三个维度进行分析,为研究人员提供了一个清晰的VLA领域指南。此外,文章还深入探讨了VLA模型在表示、执行、泛化、安全以及数据集和评估五个方面的挑战,并对每个挑战进行了深入分析,为未来的研究提供了有价值的参考。
关键设计:本文没有提出具体的模型或算法,而是一个综述性的工作,因此没有具体的参数设置、损失函数或网络结构等技术细节。文章主要关注对VLA模型的系统性分析和对未来研究方向的展望。
🖼️ 关键图片
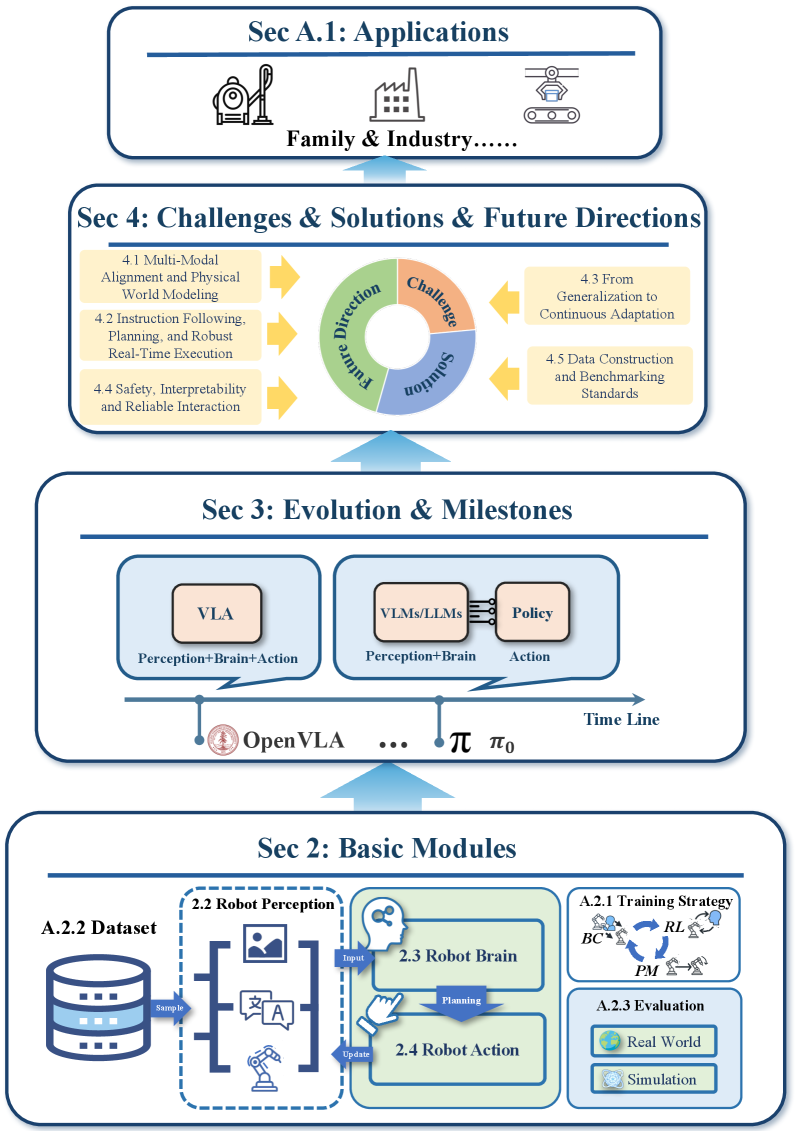
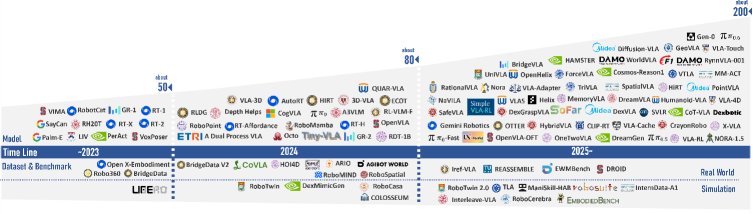
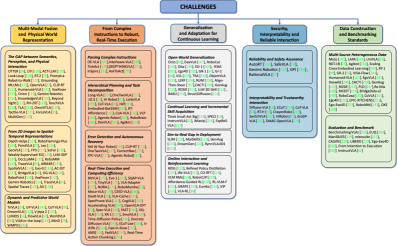
📊 实验亮点
本文是一篇综述性文章,没有具体的实验结果。其亮点在于对VLA模型进行了系统性的分析,总结了现有方法的优缺点,并指出了未来研究方向。通过对表示、执行、泛化、安全以及数据集和评估五个方面的挑战进行深入探讨,为研究人员提供了有价值的参考。
🎯 应用场景
该研究成果可应用于机器人、自动化、智能制造等领域。通过提升机器人对人类指令的理解和执行能力,可以实现更智能、更高效的自动化生产流程。此外,该研究还有助于开发更安全、更可靠的机器人系统,从而在医疗、救援等领域发挥更大的作用。未来的发展方向包括提升模型的泛化能力、安全性以及开发更丰富的数据集。
📄 摘要(原文)
Vision-Language-Action (VLA) models are driving a revolution in robotics, enabling machines to understand instructions and interact with the physical world. This field is exploding with new models and datasets, making it both exciting and challenging to keep pace with. This survey offers a clear and structured guide to the VLA landscape. We design it to follow the natural learning path of a researcher: we start with the basic Modules of any VLA model, trace the history through key Milestones, and then dive deep into the core Challenges that define recent research frontier. Our main contribution is a detailed breakdown of the five biggest challenges in: (1) Representation, (2) Execution, (3) Generalization, (4) Safety, and (5) Dataset and Evaluation. This structure mirrors the developmental roadmap of a generalist agent: establishing the fundamental perception-action loop, scaling capabilities across diverse embodiments and environments, and finally ensuring trustworthy deployment-all supported by the essential data infrastructure. For each of them, we review existing approaches and highlight future opportunities. We position this paper as both a foundational guide for newcomers and a strategic roadmap for experienced researchers, with the dual aim of accelerating learning and inspiring new ideas in embodied intelligence. A live version of this survey, with continuous updates, is maintained on our \href{https://suyuz1.github.io/VLA-Survey-Anatomy/}{project page}.