Seeing to Act, Prompting to Specify: A Bayesian Factorization of Vision Language Action Policy
作者: Kechun Xu, Zhenjie Zhu, Anzhe Chen, Shuqi Zhao, Qing Huang, Yifei Yang, Haojian Lu, Rong Xiong, Masayoshi Tomizuka, Yue Wang
分类: cs.RO, cs.CV
发布日期: 2025-12-12
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出BayesVLA,通过贝叶斯分解解决VLA模型中的模态不平衡和泛化问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作 贝叶斯分解 模态不平衡 泛化能力 机器人操作
📋 核心要点
- VLA模型微调时易发生VLM主干网络的灾难性遗忘,且VLA数据集存在模态不平衡问题,导致模型倾向于视觉捷径。
- 提出BayesVLA,通过贝叶斯分解将策略分解为视觉-动作先验和语言条件似然,从而保留泛化能力并促进指令遵循。
- 实验表明,BayesVLA在未见过的指令、对象和环境方面,相比现有方法具有更强的泛化能力。
📝 摘要(中文)
视觉-语言-动作(VLA)模型中的分布外泛化能力常常受到微调过程中视觉-语言模型(VLM)主干网络灾难性遗忘的阻碍。虽然与外部推理数据进行协同训练有所帮助,但这需要丰富的调优经验和额外的数据开销。除了这些外部依赖性之外,我们还发现了VLA数据集内部的一个内在原因:模态不平衡,即语言多样性远低于视觉和动作多样性。这种不平衡使模型偏向于视觉捷径和语言遗忘。为了解决这个问题,我们引入了BayesVLA,一种贝叶斯分解方法,将策略分解为支持“看即行动”的视觉-动作先验和支持“提示即指定”的语言条件似然。这从根本上保留了泛化能力并促进了指令遵循。我们进一步结合了接触前和接触后阶段,以更好地利用预训练的基础模型。信息论分析正式验证了我们在缓解捷径学习方面的有效性。大量的实验表明,与现有方法相比,该方法在未见过的指令、对象和环境方面具有更强的泛化能力。项目主页:https://xukechun.github.io/papers/BayesVLA。
🔬 方法详解
问题定义:VLA模型在面对分布外数据时泛化能力差,主要原因是微调过程中VLM主干网络发生灾难性遗忘,以及VLA数据集中视觉和动作模态的多样性远高于语言模态,导致模型学习到视觉捷径,忽略语言指令。现有方法通常依赖外部推理数据进行协同训练,但需要耗费大量调优时间和数据成本。
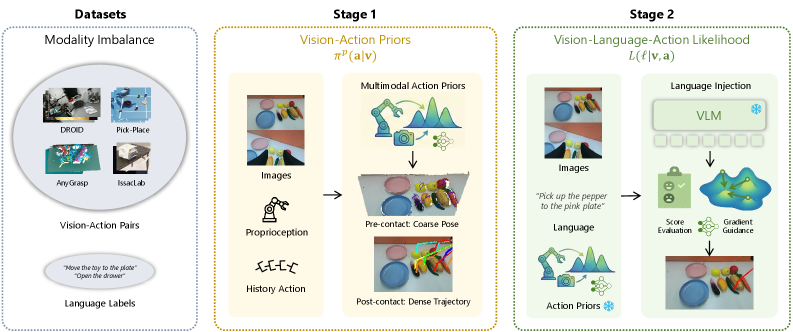
核心思路:BayesVLA的核心思路是将VLA策略分解为两个部分:一个视觉-动作先验,负责根据视觉信息生成动作;另一个语言条件似然,负责根据语言指令调整动作。通过这种分解,模型可以更好地利用视觉信息进行初步决策,并根据语言指令进行精细调整,从而避免过度依赖视觉捷径。
技术框架:BayesVLA的整体架构包含三个主要阶段:预接触阶段、接触阶段和后接触阶段。在预接触阶段,模型利用预训练的视觉模型提取视觉特征。在接触阶段,模型利用贝叶斯分解后的视觉-动作先验和语言条件似然生成动作。在后接触阶段,模型进一步优化动作序列。整个框架利用预训练的基础模型,并通过贝叶斯分解来解耦视觉和语言信息。
关键创新:BayesVLA的关键创新在于其贝叶斯分解方法,它将VLA策略分解为视觉-动作先验和语言条件似然。这种分解方式能够有效缓解模态不平衡问题,并提高模型的泛化能力。此外,该方法还引入了预接触和后接触阶段,以更好地利用预训练的基础模型。
关键设计:BayesVLA的关键设计包括:1) 使用变分推断来学习视觉-动作先验和语言条件似然的参数;2) 使用信息论方法来分析和缓解捷径学习;3) 在预接触和后接触阶段使用Transformer网络来处理视觉特征和动作序列。
🖼️ 关键图片


📊 实验亮点
实验结果表明,BayesVLA在未见过的指令、对象和环境方面,相比现有方法具有显著的泛化能力提升。具体而言,BayesVLA在多个VLA基准测试中取得了state-of-the-art的性能,并且在分布外测试中表现出更强的鲁棒性。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、智能助手等领域,提升智能体在复杂环境下的决策能力和泛化性能。例如,机器人可以根据视觉信息和自然语言指令完成各种任务,自动驾驶系统可以更好地理解驾驶员的意图并做出相应的动作。
📄 摘要(原文)
The pursuit of out-of-distribution generalization in Vision-Language-Action (VLA) models is often hindered by catastrophic forgetting of the Vision-Language Model (VLM) backbone during fine-tuning. While co-training with external reasoning data helps, it requires experienced tuning and data-related overhead. Beyond such external dependencies, we identify an intrinsic cause within VLA datasets: modality imbalance, where language diversity is much lower than visual and action diversity. This imbalance biases the model toward visual shortcuts and language forgetting. To address this, we introduce BayesVLA, a Bayesian factorization that decomposes the policy into a visual-action prior, supporting seeing-to-act, and a language-conditioned likelihood, enabling prompt-to-specify. This inherently preserves generalization and promotes instruction following. We further incorporate pre- and post-contact phases to better leverage pre-trained foundation models. Information-theoretic analysis formally validates our effectiveness in mitigating shortcut learning. Extensive experiments show superior generalization to unseen instructions, objects, and environments compared to existing methods. Project page is available at: https://xukechun.github.io/papers/BayesVLA.